 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMP: Learning Universal Adversarial Perturbations for Multi-Image Tasks via Pre-trained Models
Jan 29, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance across vision-language tasks. Recent advancements allow these models to process multiple images as inputs. However, the vulnerabilities of multi-image MLLMs remain unexplored. Existing adversarial attacks focus on single-image settings and often assume a white-box threat model, which is impractical in many real-world scenarios. This paper introduces LAMP, a black-box method for learning Universal Adversarial Perturbations (UAPs) targeting multi-image MLLMs. LAMP applies an attention-based constraint that prevents the model from effectively aggregating information across images. LAMP also introduces a novel cross-image contagious constraint that forces perturbed tokens to influence clean tokens, spreading adversarial effects without requiring all inputs to be modified. Additionally, an index-attention suppression loss enables a robust position-invariant attack. Experimental results show that LAMP outperforms SOTA baselines and achieves the highest attack success rates across multiple vision-language tasks and models.
Semantic Shield: Defending Vision-Language Models Against Backdooring and Poisoning via Fine-grained Knowledge Alignment
Nov 23, 2024In recent years there has been enormous interest in vision-language models trained using self-supervised objectives. However, the use of large-scale datasets scraped from the web for training also makes these models vulnerable to potential security threats, such as backdooring and poisoning attacks. In this paper, we propose a method for mitigating such attacks on contrastively trained vision-language models. Our approach leverages external knowledge extracted from a language model to prevent models from learning correlations between image regions which lack strong alignment with external knowledge. We do this by imposing constraints to enforce that attention paid by the model to visual regions is proportional to the alignment of those regions with external knowledge. We conduct extensive experiments using a variety of recent backdooring and poisoning attacks on multiple datasets and architectures. Our results clearly demonstrate that our proposed approach is highly effective at defending against such attacks across multiple settings, while maintaining model utility and without requiring any changes at inference time
Towards Interpretable Multilingual Detection of Hate Speech against Immigrants and Women in Twitter at SemEval-2019 Task 5
Nov 26, 2020
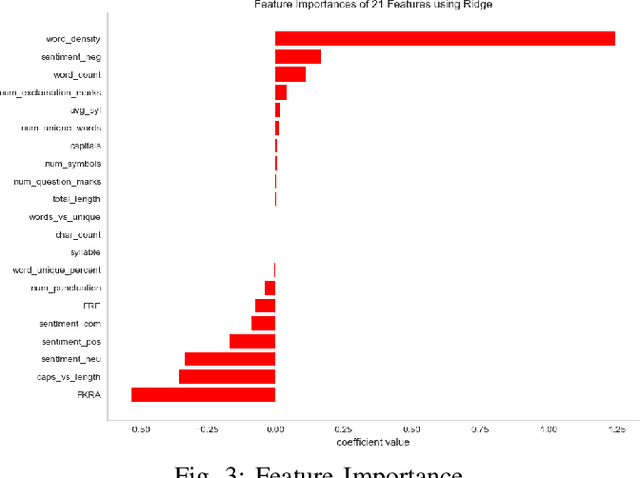
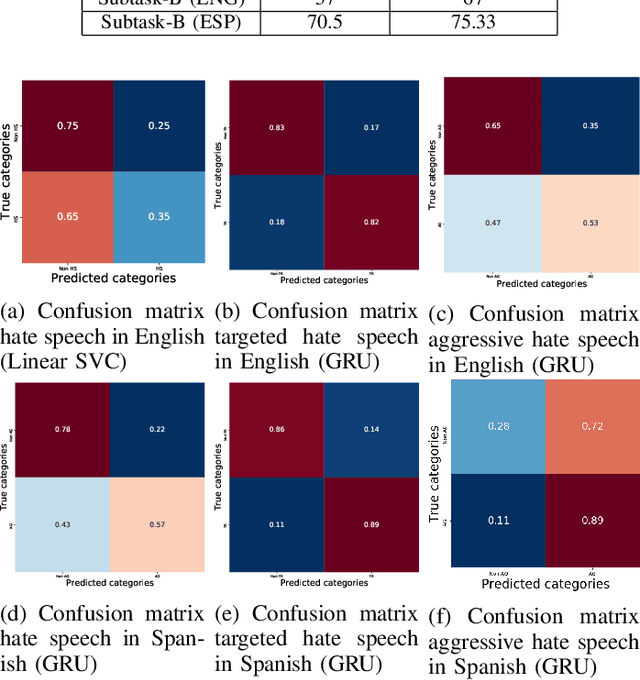
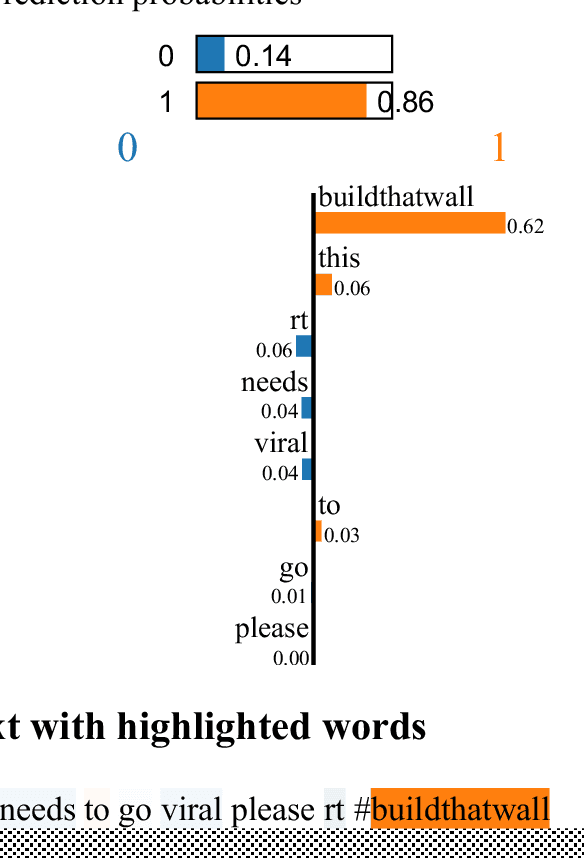
his paper describes our techniques to detect hate speech against women and immigrants on Twitter in multilingual contexts, particularly in English and Spanish. The challenge was designed by SemEval-2019 Task 5, where the participants need to design algorithms to detect hate speech in English and Spanish language with a given target (e.g., women or immigrants). Here, we have developed two deep neural networks (Bidirectional Gated Recurrent Unit (GRU), Character-level Convolutional Neural Network (CNN)), and one machine learning model by exploiting the linguistic features. Our proposed model obtained 57 and 75 F1 scores for Task A in English and Spanish language respectively. For Task B, the F1 scores are 67 for English and 75.33 for Spanish. In the case of task A (Spanish) and task B (both English and Spanish), the F1 scores are improved by 2, 10, and 5 points respectively. Besides, we present visually interpretable models that can address the generalizability issues of the custom-designed machine learning architecture by investigating the annotated dataset.