 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Children: Improving Image-Caption Pretraining via Curriculum
May 30, 2023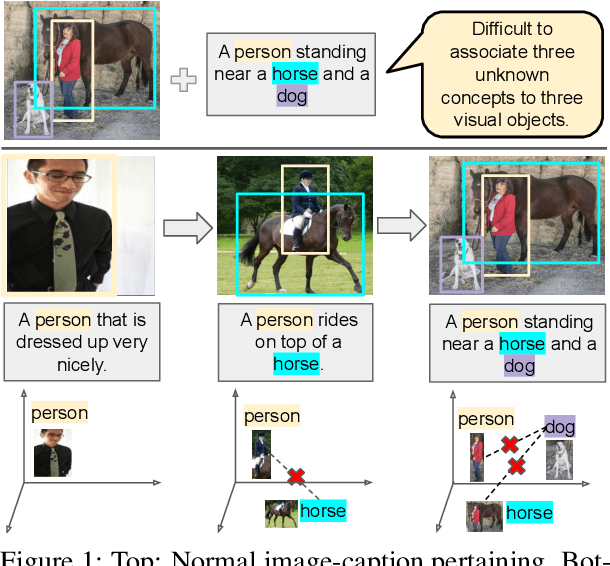
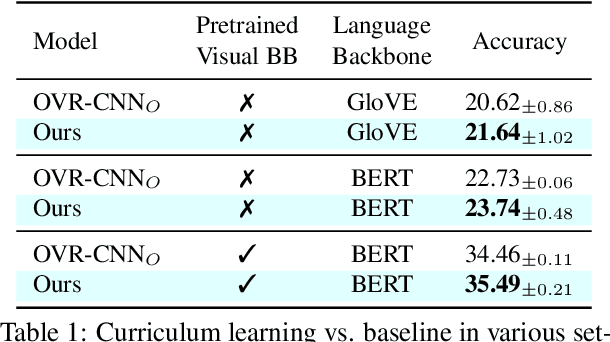
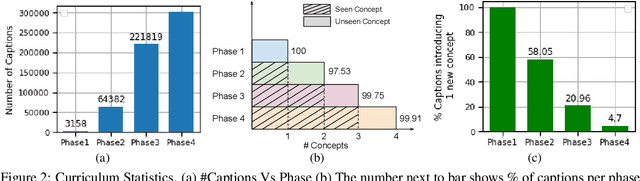

Image-caption pretraining has been quite successfully used for downstream vision tasks like zero-shot image classification and object detection. However, image-caption pretraining is still a hard problem -- it requires multiple concepts (nouns) from captions to be aligned to several objects in images. To tackle this problem, we go to the roots -- the best learner, children. We take inspiration from cognitive science studies dealing with children's language learning to propose a curriculum learning framework. The learning begins with easy-to-align image caption pairs containing one concept per caption. The difficulty is progressively increased with each new phase by adding one more concept per caption. Correspondingly, the knowledge acquired in each learning phase is utilized in subsequent phases to effectively constrain the learning problem to aligning one new concept-object pair in each phase. We show that this learning strategy improves over vanilla image-caption training in various settings -- pretraining from scratch, using a pretrained image or/and pretrained text encoder, low data regime etc.
Multimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022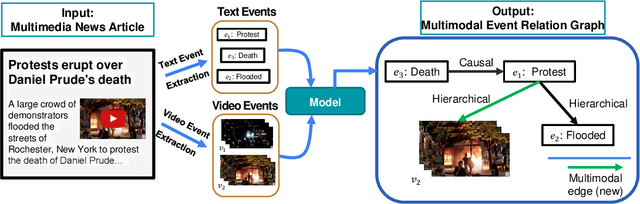
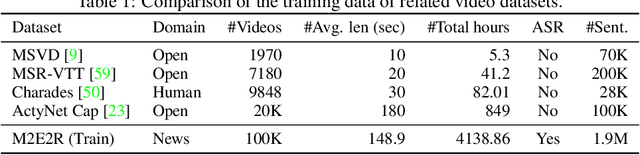
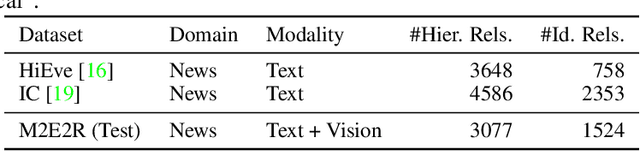

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.