 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode quality assessment using transformers
Sep 17, 2023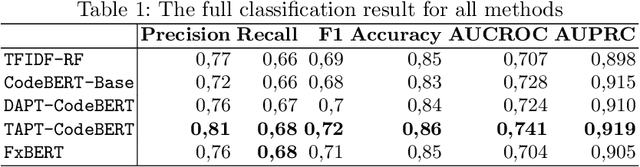

Automatically evaluate the correctness of programming assignments is rather straightforward using unit and integration tests. However, programming tasks can be solved in multiple ways, many of which, although correct, are inelegant. For instance, excessive branching, poor naming or repetitiveness make the code hard to understand and maintain. These subjective qualities of code are hard to automatically assess using current techniques. In this work we investigate the use of CodeBERT to automatically assign quality score to Java code. We experiment with different models and training paradigms. We explore the accuracy of the models on a novel dataset for code quality assessment. Finally, we assess the quality of the predictions using saliency maps. We find that code quality to some extent is predictable and that transformer based models using task adapted pre-training can solve the task more efficiently than other techniques.
Distributional Data Augmentation Methods for Low Resource Language
Sep 09, 2023Text augmentation is a technique for constructing synthetic data from an under-resourced corpus to improve predictive performance. Synthetic data generation is common in numerous domains. However, recently text augmentation has emerged in natural language processing (NLP) to improve downstream tasks. One of the current state-of-the-art text augmentation techniques is easy data augmentation (EDA), which augments the training data by injecting and replacing synonyms and randomly permuting sentences. One major obstacle with EDA is the need for versatile and complete synonym dictionaries, which cannot be easily found in low-resource languages. To improve the utility of EDA, we propose two extensions, easy distributional data augmentation (EDDA) and type specific similar word replacement (TSSR), which uses semantic word context information and part-of-speech tags for word replacement and augmentation. In an extensive empirical evaluation, we show the utility of the proposed methods, measured by F1 score, on two representative datasets in Swedish as an example of a low-resource language. With the proposed methods, we show that augmented data improve classification performances in low-resource settings.