 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph Generation for Better Image Captioning?
Paper and Code

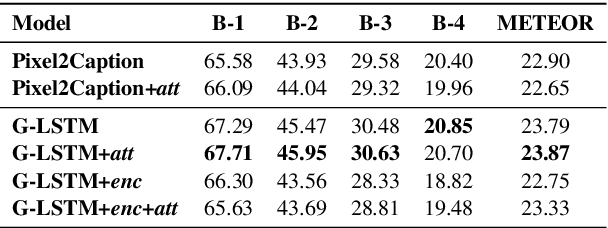
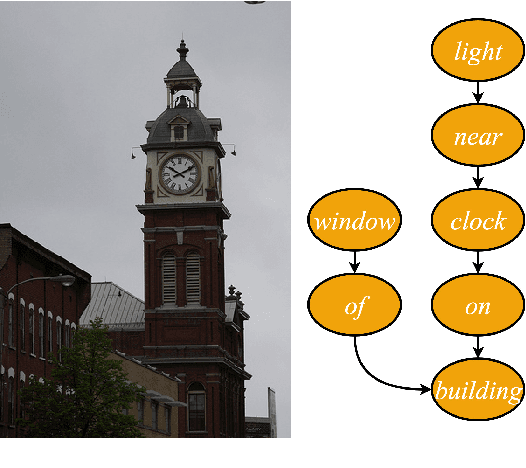
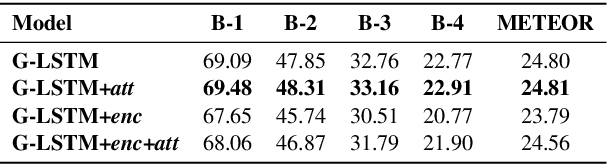
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.