 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Outcomes, Different Journeys: A Trace-Level Framework for Comparing Human and GUI-Agent Behavior in Production Search Systems
Apr 09, 2026LLM-driven GUI agents are increasingly used in production systems to automate workflows and simulate users for evaluation and optimization. Yet most GUI-agent evaluations emphasize task success and provide limited evidence on whether agents interact in human-like ways. We present a trace-level evaluation framework that compares human and agent behavior across (i) task outcome and effort, (ii) query formulation, and (iii) navigation across interface states. We instantiate the framework in a controlled study in a production audio-streaming search application, where 39 participants and a state-of-the-art GUI agent perform ten multi-hop search tasks. The agent achieves task success comparable to participants and generates broadly aligned queries, but follows systematically different navigation strategies: participants exhibit content-centric, exploratory behavior, while the agent is more search-centric and low-branching. These results show that outcome and query alignment do not imply behavioral alignment, motivating trace-level diagnostics when deploying GUI agents as proxies for users in production search systems.
Multimodal Machine Learning for Early Prediction of Metastasis in a Swedish Multi-Cancer Cohort
Mar 31, 2026Multimodal Machine Learning offers a holistic view of a patient's status, integrating structured and unstructured data from electronic health records (EHR). We propose a framework to predict metastasis risk one month prior to diagnosis, using six months of clinical history from EHR data. Data from four cancer cohorts collected at Karolinska University Hospital (Stockholm, Sweden) were analyzed: breast (n = 743), colon (n = 387), lung (n = 870), and prostate (n = 1890). The dataset included demographics, comorbidities, laboratory results, medications, and clinical text. We compared traditional and deep learning classifiers across single modalities and multimodal combinations, using various fusion strategies and a Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) 2a design, with an 80-20 development-validation split to ensure a rigorous, repeatable evaluation. Performance was evaluated using AUROC, AUPRC, F1 score, sensitivity, and specificity. We then employed a multimodal adaptation of SHAP to analyze the classifiers' reasoning. Intermediate fusion achieved the highest F1 scores on breast (0.845), colon (0.786), and prostate cancer (0.845), demonstrating strong predictive performance. For lung cancer, the intermediate fusion achieved an F1 score of 0.819, while the text-only model achieved the highest, with an F1 score of 0.829. Deep learning classifiers consistently outperformed traditional models. Colon cancer, the smallest cohort, had the lowest performance, highlighting the importance of sufficient training data. SHAP analysis showed that the relative importance of modalities varied across cancer types. Fusion strategies offer distinct strengths and weaknesses. Intermediate fusion consistently delivered the best results, but strategy choices should align with data characteristics and organizational needs.
CHiL(L)Grader: Calibrated Human-in-the-Loop Short-Answer Grading
Mar 12, 2026Scaling educational assessment with large language models requires not just accuracy, but the ability to recognize when predictions are trustworthy. Instruction-tuned models tend to be overconfident, and their reliability deteriorates as curricula evolve, making fully autonomous deployment unsafe in high-stakes settings. We introduce CHiL(L)Grader, the first automated grading framework that incorporates calibrated confidence estimation into a human-in-the-loop workflow. Using post-hoc temperature scaling, confidence-based selective prediction, and continual learning, CHiL(L)Grader automates only high-confidence predictions while routing uncertain cases to human graders, and adapts to evolving rubrics and unseen questions. Across three short-answer grading datasets, CHiL(L)Grader automatically scores 35-65% of responses at expert-level quality (QWK >= 0.80). A QWK gap of 0.347 between accepted and rejected predictions confirms the effectiveness of the confidence-based routing. Each correction cycle strengthens the model's grading capability as it learns from teacher feedback. These results show that uncertainty quantification is key for reliable AI-assisted grading.
PAX-TS: Model-agnostic multi-granular explanations for time series forecasting via localized perturbations
Aug 26, 2025Time series forecasting has seen considerable improvement during the last years, with transformer models and large language models driving advancements of the state of the art. Modern forecasting models are generally opaque and do not provide explanations for their forecasts, while well-known post-hoc explainability methods like LIME are not suitable for the forecasting context. We propose PAX-TS, a model-agnostic post-hoc algorithm to explain time series forecasting models and their forecasts. Our method is based on localized input perturbations and results in multi-granular explanations. Further, it is able to characterize cross-channel correlations for multivariate time series forecasts. We clearly outline the algorithmic procedure behind PAX-TS, demonstrate it on a benchmark with 7 algorithms and 10 diverse datasets, compare it with two other state-of-the-art explanation algorithms, and present the different explanation types of the method. We found that the explanations of high-performing and low-performing algorithms differ on the same datasets, highlighting that the explanations of PAX-TS effectively capture a model's behavior. Based on time step correlation matrices resulting from the benchmark, we identify 6 classes of patterns that repeatedly occur across different datasets and algorithms. We found that the patterns are indicators of performance, with noticeable differences in forecasting error between the classes. Lastly, we outline a multivariate example where PAX-TS demonstrates how the forecasting model takes cross-channel correlations into account. With PAX-TS, time series forecasting models' mechanisms can be illustrated in different levels of detail, and its explanations can be used to answer practical questions on forecasts.
Counterfactual Explanations for Time Series Forecasting
Oct 12, 2023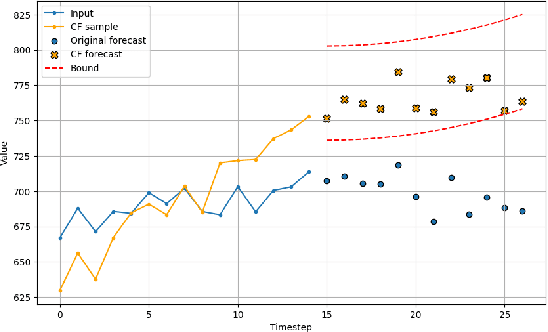
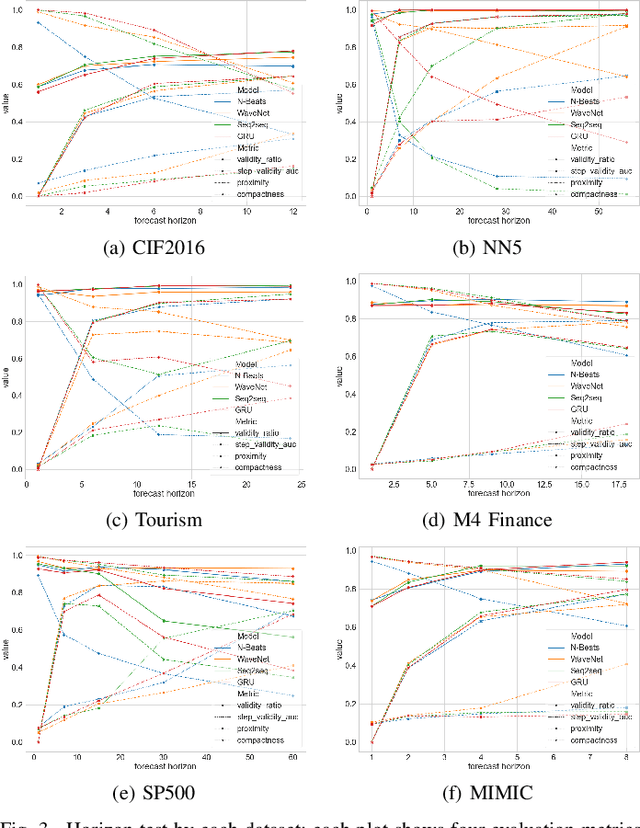
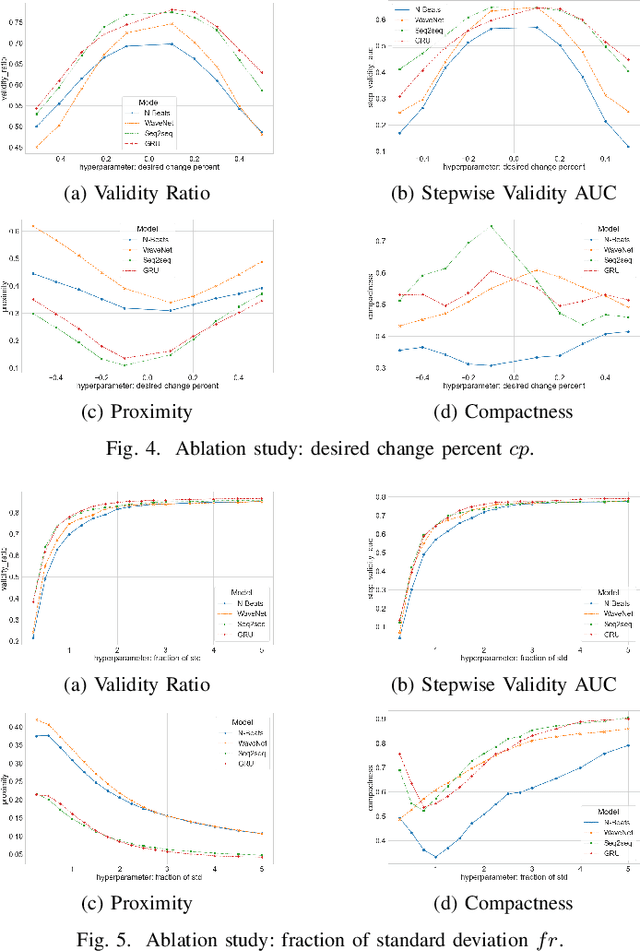
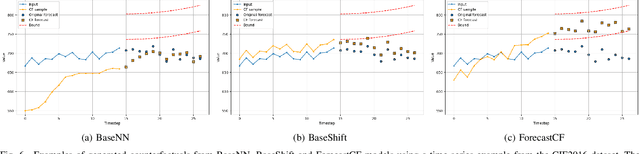
Among recent developments in time series forecasting methods, deep forecasting models have gained popularity as they can utilize hidden feature patterns in time series to improve forecasting performance. Nevertheless, the majority of current deep forecasting models are opaque, hence making it challenging to interpret the results. While counterfactual explanations have been extensively employed as a post-hoc approach for explaining classification models, their application to forecasting models still remains underexplored. In this paper, we formulate the novel problem of counterfactual generation for time series forecasting, and propose an algorithm, called ForecastCF, that solves the problem by applying gradient-based perturbations to the original time series. ForecastCF guides the perturbations by applying constraints to the forecasted values to obtain desired prediction outcomes. We experimentally evaluate ForecastCF using four state-of-the-art deep model architectures and compare to two baselines. Our results show that ForecastCF outperforms the baseline in terms of counterfactual validity and data manifold closeness. Overall, our findings suggest that ForecastCF can generate meaningful and relevant counterfactual explanations for various forecasting tasks.
An End-to-End Workflow using Topic Segmentation and Text Summarisation Methods for Improved Podcast Comprehension
Jul 25, 2023The consumption of podcast media has been increasing rapidly. Due to the lengthy nature of podcast episodes, users often carefully select which ones to listen to. Although episode descriptions aid users by providing a summary of the entire podcast, they do not provide a topic-by-topic breakdown. This study explores the combined application of topic segmentation and text summarisation methods to investigate how podcast episode comprehension can be improved. We have sampled 10 episodes from Spotify's English-Language Podcast Dataset and employed TextTiling and TextSplit to segment them. Moreover, three text summarisation models, namely T5, BART, and Pegasus, were applied to provide a very short title for each segment. The segmentation part was evaluated using our annotated sample with the $P_k$ and WindowDiff ($WD$) metrics. A survey was also rolled out ($N=25$) to assess the quality of the generated summaries. The TextSplit algorithm achieved the lowest mean for both evaluation metrics ($\bar{P_k}=0.41$ and $\bar{WD}=0.41$), while the T5 model produced the best summaries, achieving a relevancy score only $8\%$ less to the one achieved by the human-written titles.
FLICU: A Federated Learning Workflow for Intensive Care Unit Mortality Prediction
May 30, 2022
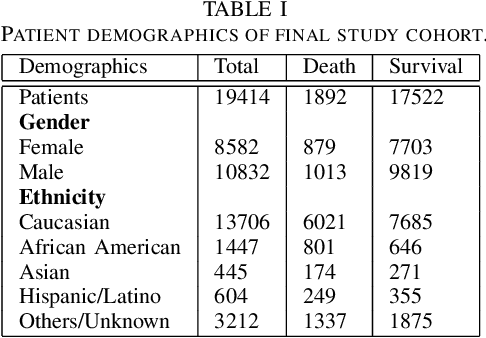
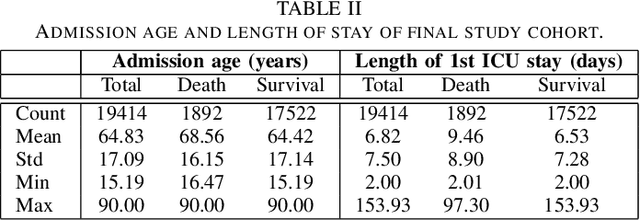
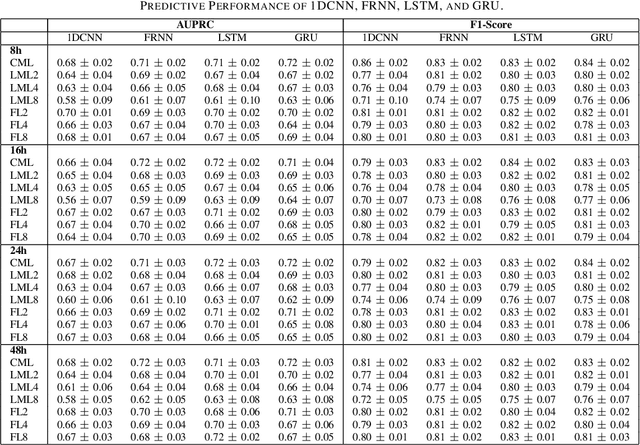
Although Machine Learning (ML) can be seen as a promising tool to improve clinical decision-making for supporting the improvement of medication plans, clinical procedures, diagnoses, or medication prescriptions, it remains limited by access to healthcare data. Healthcare data is sensitive, requiring strict privacy practices, and typically stored in data silos, making traditional machine learning challenging. Federated learning can counteract those limitations by training machine learning models over data silos while keeping the sensitive data localized. This study proposes a federated learning workflow for ICU mortality prediction. Hereby, the applicability of federated learning as an alternative to centralized machine learning and local machine learning is investigated by introducing federated learning to the binary classification problem of predicting ICU mortality. We extract multivariate time series data from the MIMIC-III database (lab values and vital signs), and benchmark the predictive performance of four deep sequential classifiers (FRNN, LSTM, GRU, and 1DCNN) varying the patient history window lengths (8h, 16h, 24h, 48h) and the number of FL clients (2, 4, 8). The experiments demonstrate that both centralized machine learning and federated learning are comparable in terms of AUPRC and F1-score. Furthermore, the federated approach shows superior performance over local machine learning. Thus, the federated approach can be seen as a valid and privacy-preserving alternative to centralized machine learning for classifying ICU mortality when sharing sensitive patient data between hospitals is not possible.
Robust Explanations for Private Support Vector Machines
Feb 07, 2021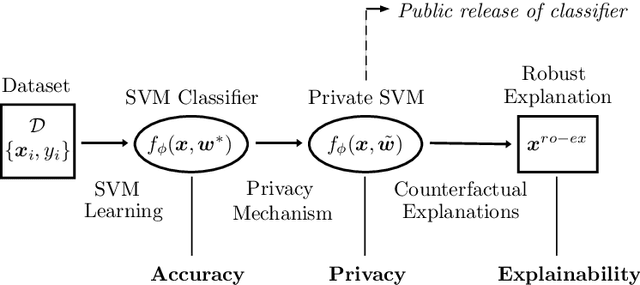
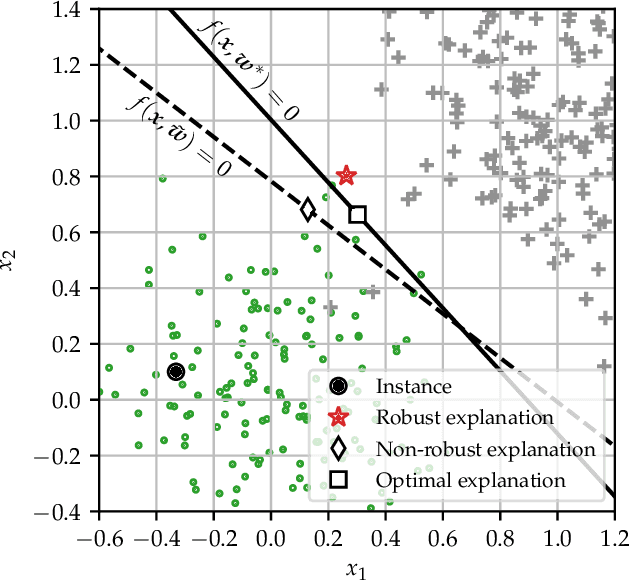
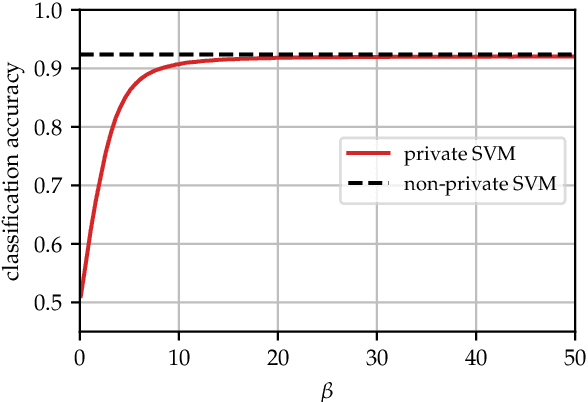
We consider counterfactual explanations for private support vector machines (SVM), where the privacy mechanism that publicly releases the classifier guarantees differential privacy. While privacy preservation is essential when dealing with sensitive data, there is a consequent degradation in the classification accuracy due to the introduced perturbations in the classifier weights. For such classifiers, counterfactual explanations need to be robust against the uncertainties in the SVM weights in order to ensure, with high confidence, that the classification of the data instance to be explained is different than its explanation. We model the uncertainties in the SVM weights through a random vector, and formulate the explanation problem as an optimization problem with probabilistic constraint. Subsequently, we characterize the problem's deterministic equivalent and study its solution. For linear SVMs, the problem is a convex second-order cone program. For non-linear SVMs, the problem is non-convex. Thus, we propose a sub-optimal solution that is based on the bisection method. The results show that, contrary to non-robust explanations, the quality of explanations from the robust solution degrades with increasing privacy in order to guarantee a prespecified confidence level for correct classifications.
Clinical Predictive Keyboard using Statistical and Neural Language Modeling
Jun 22, 2020
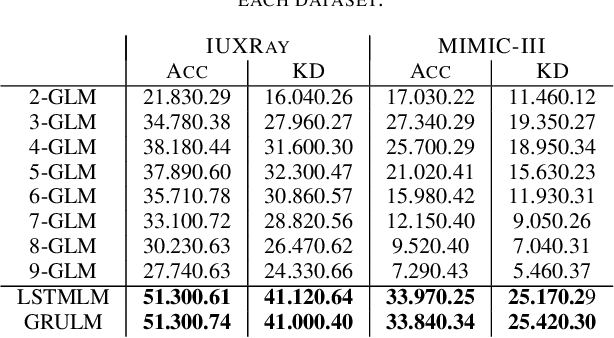
A language model can be used to predict the next word during authoring, to correct spelling or to accelerate writing (e.g., in sms or emails). Language models, however, have only been applied in a very small scale to assist physicians during authoring (e.g., discharge summaries or radiology reports). But along with the assistance to the physician, computer-based systems which expedite the patient's exit also assist in decreasing the hospital infections. We employed statistical and neural language modeling to predict the next word of a clinical text and assess all the models in terms of accuracy and keystroke discount in two datasets with radiology reports. We show that a neural language model can achieve as high as 51.3% accuracy in radiology reports (one out of two words predicted correctly). We also show that even when the models are employed only for frequent words, the physician can save valuable time.
RTEX: A novel methodology for Ranking, Tagging, and Explanatory diagnostic captioning of radiography exams
Jun 11, 2020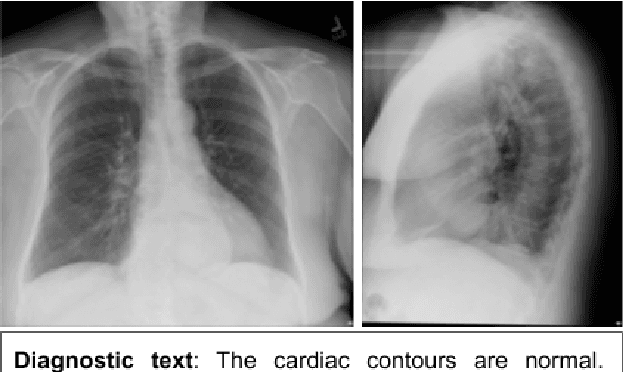
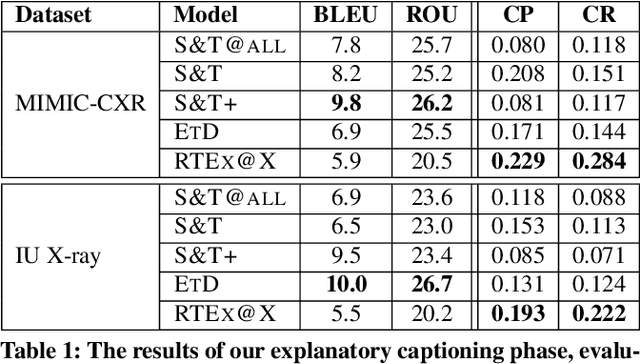

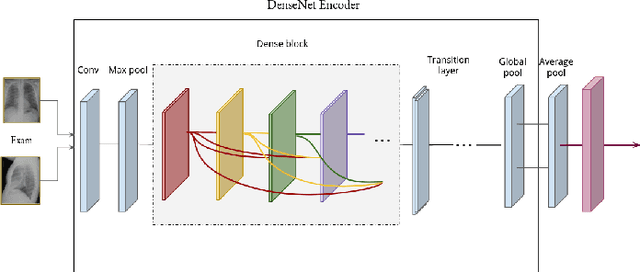
This paper introduces RTEx, a novel methodology for a) ranking radiography exams based on their probability to contain an abnormality, b) generating abnormality tags for abnormal exams, and c) providing a diagnostic explanation in natural language for each abnormal exam. The task of ranking radiography exams is an important first step for practitioners who want to identify and prioritize those radiography exams that are more likely to contain abnormalities, for example, to avoid mistakes due to tiredness or to manage heavy workload (e.g., during a pandemic). We used two publicly available datasets to assess our methodology and demonstrate that for the task of ranking it outperforms its competitors in terms of NDCG@k. For each abnormal radiography exam RTEx generates a set of abnormality tags alongside an explanatory diagnostic text to explain the tags and guide the medical expert. Our tagging component outperforms two strong competitor methods in terms of F1. Moreover, the diagnostic captioning component of RTEx, which exploits the already extracted tags to constrain the captioning process, outperforms all competitors with respect to clinical precision and recall.