 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Contrastive Training for Test-based Constituency Analysis
Paper and Code
Sep 30, 2021
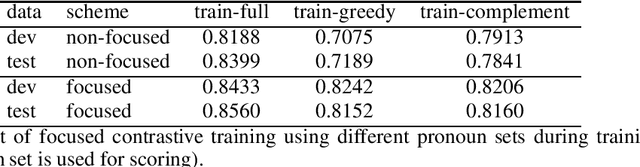
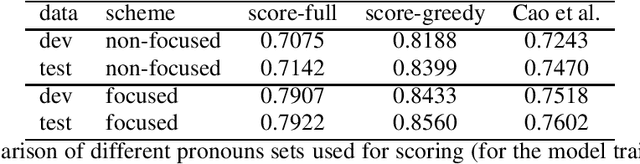

We propose a scheme for self-training of grammaticality models for constituency analysis based on linguistic tests. A pre-trained language model is fine-tuned by contrastive estimation of grammatical sentences from a corpus, and ungrammatical sentences that were perturbed by a syntactic test, a transformation that is motivated by constituency theory. We show that consistent gains can be achieved if only certain positive instances are chosen for training, depending on whether they could be the result of a test transformation. This way, the positives, and negatives exhibit similar characteristics, which makes the objective more challenging for the language model, and also allows for additional markup that indicates the position of the test application within the sentence.