 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtistic Object Recognition by Unsupervised Style Adaptation
Paper and Code
Dec 28, 2018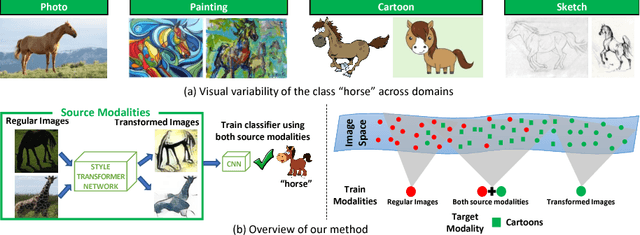
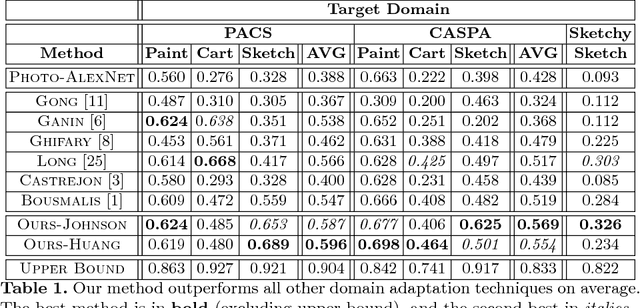
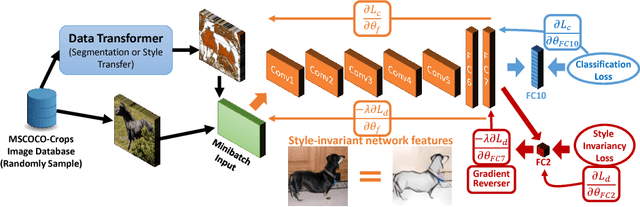
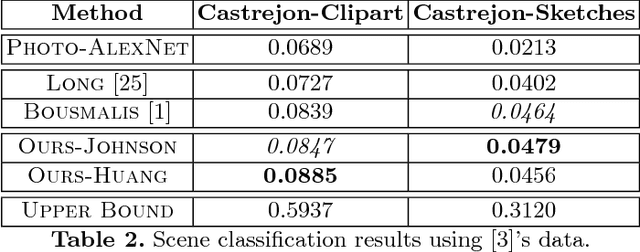
Computer vision systems currently lack the ability to reliably recognize artistically rendered objects, especially when such data is limited. In this paper, we propose a method for recognizing objects in artistic modalities (such as paintings, cartoons, or sketches), without requiring any labeled data from those modalities. Our method explicitly accounts for stylistic domain shifts between and within domains. To do so, we introduce a complementary training modality constructed to be similar in artistic style to the target domain, and enforce that the network learns features that are invariant between the two training modalities. We show how such artificial labeled source domains can be generated automatically through the use of style transfer techniques, using diverse target images to represent the style in the target domain. Unlike existing methods which require a large amount of unlabeled target data, our method can work with as few as ten unlabeled images. We evaluate it on a number of cross-domain object and scene classification tasks and on a new dataset we release. Our experiments show that our approach, though conceptually simple, significantly improves the accuracy that existing domain adaptation techniques obtain for artistic object recognition.