 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemeGraphs: Linking Memes to Knowledge Graphs
May 28, 2023Memes are a popular form of communicating trends and ideas in social media and on the internet in general, combining the modalities of images and text. They can express humor and sarcasm but can also have offensive content. Analyzing and classifying memes automatically is challenging since their interpretation relies on the understanding of visual elements, language, and background knowledge. Thus, it is important to meaningfully represent these sources and the interaction between them in order to classify a meme as a whole. In this work, we propose to use scene graphs, that express images in terms of objects and their visual relations, and knowledge graphs as structured representations for meme classification with a Transformer-based architecture. We compare our approach with ImgBERT, a multimodal model that uses only learned (instead of structured) representations of the meme, and observe consistent improvements. We further provide a dataset with human graph annotations that we compare to automatically generated graphs and entity linking. Analysis shows that automatic methods link more entities than human annotators and that automatically generated graphs are better suited for hatefulness classification in memes.
Improving Visual Reasoning by Exploiting The Knowledge in Texts
Feb 09, 2021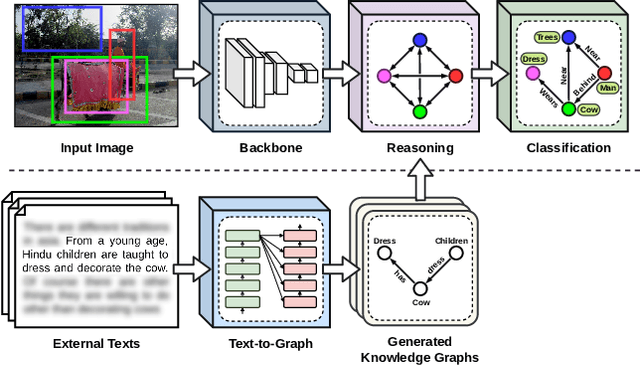

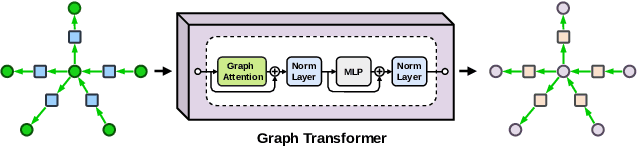
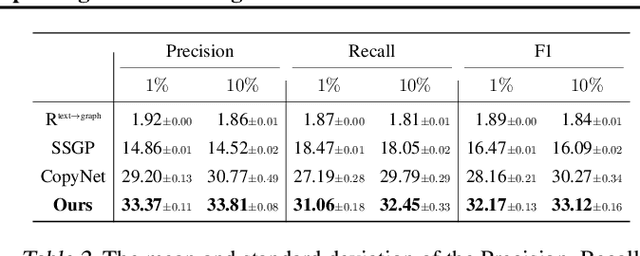
This paper presents a new framework for training image-based classifiers from a combination of texts and images with very few labels. We consider a classification framework with three modules: a backbone, a relational reasoning component, and a classification component. While the backbone can be trained from unlabeled images by self-supervised learning, we can fine-tune the relational reasoning and the classification components from external sources of knowledge instead of annotated images. By proposing a transformer-based model that creates structured knowledge from textual input, we enable the utilization of the knowledge in texts. We show that, compared to the supervised baselines with 1% of the annotated images, we can achieve ~8x more accurate results in scene graph classification, ~3x in object classification, and ~1.5x in predicate classification.
Classification by Attention: Scene Graph Classification with Prior Knowledge
Dec 17, 2020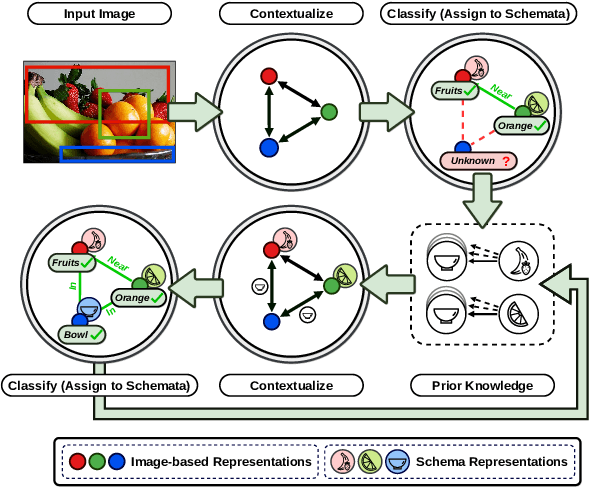
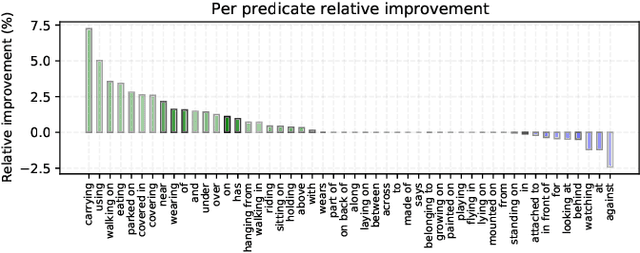
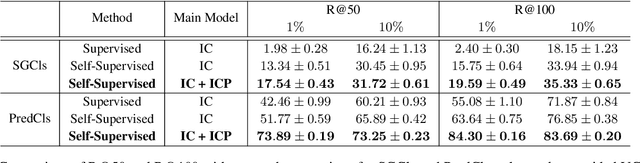

A major challenge in scene graph classification is that the appearance of objects and relations can be significantly different from one image to another. Previous works have addressed this by relational reasoning over all objects in an image or incorporating prior knowledge into classification. Unlike previous works, we do not consider separate models for perception and prior knowledge. Instead, we take a multi-task learning approach, where we implement the classification as an attention layer. This allows for the prior knowledge to emerge and propagate within the perception model. By enforcing the model also to represent the prior, we achieve a strong inductive bias. We show that our model can accurately generate commonsense knowledge and that the iterative injection of this knowledge to scene representations leads to significantly higher classification performance. Additionally, our model can be fine-tuned on external knowledge given as triples. When combined with self-supervised learning and with 1% of annotated images only, this gives more than 3% improvement in object classification, 26% in scene graph classification, and 36% in predicate prediction accuracy.