 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Vision-Language Model Inference with Causality-pruning Knowledge Prompt
Paper and Code
May 23, 2022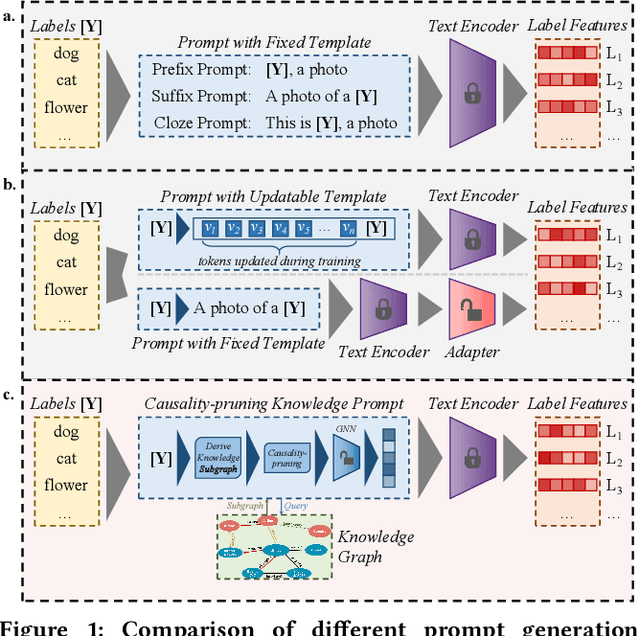
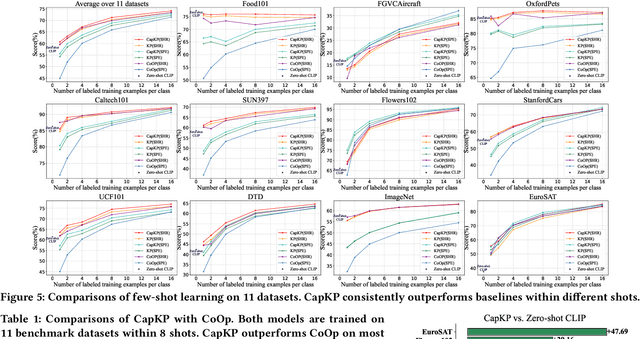
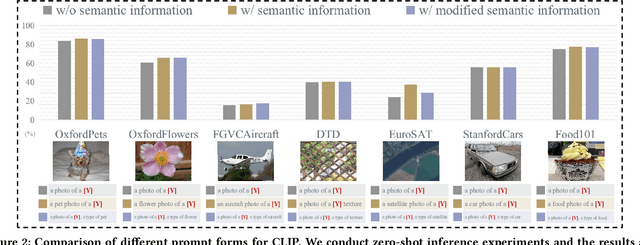
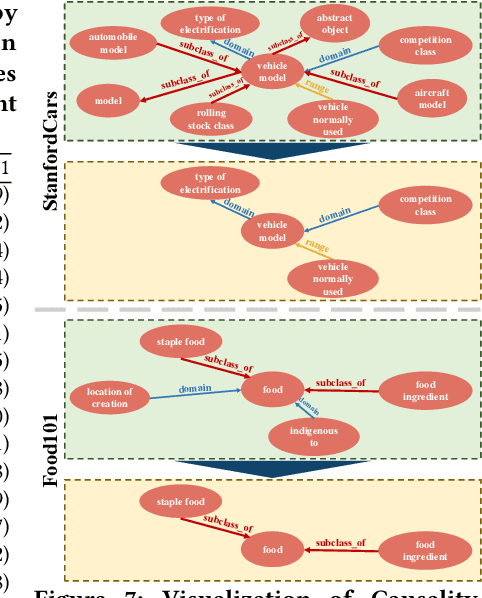
Vision-language models are pre-trained by aligning image-text pairs in a common space so that the models can deal with open-set visual concepts by learning semantic information from textual labels. To boost the transferability of these models on downstream tasks in a zero-shot manner, recent works explore generating fixed or learnable prompts, i.e., classification weights are synthesized from natural language describing task-relevant categories, to reduce the gap between tasks in the training and test phases. However, how and what prompts can improve inference performance remains unclear. In this paper, we explicitly provide exploration and clarify the importance of including semantic information in prompts, while existing prompt methods generate prompts without exploring the semantic information of textual labels. A challenging issue is that manually constructing prompts, with rich semantic information, requires domain expertise and is extremely time-consuming. To this end, we propose Causality-pruning Knowledge Prompt (CapKP) for adapting pre-trained vision-language models to downstream image recognition. CapKP retrieves an ontological knowledge graph by treating the textual label as a query to explore task-relevant semantic information. To further refine the derived semantic information, CapKP introduces causality-pruning by following the first principle of Granger causality. Empirically, we conduct extensive evaluations to demonstrate the effectiveness of CapKP, e.g., with 8 shots, CapKP outperforms the manual-prompt method by 12.51% and the learnable-prompt method by 1.39% on average, respectively. Experimental analyses prove the superiority of CapKP in domain generalization compared to benchmark approaches.