 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Sparse-Data Settings: What Do We Gain by Not Using Bert?
Paper and Code
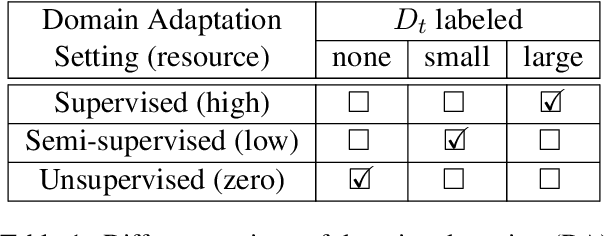



The practical success of much of NLP depends on the availability of training data. However, in real-world scenarios, training data is often scarce, not least because many application domains are restricted and specific. In this work, we compare different methods to handle this problem and provide guidelines for building NLP applications when there is only a small amount of labeled training data available for a specific domain. While transfer learning with pre-trained language models outperforms other methods across tasks, alternatives do not perform much worse while requiring much less computational effort, thus significantly reducing monetary and environmental cost. We examine the performance tradeoffs of several such alternatives, including models that can be trained up to 175K times faster and do not require a single GPU.