 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReInform: Selecting paths with reinforcement learning for contextualized link prediction
Nov 19, 2022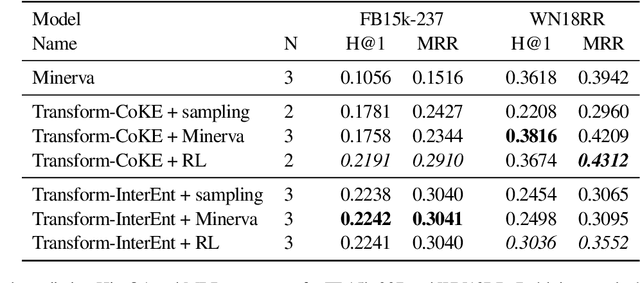
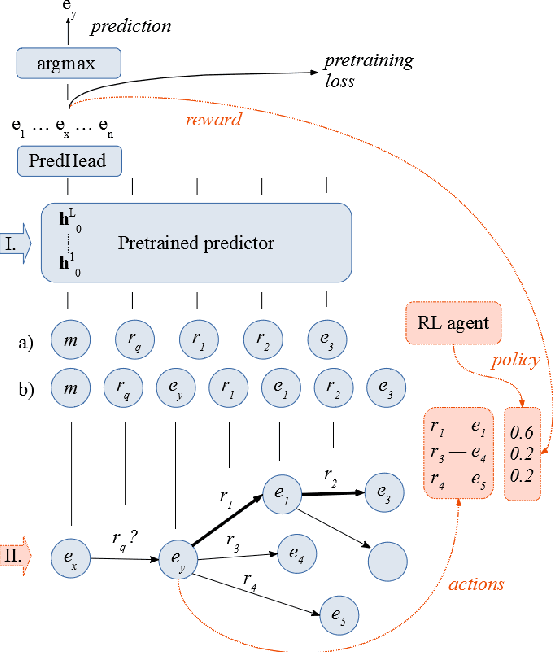
We propose to use reinforcement learning to inform transformer-based contextualized link prediction models by providing paths that are most useful for predicting the correct answer. This is in contrast to previous approaches, that either used reinforcement learning (RL) to directly search for the answer, or based their prediction on limited or randomly selected context. Our experiments on WN18RR and FB15k-237 show that contextualized link prediction models consistently outperform RL-based answer search, and that additional improvements (of up to 13.5\% MRR) can be gained by combining RL with a link prediction model.
Knodle: Modular Weakly Supervised Learning with PyTorch
May 10, 2021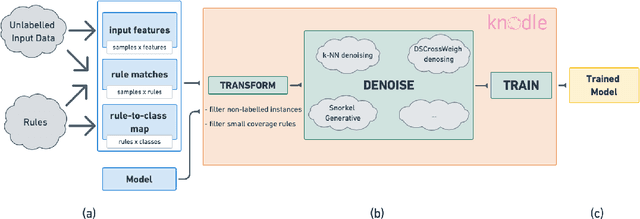

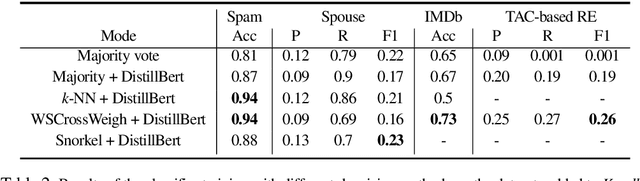
Strategies for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task or integrated with a specific model architecture. In this work, we propose a software framework Knodle that treats weak data annotations, deep learning models, and methods for improving weakly supervised training as separate, modular components. The standardized interfaces between these independent parts account for data- and model-agnostic weak supervision method development, but still allow the training process to access fine-grained information such as data set characteristics, matches of heuristic rules, as well as elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those that harness the interplay of neural networks and weakly labeled data. We illustrate the benchmarking potential of the framework with a performance comparison of several reference implementations on a selection of datasets that are already available in Knodle.
Ranking vs. Classifying: Measuring Knowledge Base Completion Quality
Feb 02, 2021

Knowledge base completion (KBC) methods aim at inferring missing facts from the information present in a knowledge base (KB) by estimating the likelihood of candidate facts. In the prevailing evaluation paradigm, models do not actually decide whether a new fact should be accepted or not but are solely judged on the position of true facts in a likelihood ranking with other candidates. We argue that consideration of binary predictions is essential to reflect the actual KBC quality, and propose a novel evaluation paradigm, designed to provide more transparent model selection criteria for a realistic scenario. We construct the data set FB14k-QAQ where instead of single facts, we use KB queries, i.e., facts where one entity is replaced with a variable, and construct corresponding sets of entities that are correct answers. We randomly remove some of these correct answers from the data set, simulating the realistic scenario of real-world entities missing from a KB. This way, we can explicitly measure a model's ability to handle queries that have more correct answers in the real world than in the KB, including the special case of queries without any valid answer. The latter especially contrasts the ranking setting. We evaluate a number of state-of-the-art KB embeddings models on our new benchmark. The differences in relative performance between ranking-based and classification-based evaluation that we observe in our experiments confirm our hypothesis that good performance on the ranking task does not necessarily translate to good performance on the actual completion task. Our results motivate future work on KB embedding models with better prediction separability and, as a first step in that direction, we propose a simple variant of TransE that encourages thresholding and achieves a significant improvement in classification F1 score relative to the original TransE.