 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnodle: Modular Weakly Supervised Learning with PyTorch
Paper and Code
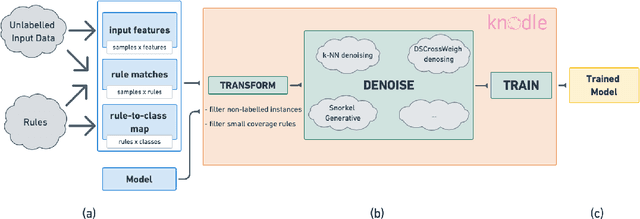

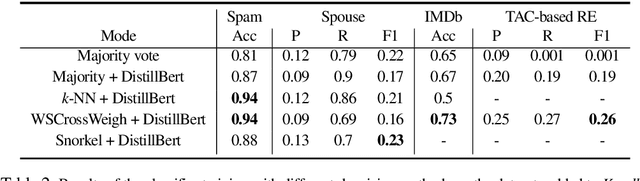
Strategies for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task or integrated with a specific model architecture. In this work, we propose a software framework Knodle that treats weak data annotations, deep learning models, and methods for improving weakly supervised training as separate, modular components. The standardized interfaces between these independent parts account for data- and model-agnostic weak supervision method development, but still allow the training process to access fine-grained information such as data set characteristics, matches of heuristic rules, as well as elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those that harness the interplay of neural networks and weakly labeled data. We illustrate the benchmarking potential of the framework with a performance comparison of several reference implementations on a selection of datasets that are already available in Knodle.