 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Classification using Labels as Hidden Nodes
Paper and Code



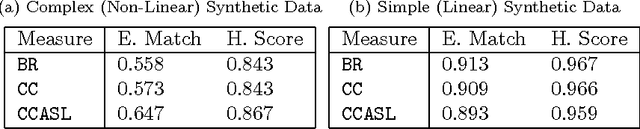
Competitive methods for multi-label classification typically invest in learning labels together. To do so in a beneficial way, analysis of label dependence is often seen as a fundamental step, separate and prior to constructing a classifier. Some methods invest up to hundreds of times more computational effort in building dependency models, than training the final classifier itself. We extend some recent discussion in the literature and provide a deeper analysis, namely, developing the view that label dependence is often introduced by an inadequate base classifier, rather than being inherent to the data or underlying concept; showing how even an exhaustive analysis of label dependence may not lead to an optimal classification structure. Viewing labels as additional features (a transformation of the input), we create neural-network inspired novel methods that remove the emphasis of a prior dependency structure. Our methods have an important advantage particular to multi-label data: they leverage labels to create effective units in middle layers, rather than learning these units from scratch in an unsupervised fashion with gradient-based methods. Results are promising. The methods we propose perform competitively, and also have very important qualities of scalability.