 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAMSUL: Simultaneous Heatmap-Analysis to investigate Medical Significance Utilizing Local interpretability methods
Jul 16, 2023


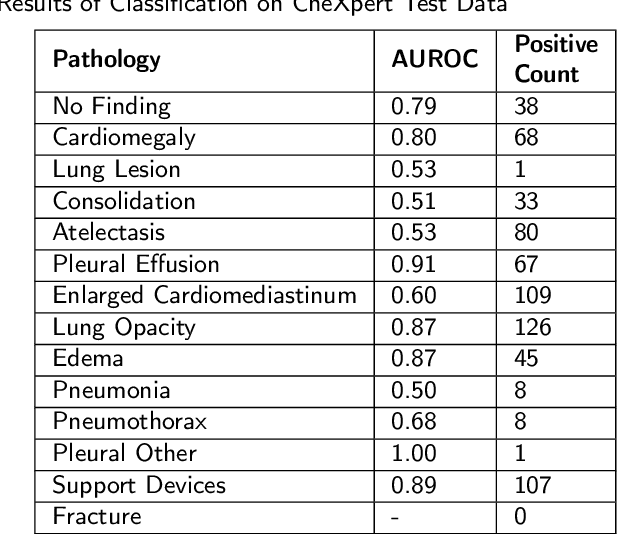
The interpretability of deep neural networks has become a subject of great interest within the medical and healthcare domain. This attention stems from concerns regarding transparency, legal and ethical considerations, and the medical significance of predictions generated by these deep neural networks in clinical decision support systems. To address this matter, our study delves into the application of four well-established interpretability methods: Local Interpretable Model-agnostic Explanations (LIME), Shapley Additive exPlanations (SHAP), Gradient-weighted Class Activation Mapping (Grad-CAM), and Layer-wise Relevance Propagation (LRP). Leveraging the approach of transfer learning with a multi-label-multi-class chest radiography dataset, we aim to interpret predictions pertaining to specific pathology classes. Our analysis encompasses both single-label and multi-label predictions, providing a comprehensive and unbiased assessment through quantitative and qualitative investigations, which are compared against human expert annotation. Notably, Grad-CAM demonstrates the most favorable performance in quantitative evaluation, while the LIME heatmap segmentation visualization exhibits the highest level of medical significance. Our research highlights the strengths and limitations of these interpretability methods and suggests that a multimodal-based approach, incorporating diverse sources of information beyond chest radiography images, could offer additional insights for enhancing interpretability in the medical domain.
A Bayesian Optimization approach for calibrating large-scale activity-based transport models
Feb 07, 2023The use of Agent-Based and Activity-Based modeling in transportation is rising due to the capability of addressing complex applications such as disruptive trends (e.g., remote working and automation) or the design and assessment of disaggregated management strategies. Still, the broad adoption of large-scale disaggregate models is not materializing due to the inherently high complexity and computational needs. Activity-based models focused on behavioral theory, for example, may involve hundreds of parameters that need to be calibrated to match the detailed socio-economical characteristics of the population for any case study. This paper tackles this issue by proposing a novel Bayesian Optimization approach incorporating a surrogate model in the form of an improved Random Forest, designed to automate the calibration process of the behavioral parameters. The proposed method is tested on a case study for the city of Tallinn, Estonia, where the model to be calibrated consists of 477 behavioral parameters, using the SimMobility MT software. Satisfactory performance is achieved in the major indicators defined for the calibration process: the error for the overall number of trips is equal to 4% and the average error in the OD matrix is 15.92 vehicles per day.
FLICU: A Federated Learning Workflow for Intensive Care Unit Mortality Prediction
May 30, 2022
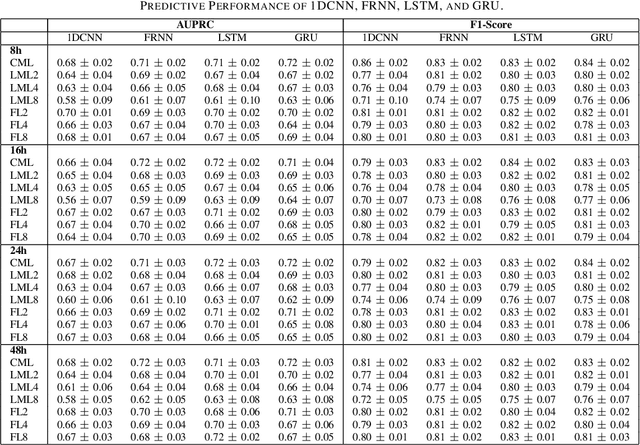
Although Machine Learning (ML) can be seen as a promising tool to improve clinical decision-making for supporting the improvement of medication plans, clinical procedures, diagnoses, or medication prescriptions, it remains limited by access to healthcare data. Healthcare data is sensitive, requiring strict privacy practices, and typically stored in data silos, making traditional machine learning challenging. Federated learning can counteract those limitations by training machine learning models over data silos while keeping the sensitive data localized. This study proposes a federated learning workflow for ICU mortality prediction. Hereby, the applicability of federated learning as an alternative to centralized machine learning and local machine learning is investigated by introducing federated learning to the binary classification problem of predicting ICU mortality. We extract multivariate time series data from the MIMIC-III database (lab values and vital signs), and benchmark the predictive performance of four deep sequential classifiers (FRNN, LSTM, GRU, and 1DCNN) varying the patient history window lengths (8h, 16h, 24h, 48h) and the number of FL clients (2, 4, 8). The experiments demonstrate that both centralized machine learning and federated learning are comparable in terms of AUPRC and F1-score. Furthermore, the federated approach shows superior performance over local machine learning. Thus, the federated approach can be seen as a valid and privacy-preserving alternative to centralized machine learning for classifying ICU mortality when sharing sensitive patient data between hospitals is not possible.
Multi-label Classification using Labels as Hidden Nodes
Jul 18, 2017


Competitive methods for multi-label classification typically invest in learning labels together. To do so in a beneficial way, analysis of label dependence is often seen as a fundamental step, separate and prior to constructing a classifier. Some methods invest up to hundreds of times more computational effort in building dependency models, than training the final classifier itself. We extend some recent discussion in the literature and provide a deeper analysis, namely, developing the view that label dependence is often introduced by an inadequate base classifier, rather than being inherent to the data or underlying concept; showing how even an exhaustive analysis of label dependence may not lead to an optimal classification structure. Viewing labels as additional features (a transformation of the input), we create neural-network inspired novel methods that remove the emphasis of a prior dependency structure. Our methods have an important advantage particular to multi-label data: they leverage labels to create effective units in middle layers, rather than learning these units from scratch in an unsupervised fashion with gradient-based methods. Results are promising. The methods we propose perform competitively, and also have very important qualities of scalability.
Multi-label Methods for Prediction with Sequential Data
Sep 29, 2016
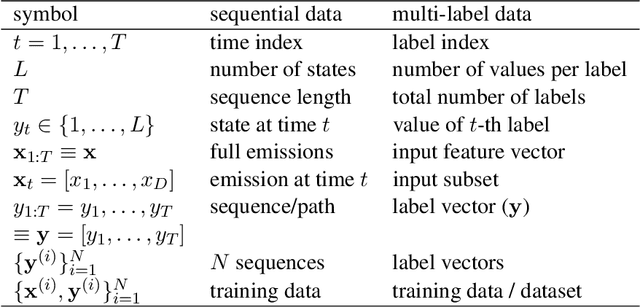
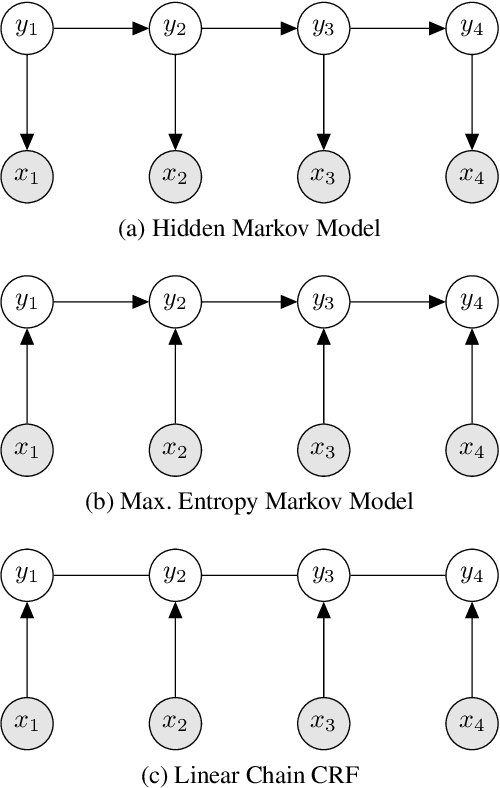

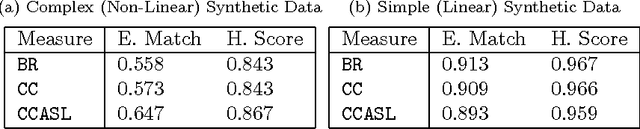
The number of methods available for classification of multi-label data has increased rapidly over recent years, yet relatively few links have been made with the related task of classification of sequential data. If labels indices are considered as time indices, the problems can often be seen as equivalent. In this paper we detect and elaborate on connections between multi-label methods and Markovian models, and study the suitability of multi-label methods for prediction in sequential data. From this study we draw upon the most suitable techniques from the area and develop two novel competitive approaches which can be applied to either kind of data. We carry out an empirical evaluation investigating performance on real-world sequential-prediction tasks: electricity demand, and route prediction. As well as showing that several popular multi-label algorithms are in fact easily applicable to sequencing tasks, our novel approaches, which benefit from a unified view of these areas, prove very competitive against established methods.