 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMSA-Net: Causal Multi-scale Aggregation with Adaptive Multi-source Reference for Video Polyp Segmentation
Feb 26, 2026Video polyp segmentation (VPS) is an important task in computer-aided colonoscopy, as it helps doctors accurately locate and track polyps during examinations. However, VPS remains challenging because polyps often look similar to surrounding mucosa, leading to weak semantic discrimination. In addition, large changes in polyp position and scale across video frames make stable and accurate segmentation difficult. To address these challenges, we propose a robust VPS framework named CMSA-Net. The proposed network introduces a Causal Multi-scale Aggregation (CMA) module to effectively gather semantic information from multiple historical frames at different scales. By using causal attention, CMA ensures that temporal feature propagation follows strict time order, which helps reduce noise and improve feature reliability. Furthermore, we design a Dynamic Multi-source Reference (DMR) strategy that adaptively selects informative and reliable reference frames based on semantic separability and prediction confidence. This strategy provides strong multi-frame guidance while keeping the model efficient for real-time inference. Extensive experiments on the SUN-SEG dataset demonstrate that CMSA-Net achieves state-of-the-art performance, offering a favorable balance between segmentation accuracy and real-time clinical applicability.
DevPiolt: Operation Recommendation for IoT Devices at Xiaomi Home
Nov 18, 2025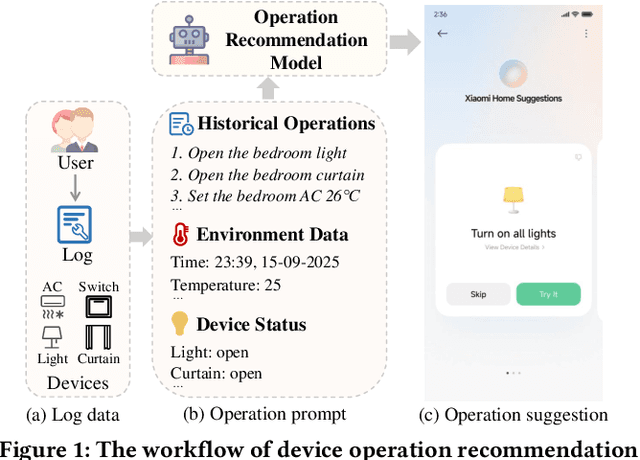
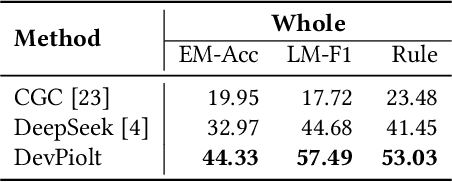
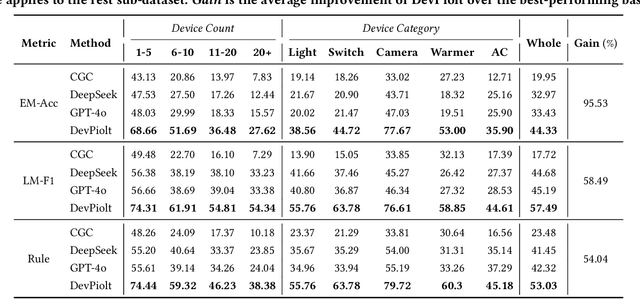
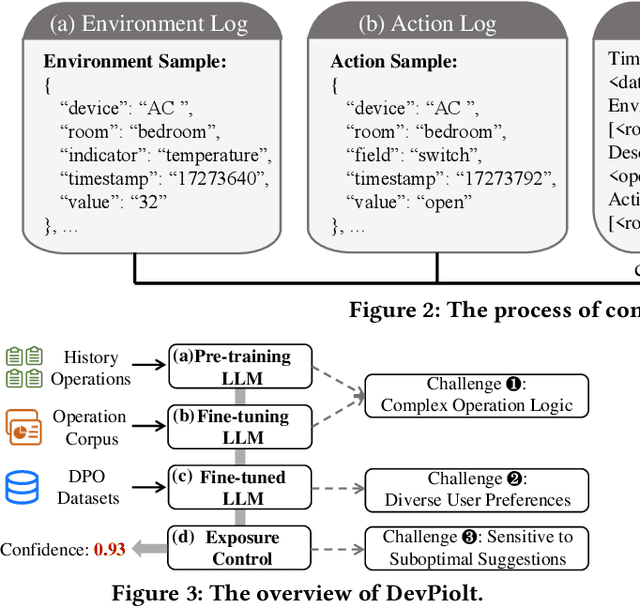
Operation recommendation for IoT devices refers to generating personalized device operations for users based on their context, such as historical operations, environment information, and device status. This task is crucial for enhancing user satisfaction and corporate profits. Existing recommendation models struggle with complex operation logic, diverse user preferences, and sensitive to suboptimal suggestions, limiting their applicability to IoT device operations. To address these issues, we propose DevPiolt, a LLM-based recommendation model for IoT device operations. Specifically, we first equip the LLM with fundamental domain knowledge of IoT operations via continual pre-training and multi-task fine-tuning. Then, we employ direct preference optimization to align the fine-tuned LLM with specific user preferences. Finally, we design a confidence-based exposure control mechanism to avoid negative user experiences from low-quality recommendations. Extensive experiments show that DevPiolt significantly outperforms baselines on all datasets, with an average improvement of 69.5% across all metrics. DevPiolt has been practically deployed in Xiaomi Home app for one quarter, providing daily operation recommendations to 255,000 users. Online experiment results indicate a 21.6% increase in unique visitor device coverage and a 29.1% increase in page view acceptance rates.
From Theory to Application: Fine-Tuning Large EEG Model with Real-World Stress Data
May 29, 2025



Recent advancements in Large Language Models have inspired the development of foundation models across various domains. In this study, we evaluate the efficacy of Large EEG Models (LEMs) by fine-tuning LaBraM, a state-of-the-art foundation EEG model, on a real-world stress classification dataset collected in a graduate classroom. Unlike previous studies that primarily evaluate LEMs using data from controlled clinical settings, our work assesses their applicability to real-world environments. We train a binary classifier that distinguishes between normal and elevated stress states using resting-state EEG data recorded from 18 graduate students during a class session. The best-performing fine-tuned model achieves a balanced accuracy of 90.47% with a 5-second window, significantly outperforming traditional stress classifiers in both accuracy and inference efficiency. We further evaluate the robustness of the fine-tuned LEM under random data shuffling and reduced channel counts. These results demonstrate the capability of LEMs to effectively process real-world EEG data and highlight their potential to revolutionize brain-computer interface applications by shifting the focus from model-centric to data-centric design.
Enhanced MRI Representation via Cross-series Masking
Dec 10, 2024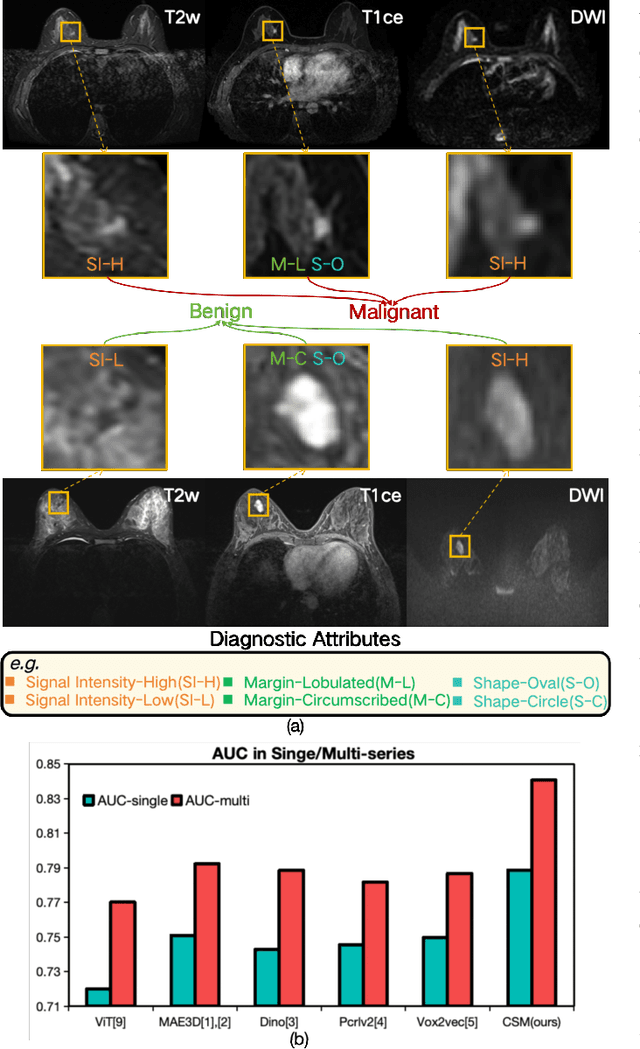
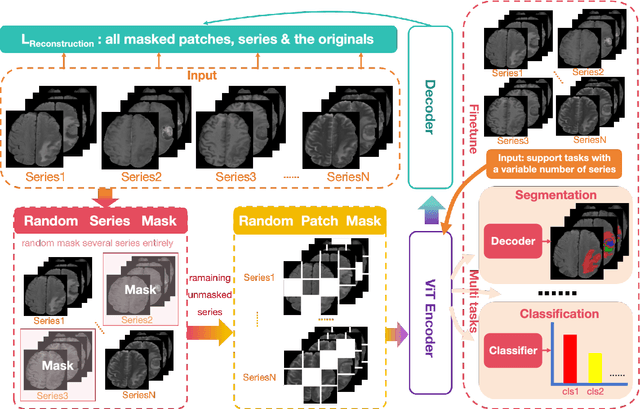
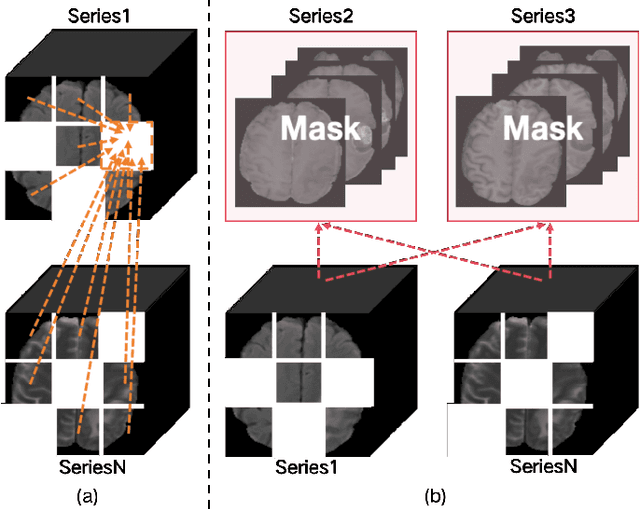
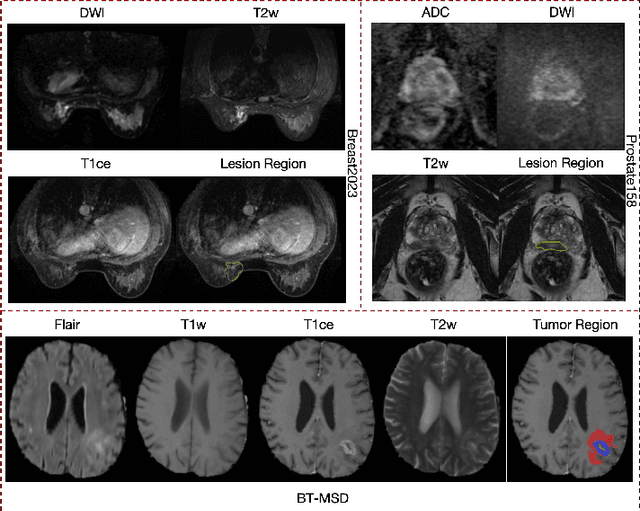
Magnetic resonance imaging (MRI) is indispensable for diagnosing and planning treatment in various medical conditions due to its ability to produce multi-series images that reveal different tissue characteristics. However, integrating these diverse series to form a coherent analysis presents significant challenges, such as differing spatial resolutions and contrast patterns meanwhile requiring extensive annotated data, which is scarce in clinical practice. Due to these issues, we introduce a novel Cross-Series Masking (CSM) Strategy for effectively learning MRI representation in a self-supervised manner. Specifically, CSM commences by randomly sampling a subset of regions and series, which are then strategically masked. In the training process, the cross-series representation is learned by utilizing the unmasked data to reconstruct the masked portions. This process not only integrates information across different series but also facilitates the ability to model both intra-series and inter-series correlations and complementarities. With the learned representation, the downstream tasks like segmentation and classification are also enhanced. Taking brain tissue segmentation, breast tumor benign/malignant classification, and prostate cancer diagnosis as examples, our method achieves state-of-the-art performance on both public and in-house datasets.
Neural Signal Operated Intelligent Robot: Human-guided Robot Maze Navigation through SSVEP
Oct 08, 2024Brain-computer Interface (BCI) applications based on steady-state visual evoked potentials (SSVEP) have the advantages of being fast, accurate and mobile. SSVEP is the EEG response evoked by visual stimuli that are presented at a specific frequency, which results in an increase in the EEG at that same frequency. In this paper, we proposed a novel human-guided maze solving robot navigation system based on SSVEP. By integrating human's intelligence which sees the entirety of the maze, maze solving time could be significantly reduced. Our methods involve training an offline SSVEP classification model, implementing the robot self-navigation algorithm, and finally deploy the model online for real-time robot operation. Our results demonstrated such system to be feasible, and it has the potential to impact the life of many elderly people by helping them carrying out simple daily tasks at home with just the look of their eyes.
Autoregressive Sequence Modeling for 3D Medical Image Representation
Sep 13, 2024



Three-dimensional (3D) medical images, such as Computed Tomography (CT) and Magnetic Resonance Imaging (MRI), are essential for clinical applications. However, the need for diverse and comprehensive representations is particularly pronounced when considering the variability across different organs, diagnostic tasks, and imaging modalities. How to effectively interpret the intricate contextual information and extract meaningful insights from these images remains an open challenge to the community. While current self-supervised learning methods have shown potential, they often consider an image as a whole thereby overlooking the extensive, complex relationships among local regions from one or multiple images. In this work, we introduce a pioneering method for learning 3D medical image representations through an autoregressive pre-training framework. Our approach sequences various 3D medical images based on spatial, contrast, and semantic correlations, treating them as interconnected visual tokens within a token sequence. By employing an autoregressive sequence modeling task, we predict the next visual token in the sequence, which allows our model to deeply understand and integrate the contextual information inherent in 3D medical images. Additionally, we implement a random startup strategy to avoid overestimating token relationships and to enhance the robustness of learning. The effectiveness of our approach is demonstrated by the superior performance over others on nine downstream tasks in public datasets.
Cross-Dimensional Medical Self-Supervised Representation Learning Based on a Pseudo-3D Transformation
Jun 03, 2024



Medical image analysis suffers from a shortage of data, whether annotated or not. This becomes even more pronounced when it comes to 3D medical images. Self-Supervised Learning (SSL) can partially ease this situation by using unlabeled data. However, most existing SSL methods can only make use of data in a single dimensionality (e.g. 2D or 3D), and are incapable of enlarging the training dataset by using data with differing dimensionalities jointly. In this paper, we propose a new cross-dimensional SSL framework based on a pseudo-3D transformation (CDSSL-P3D), that can leverage both 2D and 3D data for joint pre-training. Specifically, we introduce an image transformation based on the im2col algorithm, which converts 2D images into a format consistent with 3D data. This transformation enables seamless integration of 2D and 3D data, and facilitates cross-dimensional self-supervised learning for 3D medical image analysis. We run extensive experiments on 13 downstream tasks, including 2D and 3D classification and segmentation. The results indicate that our CDSSL-P3D achieves superior performance, outperforming other advanced SSL methods.
Act Like a Radiologist: Towards Reliable Multi-view Correspondence Reasoning for Mammogram Mass Detection
May 21, 2021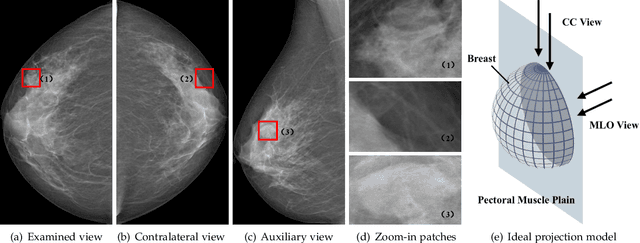

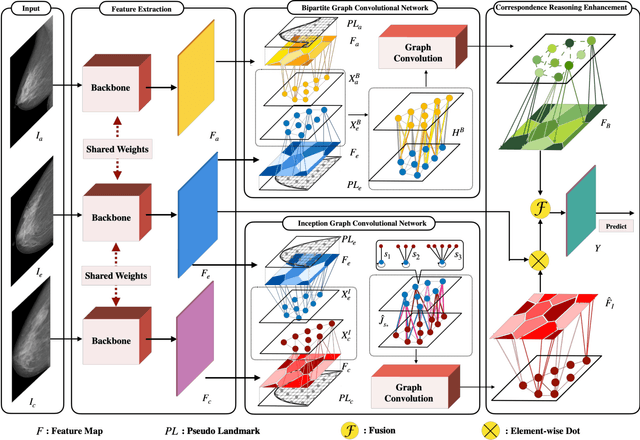
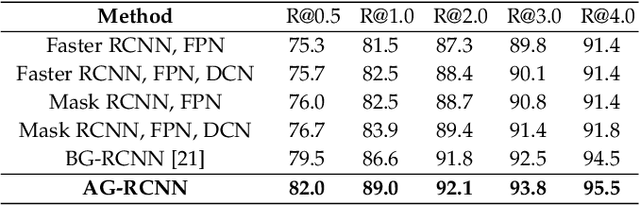
Mammogram mass detection is crucial for diagnosing and preventing the breast cancers in clinical practice. The complementary effect of multi-view mammogram images provides valuable information about the breast anatomical prior structure and is of great significance in digital mammography interpretation. However, unlike radiologists who can utilize the natural reasoning ability to identify masses based on multiple mammographic views, how to endow the existing object detection models with the capability of multi-view reasoning is vital for decision-making in clinical diagnosis but remains the boundary to explore. In this paper, we propose an Anatomy-aware Graph convolutional Network (AGN), which is tailored for mammogram mass detection and endows existing detection methods with multi-view reasoning ability. The proposed AGN consists of three steps. Firstly, we introduce a Bipartite Graph convolutional Network (BGN) to model the intrinsic geometric and semantic relations of ipsilateral views. Secondly, considering that the visual asymmetry of bilateral views is widely adopted in clinical practice to assist the diagnosis of breast lesions, we propose an Inception Graph convolutional Network (IGN) to model the structural similarities of bilateral views. Finally, based on the constructed graphs, the multi-view information is propagated through nodes methodically, which equips the features learned from the examined view with multi-view reasoning ability. Experiments on two standard benchmarks reveal that AGN significantly exceeds the state-of-the-art performance. Visualization results show that AGN provides interpretable visual cues for clinical diagnosis.
Object Instance Mining for Weakly Supervised Object Detection
Feb 04, 2020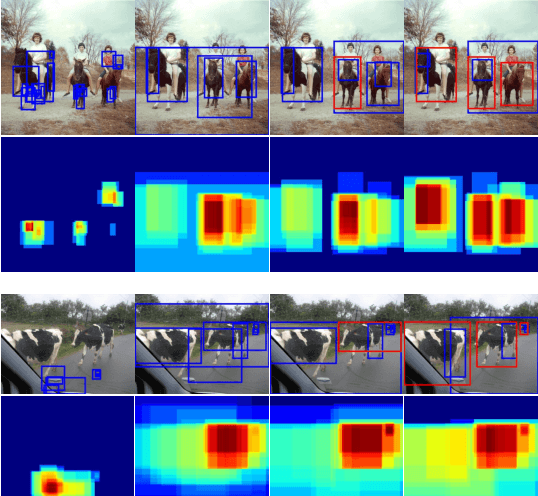
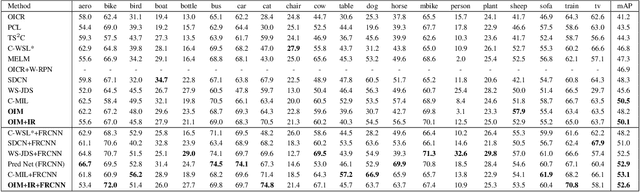
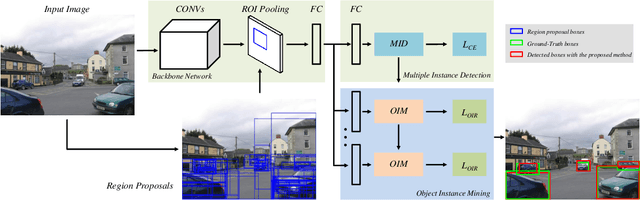
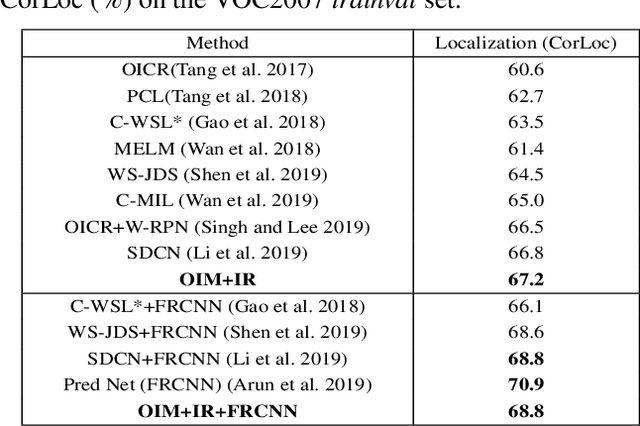
Weakly supervised object detection (WSOD) using only image-level annotations has attracted growing attention over the past few years. Existing approaches using multiple instance learning easily fall into local optima, because such mechanism tends to learn from the most discriminative object in an image for each category. Therefore, these methods suffer from missing object instances which degrade the performance of WSOD. To address this problem, this paper introduces an end-to-end object instance mining (OIM) framework for weakly supervised object detection. OIM attempts to detect all possible object instances existing in each image by introducing information propagation on the spatial and appearance graphs, without any additional annotations. During the iterative learning process, the less discriminative object instances from the same class can be gradually detected and utilized for training. In addition, we design an object instance reweighted loss to learn larger portion of each object instance to further improve the performance. The experimental results on two publicly available databases, VOC 2007 and 2012, demonstrate the efficacy of proposed approach.