Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlbNews: A Corpus of Headlines for Topic Modeling in Albanian
Paper and Code

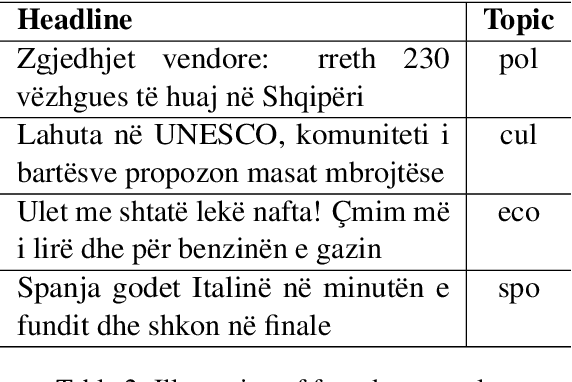
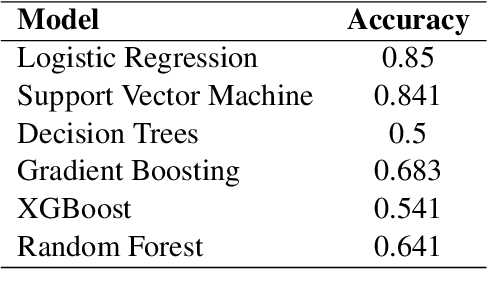
The scarcity of available text corpora for low-resource languages like Albanian is a serious hurdle for research in natural language processing tasks. This paper introduces AlbNews, a collection of 600 topically labeled news headlines and 2600 unlabeled ones in Albanian. The data can be freely used for conducting topic modeling research. We report the initial classification scores of some traditional machine learning classifiers trained with the AlbNews samples. These results show that basic models outrun the ensemble learning ones and can serve as a baseline for future experiments.
View paper on