 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVE-LLM : Ontology-Assisted Automatic Vulnerability Evaluation Using Large Language Models
Feb 21, 2025
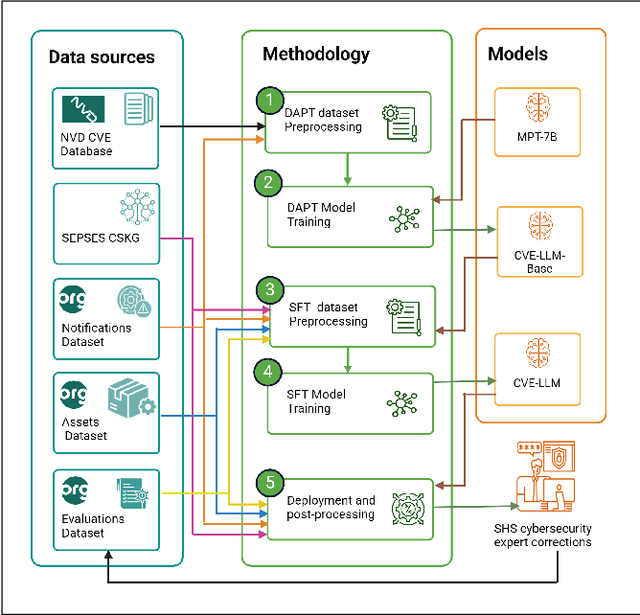

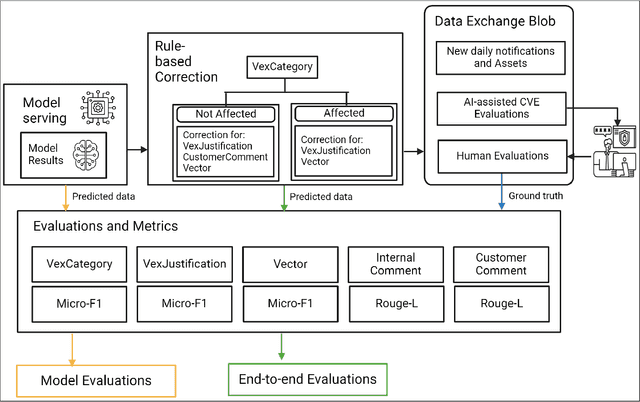
The National Vulnerability Database (NVD) publishes over a thousand new vulnerabilities monthly, with a projected 25 percent increase in 2024, highlighting the crucial need for rapid vulnerability identification to mitigate cybersecurity attacks and save costs and resources. In this work, we propose using large language models (LLMs) to learn vulnerability evaluation from historical assessments of medical device vulnerabilities in a single manufacturer's portfolio. We highlight the effectiveness and challenges of using LLMs for automatic vulnerability evaluation and introduce a method to enrich historical data with cybersecurity ontologies, enabling the system to understand new vulnerabilities without retraining the LLM. Our LLM system integrates with the in-house application - Cybersecurity Management System (CSMS) - to help Siemens Healthineers (SHS) product cybersecurity experts efficiently assess the vulnerabilities in our products. Also, we present guidelines for efficient integration of LLMs into the cybersecurity tool.
CVE-LLM : Automatic vulnerability evaluation in medical device industry using large language models
Jul 19, 2024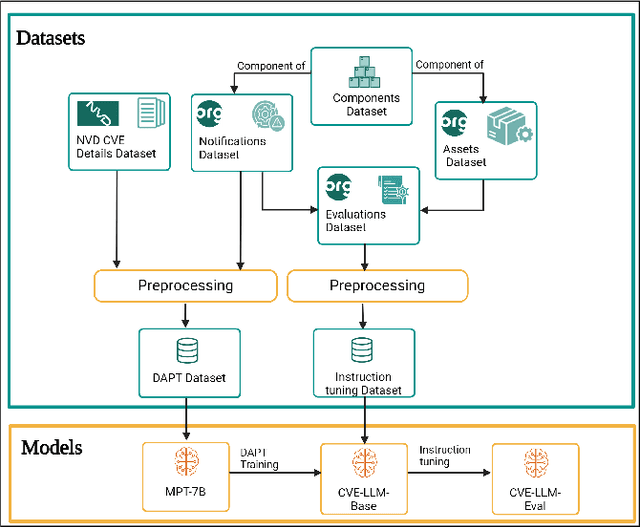

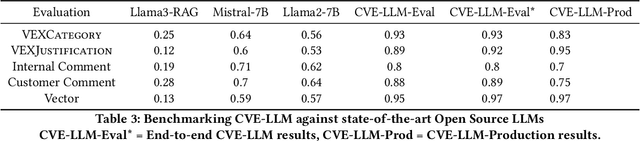
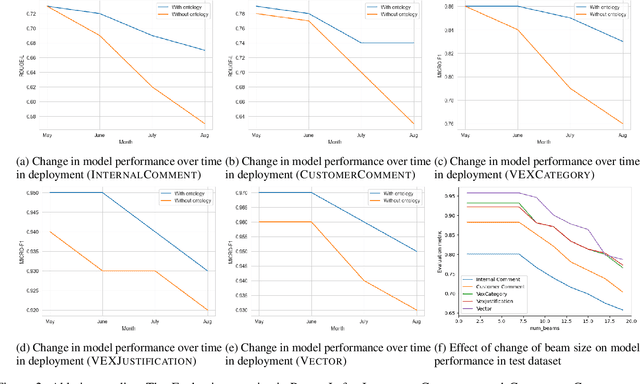
The healthcare industry is currently experiencing an unprecedented wave of cybersecurity attacks, impacting millions of individuals. With the discovery of thousands of vulnerabilities each month, there is a pressing need to drive the automation of vulnerability assessment processes for medical devices, facilitating rapid mitigation efforts. Generative AI systems have revolutionized various industries, offering unparalleled opportunities for automation and increased efficiency. This paper presents a solution leveraging Large Language Models (LLMs) to learn from historical evaluations of vulnerabilities for the automatic assessment of vulnerabilities in the medical devices industry. This approach is applied within the portfolio of a single manufacturer, taking into account device characteristics, including existing security posture and controls. The primary contributions of this paper are threefold. Firstly, it provides a detailed examination of the best practices for training a vulnerability Language Model (LM) in an industrial context. Secondly, it presents a comprehensive comparison and insightful analysis of the effectiveness of Language Models in vulnerability assessment. Finally, it proposes a new human-in-the-loop framework to expedite vulnerability evaluation processes.
Domain Adaptation for Sparse-Data Settings: What Do We Gain by Not Using Bert?
Mar 31, 2022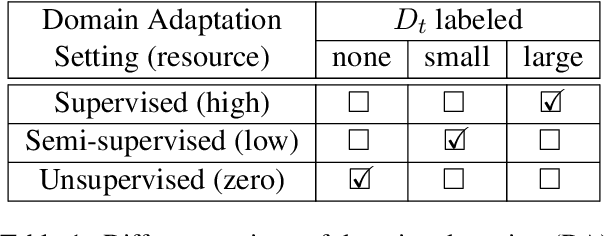



The practical success of much of NLP depends on the availability of training data. However, in real-world scenarios, training data is often scarce, not least because many application domains are restricted and specific. In this work, we compare different methods to handle this problem and provide guidelines for building NLP applications when there is only a small amount of labeled training data available for a specific domain. While transfer learning with pre-trained language models outperforms other methods across tasks, alternatives do not perform much worse while requiring much less computational effort, thus significantly reducing monetary and environmental cost. We examine the performance tradeoffs of several such alternatives, including models that can be trained up to 175K times faster and do not require a single GPU.
Scene Graph Generation for Better Image Captioning?
Sep 23, 2021
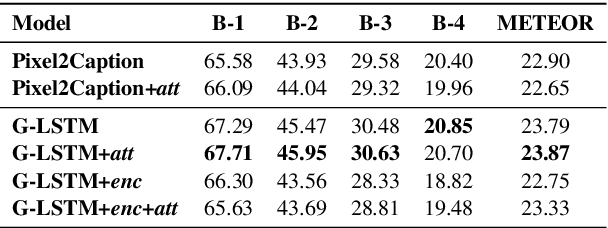
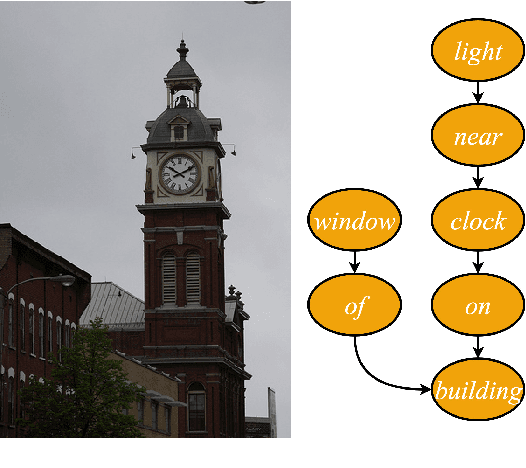
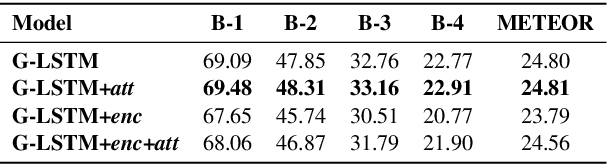
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.
Continuous Entailment Patterns for Lexical Inference in Context
Sep 08, 2021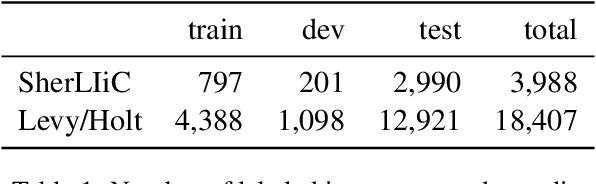
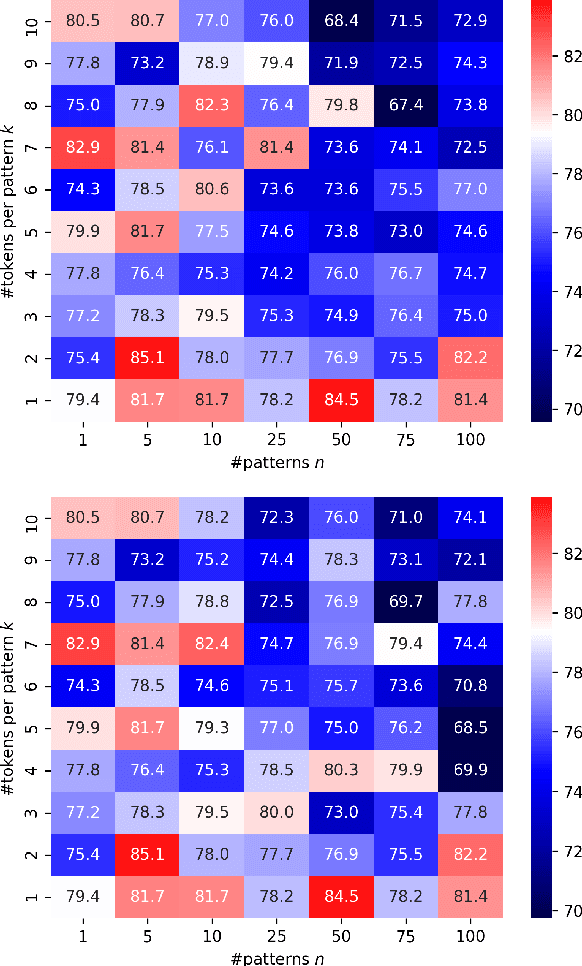
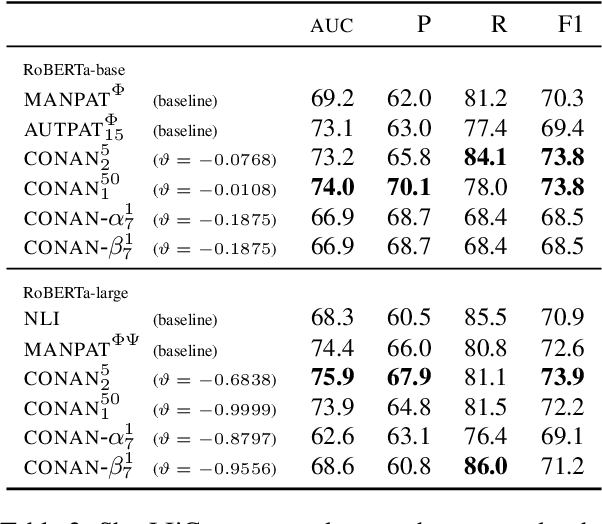
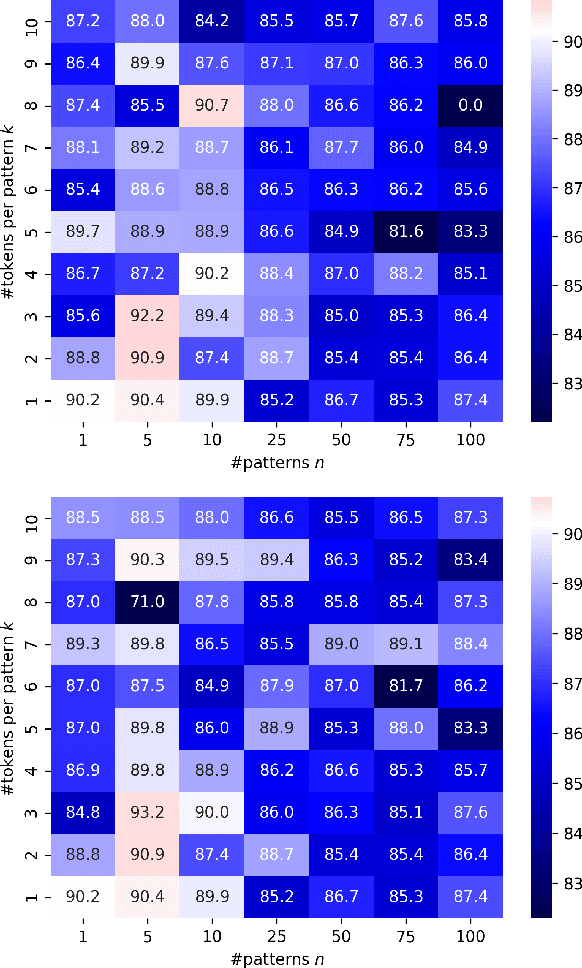
Combining a pretrained language model (PLM) with textual patterns has been shown to help in both zero- and few-shot settings. For zero-shot performance, it makes sense to design patterns that closely resemble the text seen during self-supervised pretraining because the model has never seen anything else. Supervised training allows for more flexibility. If we allow for tokens outside the PLM's vocabulary, patterns can be adapted more flexibly to a PLM's idiosyncrasies. Contrasting patterns where a "token" can be any continuous vector vs. those where a discrete choice between vocabulary elements has to be made, we call our method CONtinuous pAtterNs (CONAN). We evaluate CONAN on two established benchmarks for lexical inference in context (LIiC) a.k.a. predicate entailment, a challenging natural language understanding task with relatively small training sets. In a direct comparison with discrete patterns, CONAN consistently leads to improved performance, setting a new state of the art. Our experiments give valuable insights into the kind of pattern that enhances a PLM's performance on LIiC and raise important questions regarding our understanding of PLMs using text patterns.
Position Information in Transformers: An Overview
Feb 22, 2021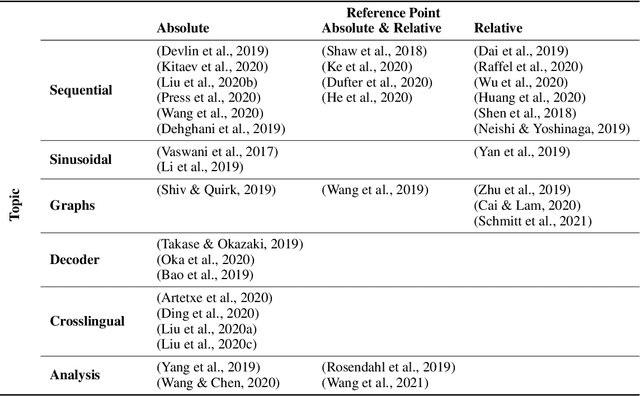

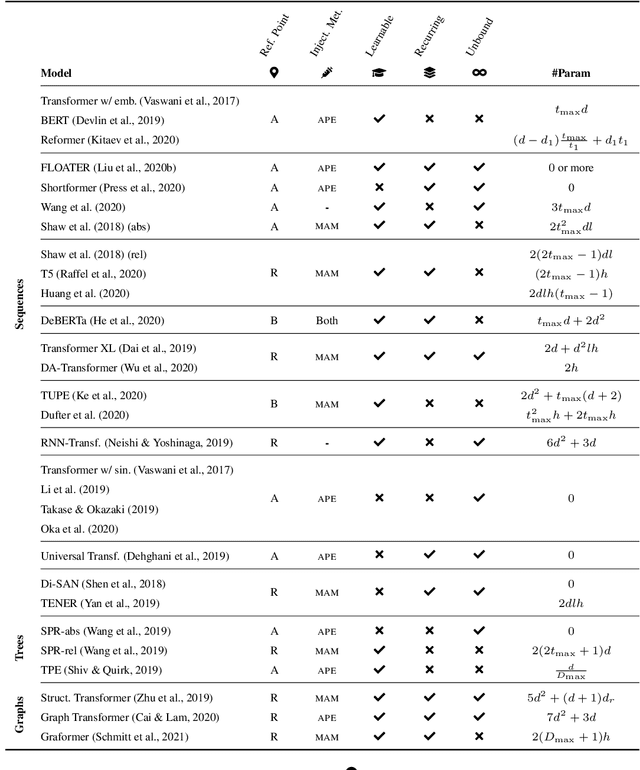

Transformers are arguably the main workhorse in recent Natural Language Processing research. By definition a Transformer is invariant with respect to reorderings of the input. However, language is inherently sequential and word order is essential to the semantics and syntax of an utterance. In this paper, we provide an overview of common methods to incorporate position information into Transformer models. The objectives of this survey are to i) showcase that position information in Transformer is a vibrant and extensive research area; ii) enable the reader to compare existing methods by providing a unified notation and meaningful clustering; iii) indicate what characteristics of an application should be taken into account when selecting a position encoding; iv) provide stimuli for future research.
Language Models for Lexical Inference in Context
Feb 10, 2021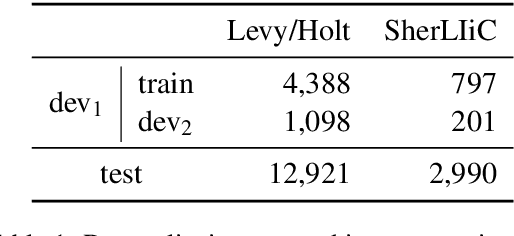
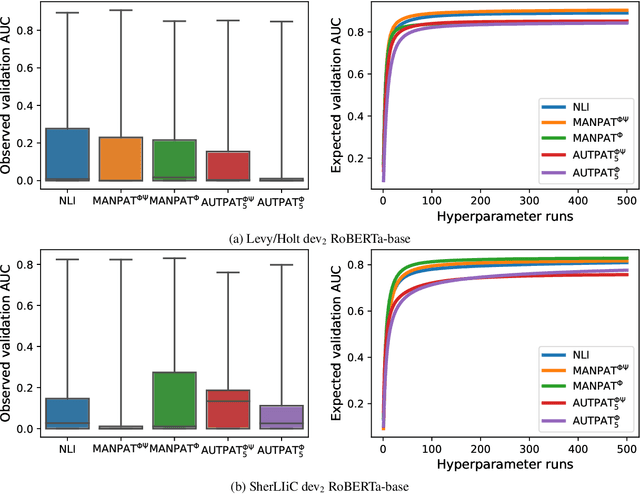
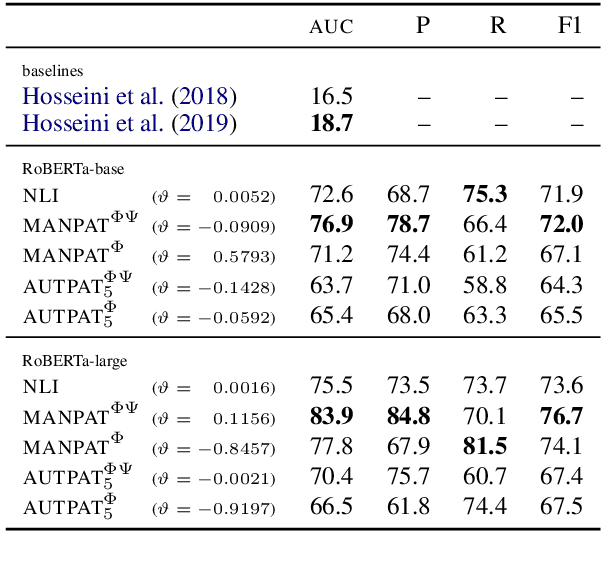
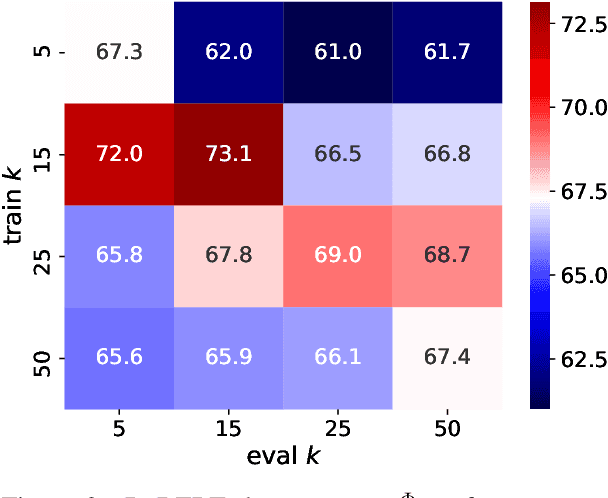
Lexical inference in context (LIiC) is the task of recognizing textual entailment between two very similar sentences, i.e., sentences that only differ in one expression. It can therefore be seen as a variant of the natural language inference task that is focused on lexical semantics. We formulate and evaluate the first approaches based on pretrained language models (LMs) for this task: (i) a few-shot NLI classifier, (ii) a relation induction approach based on handcrafted patterns expressing the semantics of lexical inference, and (iii) a variant of (ii) with patterns that were automatically extracted from a corpus. All our approaches outperform the previous state of the art, showing the potential of pretrained LMs for LIiC. In an extensive analysis, we investigate factors of success and failure of our three approaches.
Improving Visual Reasoning by Exploiting The Knowledge in Texts
Feb 09, 2021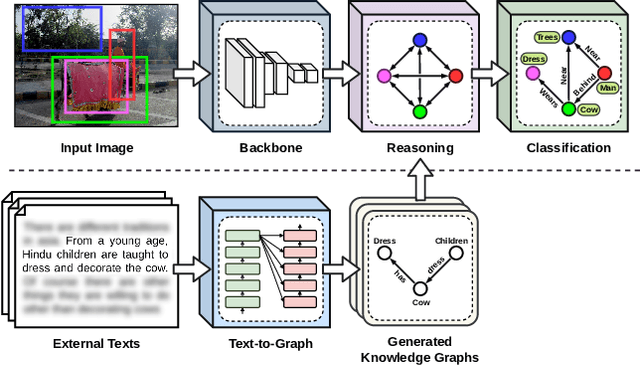

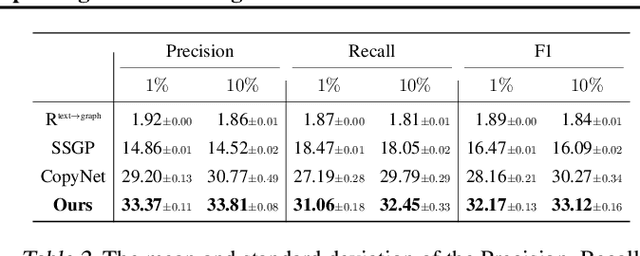
This paper presents a new framework for training image-based classifiers from a combination of texts and images with very few labels. We consider a classification framework with three modules: a backbone, a relational reasoning component, and a classification component. While the backbone can be trained from unlabeled images by self-supervised learning, we can fine-tune the relational reasoning and the classification components from external sources of knowledge instead of annotated images. By proposing a transformer-based model that creates structured knowledge from textual input, we enable the utilization of the knowledge in texts. We show that, compared to the supervised baselines with 1% of the annotated images, we can achieve ~8x more accurate results in scene graph classification, ~3x in object classification, and ~1.5x in predicate classification.
Ranking vs. Classifying: Measuring Knowledge Base Completion Quality
Feb 02, 2021

Knowledge base completion (KBC) methods aim at inferring missing facts from the information present in a knowledge base (KB) by estimating the likelihood of candidate facts. In the prevailing evaluation paradigm, models do not actually decide whether a new fact should be accepted or not but are solely judged on the position of true facts in a likelihood ranking with other candidates. We argue that consideration of binary predictions is essential to reflect the actual KBC quality, and propose a novel evaluation paradigm, designed to provide more transparent model selection criteria for a realistic scenario. We construct the data set FB14k-QAQ where instead of single facts, we use KB queries, i.e., facts where one entity is replaced with a variable, and construct corresponding sets of entities that are correct answers. We randomly remove some of these correct answers from the data set, simulating the realistic scenario of real-world entities missing from a KB. This way, we can explicitly measure a model's ability to handle queries that have more correct answers in the real world than in the KB, including the special case of queries without any valid answer. The latter especially contrasts the ranking setting. We evaluate a number of state-of-the-art KB embeddings models on our new benchmark. The differences in relative performance between ranking-based and classification-based evaluation that we observe in our experiments confirm our hypothesis that good performance on the ranking task does not necessarily translate to good performance on the actual completion task. Our results motivate future work on KB embedding models with better prediction separability and, as a first step in that direction, we propose a simple variant of TransE that encourages thresholding and achieves a significant improvement in classification F1 score relative to the original TransE.
Investigating Pretrained Language Models for Graph-to-Text Generation
Jul 16, 2020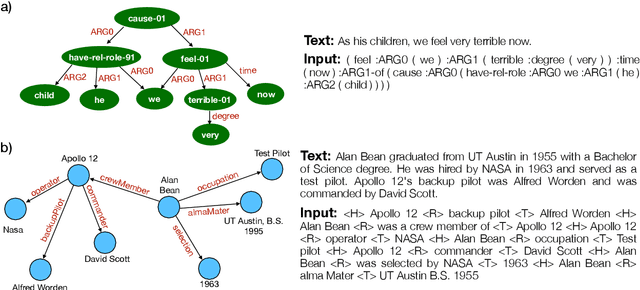
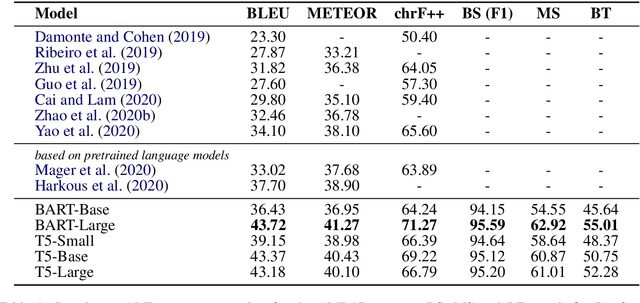
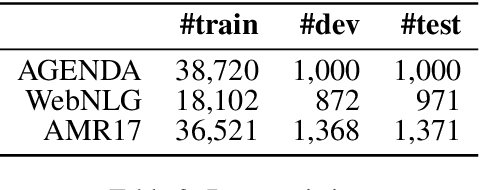
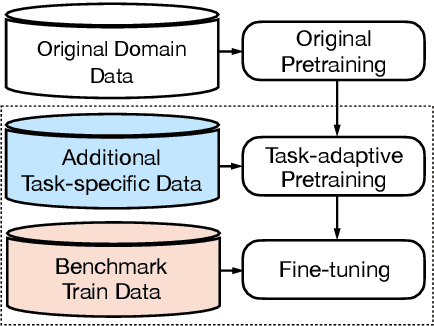
Graph-to-text generation, a subtask of data-to-text generation, aims to generate fluent texts from graph-based data. Many graph-to-text models have shown strong performance in this task employing specialized graph encoders. However, recent approaches employ large pretrained language models (PLMs) achieving state-of-the-art results in data-to-text generation. In this paper, we aim to investigate the impact of large PLMs in graph-to-text generation. We present a study across three graph domains: meaning representations, Wikipedia knowledge graphs (KGs) and scientific KGs. Our analysis shows that PLMs such as BART and T5 achieve state-of-the-art results in graph-to-text benchmarks without explicitly encoding the graph structure. We also demonstrate that task-adaptive pretraining strategies are beneficial to the target task, improving even further the state of the art in two benchmarks for graph-to-text generation. In a final analysis, we investigate possible reasons for the PLMs' success on graph-to-text tasks. We find evidence that their knowledge about the world gives them a big advantage, especially when generating texts from KGs.