 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSteerNet: Human Reaction Generation from Videos via Observation-Reaction Mutual Steering
Mar 20, 2026Video-driven human reaction generation aims to synthesize 3D human motions that directly react to observed video sequences, which is crucial for building human-like interactive AI systems. However, existing methods often fail to effectively leverage video inputs to steer human reaction synthesis, resulting in reaction motions that are mismatched with the content of video sequences. We reveal that this limitation arises from a severe relational distortion between visual observations and reaction types. In light of this, we propose MuSteerNet, a simple yet effective framework that generates 3D human reactions from videos via observation-reaction mutual steering. Specifically, we first propose a Prototype Feedback Steering mechanism to mitigate relational distortion by refining visual observations with a gated delta-rectification modulator and a relational margin constraint, guided by prototypical vectors learned from human reactions. We then introduce Dual-Coupled Reaction Refinement that fully leverages rectified visual cues to further steer the refinement of generated reaction motions, thereby effectively improving reaction quality and enabling MuSteerNet to achieve competitive performance. Extensive experiments and ablation studies validate the effectiveness of our method. Code coming soon: https://github.com/zhouyuan888888/MuSteerNet.
Harder Is Better: Boosting Mathematical Reasoning via Difficulty-Aware GRPO and Multi-Aspect Question Reformulation
Jan 28, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a robust mechanism for enhancing mathematical reasoning in large models. However, we identify a systematic lack of emphasis on more challenging questions in existing methods from both algorithmic and data perspectives, despite their importance for refining underdeveloped capabilities. Algorithmically, widely used Group Relative Policy Optimization (GRPO) suffers from an implicit imbalance where the magnitude of policy updates is lower for harder questions. Data-wise, augmentation approaches primarily rephrase questions to enhance diversity without systematically increasing intrinsic difficulty. To address these issues, we propose a two-dual MathForge framework to improve mathematical reasoning by targeting harder questions from both perspectives, which comprises a Difficulty-Aware Group Policy Optimization (DGPO) algorithm and a Multi-Aspect Question Reformulation (MQR) strategy. Specifically, DGPO first rectifies the implicit imbalance in GRPO via difficulty-balanced group advantage estimation, and further prioritizes harder questions by difficulty-aware question-level weighting. Meanwhile, MQR reformulates questions across multiple aspects to increase difficulty while maintaining the original gold answer. Overall, MathForge forms a synergistic loop: MQR expands the data frontier, and DGPO effectively learns from the augmented data. Extensive experiments show that MathForge significantly outperforms existing methods on various mathematical reasoning tasks. The code and augmented data are all available at https://github.com/AMAP-ML/MathForge.
CharacterBox: Evaluating the Role-Playing Capabilities of LLMs in Text-Based Virtual Worlds
Dec 07, 2024



Role-playing is a crucial capability of Large Language Models (LLMs), enabling a wide range of practical applications, including intelligent non-player characters, digital twins, and emotional companions. Evaluating this capability in LLMs is challenging due to the complex dynamics involved in role-playing, such as maintaining character fidelity throughout a storyline and navigating open-ended narratives without a definitive ground truth. Current evaluation methods, which primarily focus on question-answering or conversational snapshots, fall short of adequately capturing the nuanced character traits and behaviors essential for authentic role-playing. In this paper, we propose CharacterBox, which is a simulation sandbox designed to generate situational fine-grained character behavior trajectories. These behavior trajectories enable a more comprehensive and in-depth evaluation of role-playing capabilities. CharacterBox consists of two main components: the character agent and the narrator agent. The character agent, grounded in psychological and behavioral science, exhibits human-like behaviors, while the narrator agent coordinates interactions between character agents and environmental changes. Additionally, we introduce two trajectory-based methods that leverage CharacterBox to enhance LLM performance. To reduce costs and facilitate the adoption of CharacterBox by public communities, we fine-tune two smaller models, CharacterNR and CharacterRM, as substitutes for GPT API calls, and demonstrate their competitive performance compared to advanced GPT APIs.
Awaker2.5-VL: Stably Scaling MLLMs with Parameter-Efficient Mixture of Experts
Nov 16, 2024As the research of Multimodal Large Language Models (MLLMs) becomes popular, an advancing MLLM model is typically required to handle various textual and visual tasks (e.g., VQA, Detection, OCR, and ChartQA) simultaneously for real-world applications. However, due to the significant differences in representation and distribution among data from various tasks, simply mixing data of all tasks together leads to the well-known``multi-task conflict" issue, resulting in performance degradation across various tasks. To address this issue, we propose Awaker2.5-VL, a Mixture of Experts~(MoE) architecture suitable for MLLM, which acquires the multi-task capabilities through multiple sparsely activated experts. To speed up the training and inference of Awaker2.5-VL, each expert in our model is devised as a low-rank adaptation (LoRA) structure. Extensive experiments on multiple latest benchmarks demonstrate the effectiveness of Awaker2.5-VL. The code and model weight are released in our Project Page: https://github.com/MetabrainAGI/Awaker.
MMRole: A Comprehensive Framework for Developing and Evaluating Multimodal Role-Playing Agents
Aug 08, 2024



Recently, Role-Playing Agents (RPAs) have garnered increasing attention for their potential to deliver emotional value and facilitate sociological research. However, existing studies are primarily confined to the textual modality, unable to simulate humans' multimodal perceptual capabilities. To bridge this gap, we introduce the concept of Multimodal Role-Playing Agents (MRPAs), and propose a comprehensive framework, MMRole, for their development and evaluation, which comprises a personalized multimodal dataset and a robust evaluation method. Specifically, we construct a large-scale, high-quality dataset, MMRole-Data, consisting of 85 characters, 11K images, and 14K single or multi-turn dialogues. Additionally, we present a robust evaluation method, MMRole-Eval, encompassing eight metrics across three dimensions, where a reward model is trained to score MRPAs with the constructed ground-truth data for comparison. Moreover, we develop the first specialized MRPA, MMRole-Agent. Extensive evaluation results demonstrate the improved performance of MMRole-Agent and highlight the primary challenges in developing MRPAs, emphasizing the need for enhanced multimodal understanding and role-playing consistency. The data, code, and models will be available at https://github.com/YanqiDai/MMRole.
CoTBal: Comprehensive Task Balancing for Multi-Task Visual Instruction Tuning
Mar 07, 2024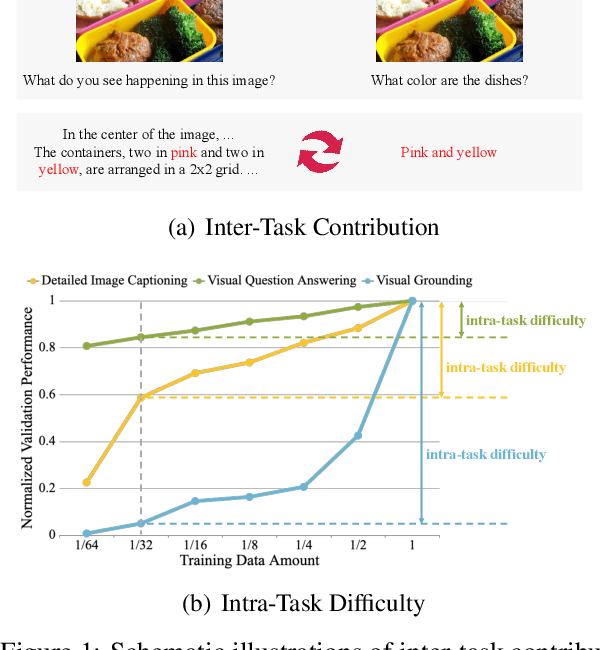



Visual instruction tuning is a key training stage of large multimodal models (LMMs). Nevertheless, the common practice of indiscriminately mixing instruction-following data from various tasks may result in suboptimal overall performance due to different instruction formats and knowledge domains across tasks. To mitigate this issue, we propose a novel Comprehensive Task Balancing (CoTBal) algorithm for multi-task visual instruction tuning of LMMs. To our knowledge, this is the first work that explores multi-task optimization in visual instruction tuning. Specifically, we consider two key dimensions for task balancing: (1) Inter-Task Contribution, the phenomenon where learning one task potentially enhances the performance in other tasks, attributable to the overlapping knowledge domains, and (2) Intra-Task Difficulty, which refers to the learning difficulty within a single task. By quantifying these two dimensions with performance-based metrics, task balancing is thus enabled by assigning more weights to tasks that offer substantial contributions to others, receive minimal contributions from others, and also have great intra-task difficulties. Experiments show that our CoTBal leads to superior overall performance in multi-task visual instruction tuning.
Improvable Gap Balancing for Multi-Task Learning
Jul 28, 2023In multi-task learning (MTL), gradient balancing has recently attracted more research interest than loss balancing since it often leads to better performance. However, loss balancing is much more efficient than gradient balancing, and thus it is still worth further exploration in MTL. Note that prior studies typically ignore that there exist varying improvable gaps across multiple tasks, where the improvable gap per task is defined as the distance between the current training progress and desired final training progress. Therefore, after loss balancing, the performance imbalance still arises in many cases. In this paper, following the loss balancing framework, we propose two novel improvable gap balancing (IGB) algorithms for MTL: one takes a simple heuristic, and the other (for the first time) deploys deep reinforcement learning for MTL. Particularly, instead of directly balancing the losses in MTL, both algorithms choose to dynamically assign task weights for improvable gap balancing. Moreover, we combine IGB and gradient balancing to show the complementarity between the two types of algorithms. Extensive experiments on two benchmark datasets demonstrate that our IGB algorithms lead to the best results in MTL via loss balancing and achieve further improvements when combined with gradient balancing. Code is available at https://github.com/YanqiDai/IGB4MTL.