 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Freeform Handwriting Authentication with Energy-oriented Self-Supervised Learning
Aug 19, 2024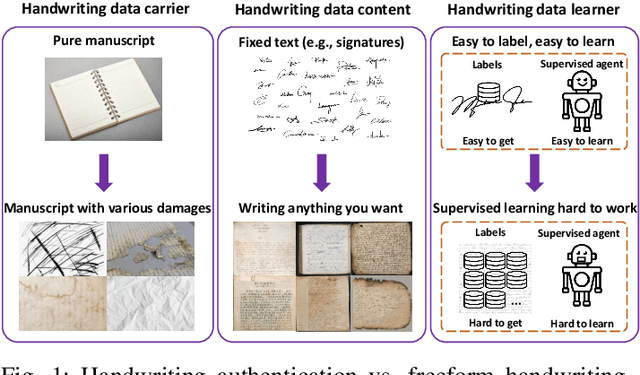
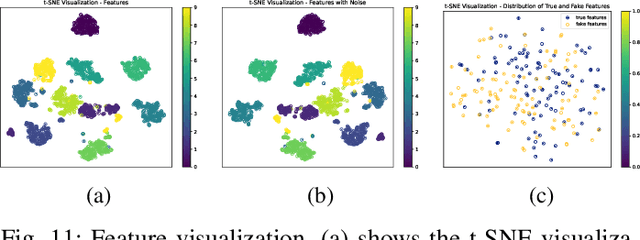

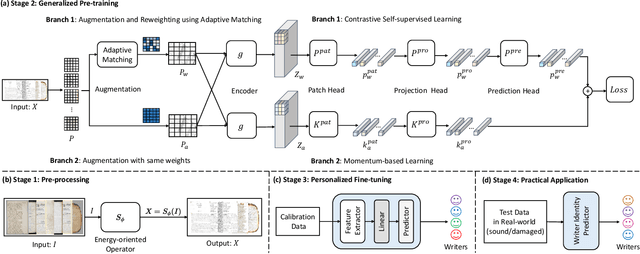
Freeform handwriting authentication verifies a person's identity from their writing style and habits in messy handwriting data. This technique has gained widespread attention in recent years as a valuable tool for various fields, e.g., fraud prevention and cultural heritage protection. However, it still remains a challenging task in reality due to three reasons: (i) severe damage, (ii) complex high-dimensional features, and (iii) lack of supervision. To address these issues, we propose SherlockNet, an energy-oriented two-branch contrastive self-supervised learning framework for robust and fast freeform handwriting authentication. It consists of four stages: (i) pre-processing: converting manuscripts into energy distributions using a novel plug-and-play energy-oriented operator to eliminate the influence of noise; (ii) generalized pre-training: learning general representation through two-branch momentum-based adaptive contrastive learning with the energy distributions, which handles the high-dimensional features and spatial dependencies of handwriting; (iii) personalized fine-tuning: calibrating the learned knowledge using a small amount of labeled data from downstream tasks; and (iv) practical application: identifying individual handwriting from scrambled, missing, or forged data efficiently and conveniently. Considering the practicality, we construct EN-HA, a novel dataset that simulates data forgery and severe damage in real applications. Finally, we conduct extensive experiments on six benchmark datasets including our EN-HA, and the results prove the robustness and efficiency of SherlockNet.
CSSL-RHA: Contrastive Self-Supervised Learning for Robust Handwriting Authentication
Jul 18, 2023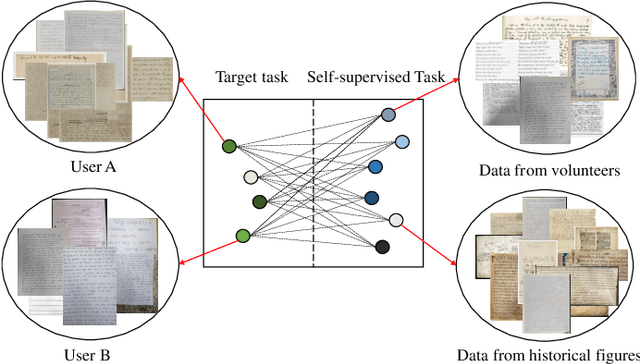
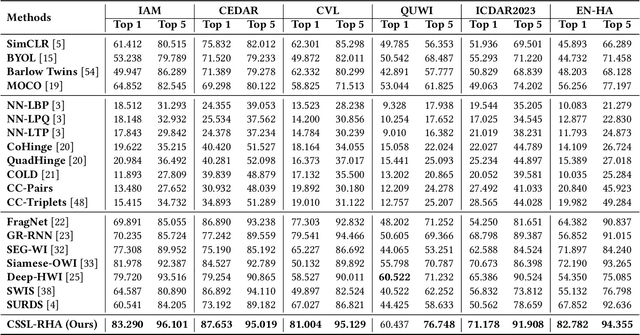


Handwriting authentication is a valuable tool used in various fields, such as fraud prevention and cultural heritage protection. However, it remains a challenging task due to the complex features, severe damage, and lack of supervision. In this paper, we propose a novel Contrastive Self-Supervised Learning framework for Robust Handwriting Authentication (CSSL-RHA) to address these issues. It can dynamically learn complex yet important features and accurately predict writer identities. Specifically, to remove the negative effects of imperfections and redundancy, we design an information-theoretic filter for pre-processing and propose a novel adaptive matching scheme to represent images as patches of local regions dominated by more important features. Through online optimization at inference time, the most informative patch embeddings are identified as the "most important" elements. Furthermore, we employ contrastive self-supervised training with a momentum-based paradigm to learn more general statistical structures of handwritten data without supervision. We conduct extensive experiments on five benchmark datasets and our manually annotated dataset EN-HA, which demonstrate the superiority of our CSSL-RHA compared to baselines. Additionally, we show that our proposed model can still effectively achieve authentication even under abnormal circumstances, such as data falsification and corruption.
Pathological Visual Question Answering
Oct 06, 2020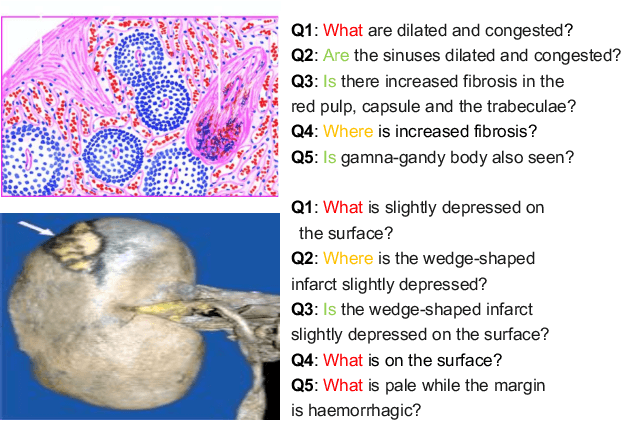
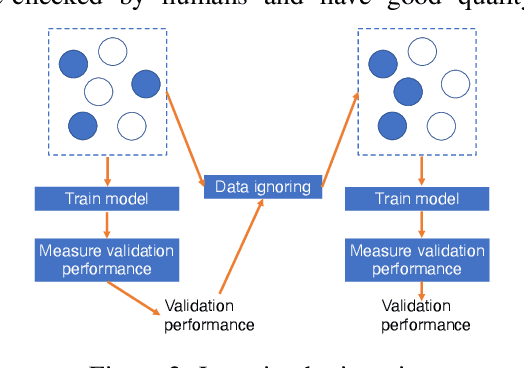
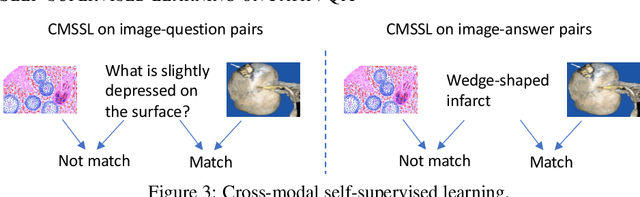
Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology (ABP)? To build such a system, three challenges need to be addressed. First, we need to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Due to privacy concerns, pathology images are usually not publicly available. Besides, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. The second challenge is: since it is difficult to hire highly experienced pathologists to create pathology visual questions and answers, the resulting pathology VQA dataset may contain errors. Training pathology VQA models using these noisy or even erroneous data will lead to problematic models that cannot generalize well on unseen images. The third challenge is: the medical concepts and knowledge covered in pathology question-answer (QA) pairs are very diverse while the number of QA pairs available for modeling training is limited. How to learn effective representations of diverse medical concepts based on limited data is technically demanding. In this paper, we aim to address these three challenges. To our best knowledge, our work represents the first one addressing the pathology VQA problem. To deal with the issue that a publicly available pathology VQA dataset is lacking, we create PathVQA dataset. To address the second challenge, we propose a learning-by-ignoring approach. To address the third challenge, we propose to use cross-modal self-supervised learning. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed learning-by-ignoring method and cross-modal self-supervised learning methods.
TreeGAN: Incorporating Class Hierarchy into Image Generation
Sep 16, 2020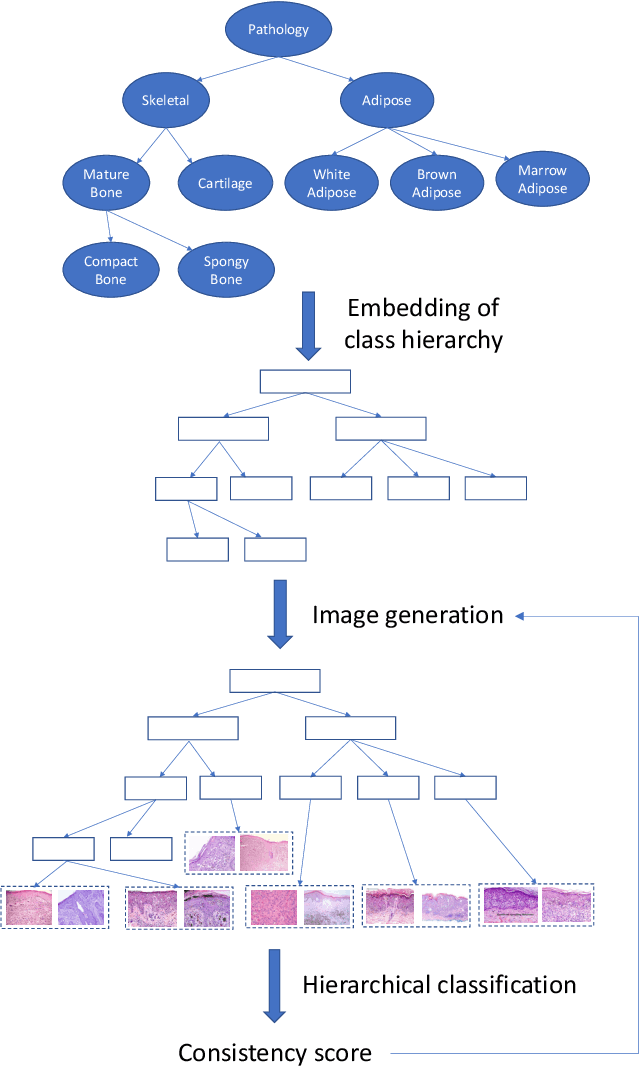
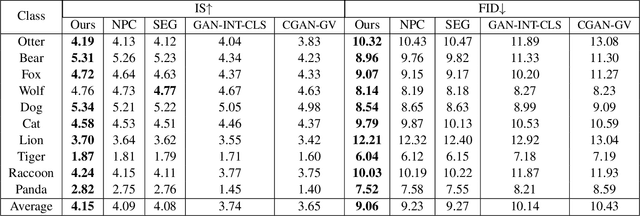
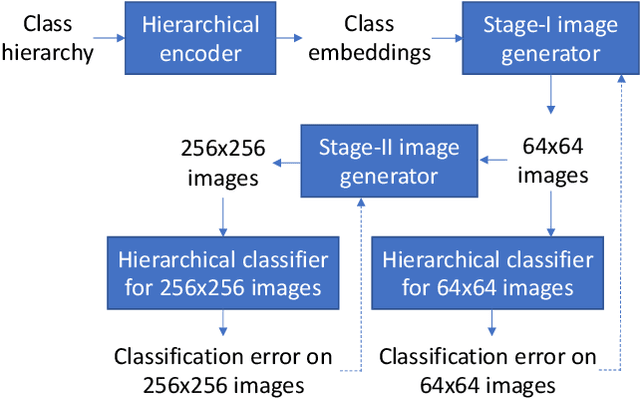
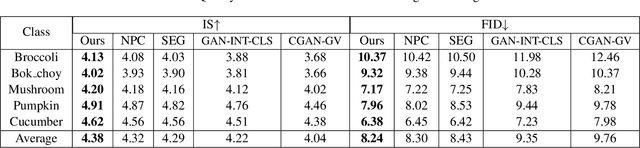
Conditional image generation (CIG) is a widely studied problem in computer vision and machine learning. Given a class, CIG takes the name of this class as input and generates a set of images that belong to this class. In existing CIG works, for different classes, their corresponding images are generated independently, without considering the relationship among classes. In real-world applications, the classes are organized into a hierarchy and their hierarchical relationships are informative for generating high-fidelity images. In this paper, we aim to leverage the class hierarchy for conditional image generation. We propose two ways of incorporating class hierarchy: prior control and post constraint. In prior control, we first encode the class hierarchy, then feed it as a prior into the conditional generator to generate images. In post constraint, after the images are generated, we measure their consistency with the class hierarchy and use the consistency score to guide the training of the generator. Based on these two ideas, we propose a TreeGAN model which consists of three modules: (1) a class hierarchy encoder (CHE) which takes the hierarchical structure of classes and their textual names as inputs and learns an embedding for each class; the embedding captures the hierarchical relationship among classes; (2) a conditional image generator (CIG) which takes the CHE-generated embedding of a class as input and generates a set of images belonging to this class; (3) a consistency checker which performs hierarchical classification on the generated images and checks whether the generated images are compatible with the class hierarchy; the consistency score is used to guide the CIG to generate hierarchy-compatible images. Experiments on various datasets demonstrate the effectiveness of our method.
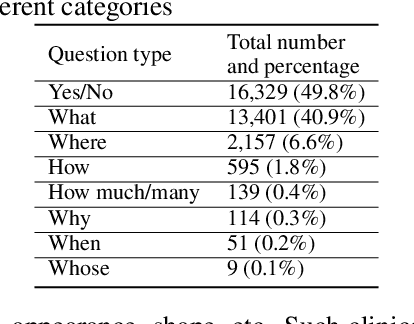
PathVQA: 30000+ Questions for Medical Visual Question Answering
Mar 07, 2020
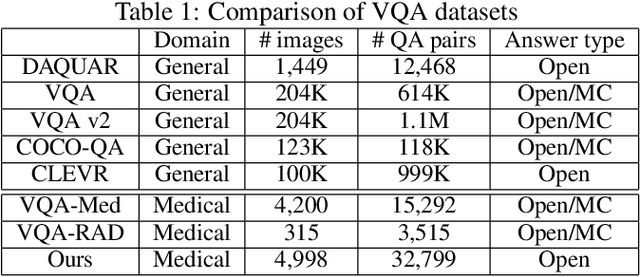
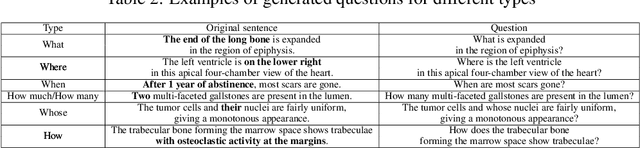

Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology? To achieve this goal, the first step is to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Our work makes the first attempt to build such a dataset. Different from creating general-domain VQA datasets where the images are widely accessible and there are many crowdsourcing workers available and capable of generating question-answer pairs, developing a medical VQA dataset is much more challenging. First, due to privacy concerns, pathology images are usually not publicly available. Second, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. To address these challenges, we resort to pathology textbooks and online digital libraries. We develop a semi-automated pipeline to extract pathology images and captions from textbooks and generate question-answer pairs from captions using natural language processing. We collect 32,799 open-ended questions from 4,998 pathology images where each question is manually checked to ensure correctness. To our best knowledge, this is the first dataset for pathology VQA. Our dataset will be released publicly to promote research in medical VQA.