 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022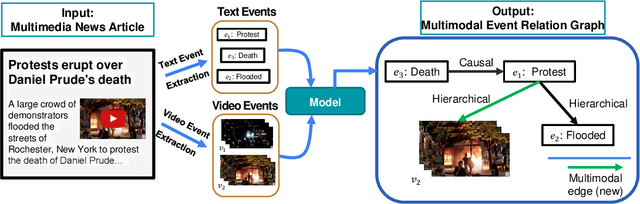
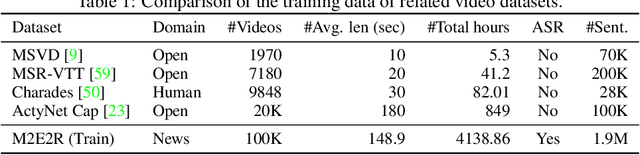
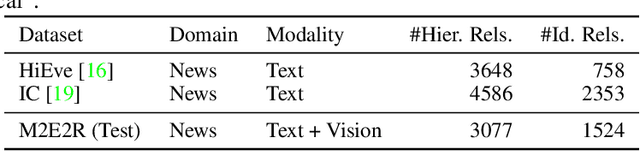

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.
Joint Multimedia Event Extraction from Video and Article
Sep 27, 2021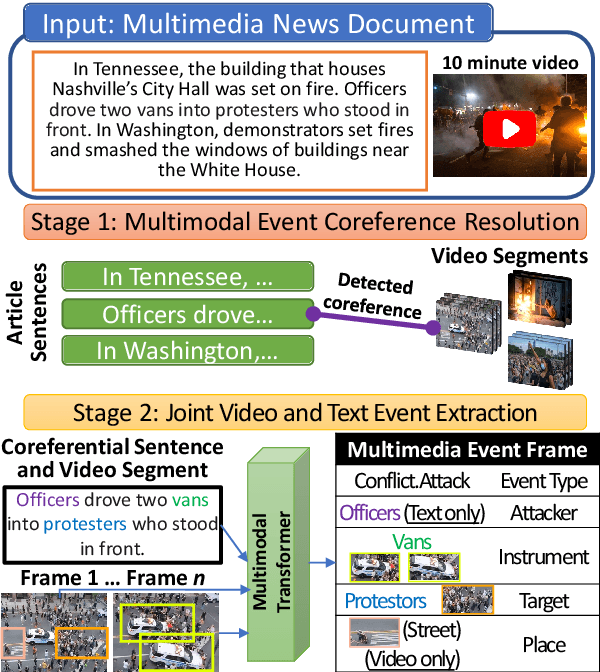
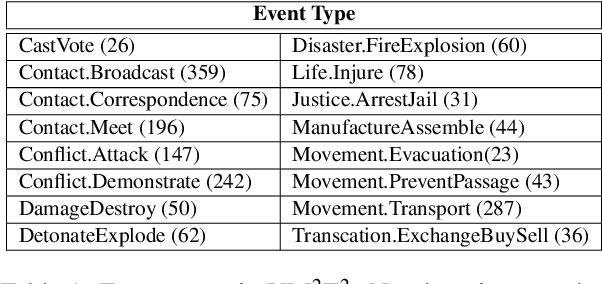


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.