 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCastor: Competing shapelets for fast and accurate time series classification
Mar 19, 2024



Shapelets are discriminative subsequences, originally embedded in shapelet-based decision trees but have since been extended to shapelet-based transformations. We propose Castor, a simple, efficient, and accurate time series classification algorithm that utilizes shapelets to transform time series. The transformation organizes shapelets into groups with varying dilation and allows the shapelets to compete over the time context to construct a diverse feature representation. By organizing the shapelets into groups, we enable the transformation to transition between levels of competition, resulting in methods that more closely resemble distance-based transformations or dictionary-based transformations. We demonstrate, through an extensive empirical investigation, that Castor yields transformations that result in classifiers that are significantly more accurate than several state-of-the-art classifiers. In an extensive ablation study, we examine the effect of choosing hyperparameters and suggest accurate and efficient default values.
Counterfactual Explanations for Time Series Forecasting
Oct 12, 2023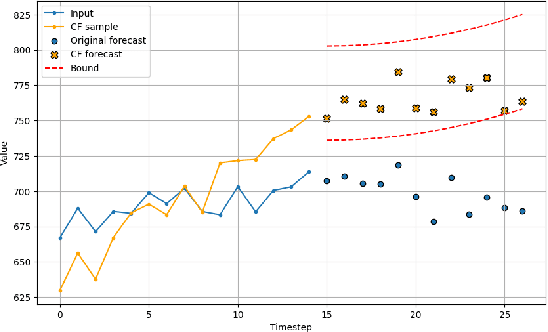
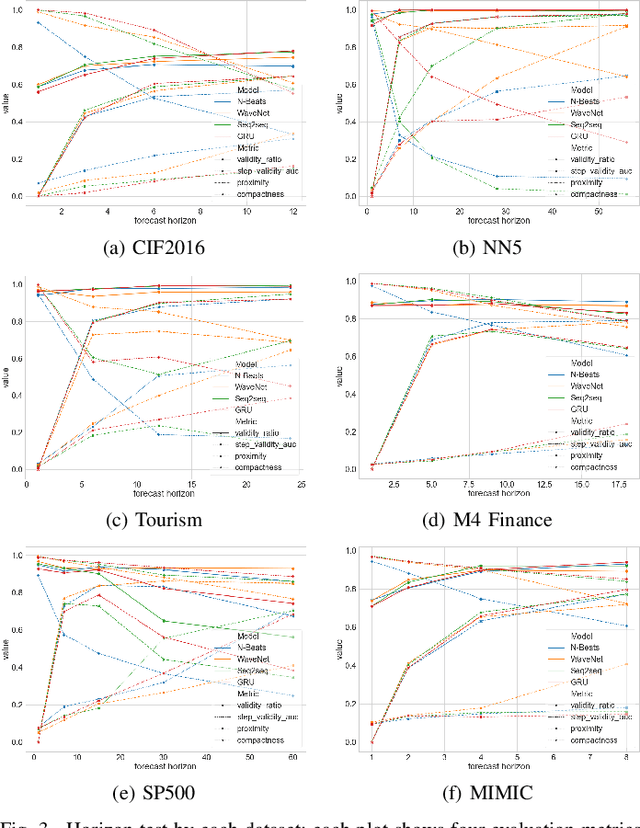
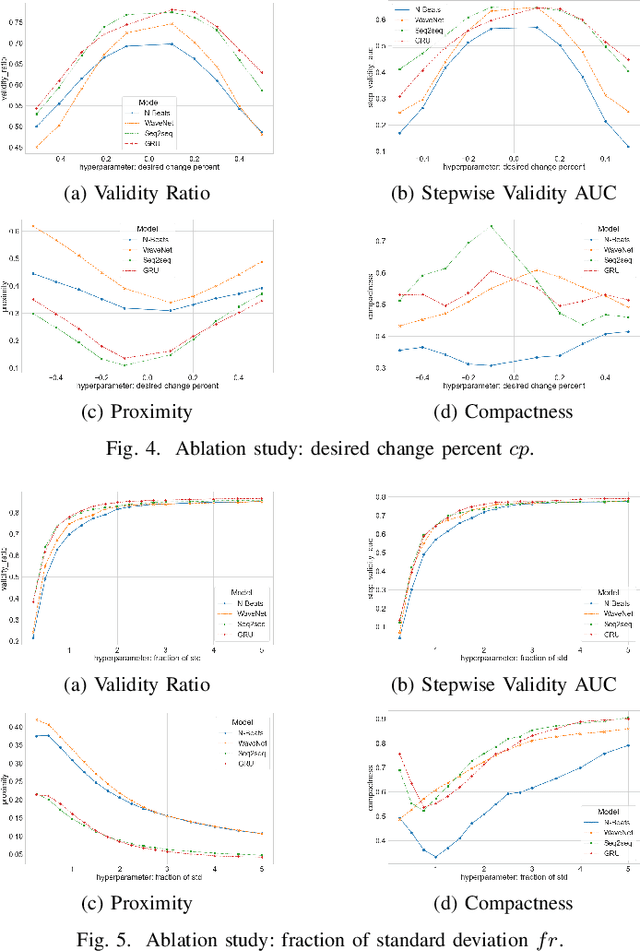
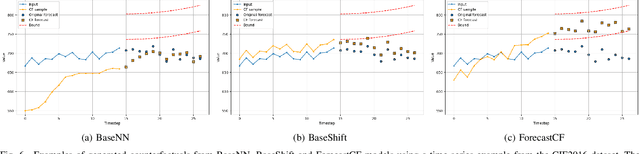
Among recent developments in time series forecasting methods, deep forecasting models have gained popularity as they can utilize hidden feature patterns in time series to improve forecasting performance. Nevertheless, the majority of current deep forecasting models are opaque, hence making it challenging to interpret the results. While counterfactual explanations have been extensively employed as a post-hoc approach for explaining classification models, their application to forecasting models still remains underexplored. In this paper, we formulate the novel problem of counterfactual generation for time series forecasting, and propose an algorithm, called ForecastCF, that solves the problem by applying gradient-based perturbations to the original time series. ForecastCF guides the perturbations by applying constraints to the forecasted values to obtain desired prediction outcomes. We experimentally evaluate ForecastCF using four state-of-the-art deep model architectures and compare to two baselines. Our results show that ForecastCF outperforms the baseline in terms of counterfactual validity and data manifold closeness. Overall, our findings suggest that ForecastCF can generate meaningful and relevant counterfactual explanations for various forecasting tasks.
Code quality assessment using transformers
Sep 17, 2023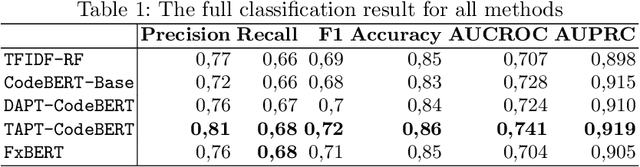

Automatically evaluate the correctness of programming assignments is rather straightforward using unit and integration tests. However, programming tasks can be solved in multiple ways, many of which, although correct, are inelegant. For instance, excessive branching, poor naming or repetitiveness make the code hard to understand and maintain. These subjective qualities of code are hard to automatically assess using current techniques. In this work we investigate the use of CodeBERT to automatically assign quality score to Java code. We experiment with different models and training paradigms. We explore the accuracy of the models on a novel dataset for code quality assessment. Finally, we assess the quality of the predictions using saliency maps. We find that code quality to some extent is predictable and that transformer based models using task adapted pre-training can solve the task more efficiently than other techniques.
Distributional Data Augmentation Methods for Low Resource Language
Sep 09, 2023Text augmentation is a technique for constructing synthetic data from an under-resourced corpus to improve predictive performance. Synthetic data generation is common in numerous domains. However, recently text augmentation has emerged in natural language processing (NLP) to improve downstream tasks. One of the current state-of-the-art text augmentation techniques is easy data augmentation (EDA), which augments the training data by injecting and replacing synonyms and randomly permuting sentences. One major obstacle with EDA is the need for versatile and complete synonym dictionaries, which cannot be easily found in low-resource languages. To improve the utility of EDA, we propose two extensions, easy distributional data augmentation (EDDA) and type specific similar word replacement (TSSR), which uses semantic word context information and part-of-speech tags for word replacement and augmentation. In an extensive empirical evaluation, we show the utility of the proposed methods, measured by F1 score, on two representative datasets in Swedish as an example of a low-resource language. With the proposed methods, we show that augmented data improve classification performances in low-resource settings.