 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode quality assessment using transformers
Paper and Code
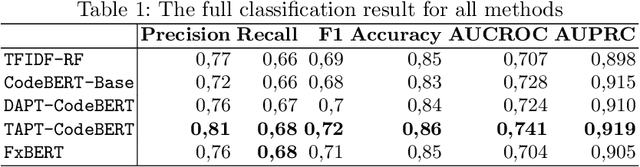

Automatically evaluate the correctness of programming assignments is rather straightforward using unit and integration tests. However, programming tasks can be solved in multiple ways, many of which, although correct, are inelegant. For instance, excessive branching, poor naming or repetitiveness make the code hard to understand and maintain. These subjective qualities of code are hard to automatically assess using current techniques. In this work we investigate the use of CodeBERT to automatically assign quality score to Java code. We experiment with different models and training paradigms. We explore the accuracy of the models on a novel dataset for code quality assessment. Finally, we assess the quality of the predictions using saliency maps. We find that code quality to some extent is predictable and that transformer based models using task adapted pre-training can solve the task more efficiently than other techniques.