 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogSigma at SemEval-2026 Task 3: Uncertainty-Weighted Multitask Learning for Dimensional Aspect-Based Sentiment Analysis
Mar 26, 2026This paper describes LogSigma, our system for SemEval-2026 Task 3: Dimensional Aspect-Based Sentiment Analysis (DimABSA). Unlike traditional Aspect-Based Sentiment Analysis (ABSA), which predicts discrete sentiment labels, DimABSA requires predicting continuous Valence and Arousal (VA) scores on a 1-9 scale. A central challenge is that Valence and Arousal differ in prediction difficulty across languages and domains. We address this using learned homoscedastic uncertainty, where the model learns task-specific log-variance parameters to automatically balance each regression objective during training. Combined with language-specific encoders and multi-seed ensembling, LogSigma achieves 1st place on five datasets across both tracks. The learned variance weights vary substantially across languages due to differing Valence-Arousal difficulty profiles-from 0.66x for German to 2.18x for English-demonstrating that optimal task balancing is language-dependent and cannot be determined a priori.
DimABSA: Building Multilingual and Multidomain Datasets for Dimensional Aspect-Based Sentiment Analysis
Jan 30, 2026Aspect-Based Sentiment Analysis (ABSA) focuses on extracting sentiment at a fine-grained aspect level and has been widely applied across real-world domains. However, existing ABSA research relies on coarse-grained categorical labels (e.g., positive, negative), which limits its ability to capture nuanced affective states. To address this limitation, we adopt a dimensional approach that represents sentiment with continuous valence-arousal (VA) scores, enabling fine-grained analysis at both the aspect and sentiment levels. To this end, we introduce DimABSA, the first multilingual, dimensional ABSA resource annotated with both traditional ABSA elements (aspect terms, aspect categories, and opinion terms) and newly introduced VA scores. This resource contains 76,958 aspect instances across 42,590 sentences, spanning six languages and four domains. We further introduce three subtasks that combine VA scores with different ABSA elements, providing a bridge from traditional ABSA to dimensional ABSA. Given that these subtasks involve both categorical and continuous outputs, we propose a new unified metric, continuous F1 (cF1), which incorporates VA prediction error into standard F1. We provide a comprehensive benchmark using both prompted and fine-tuned large language models across all subtasks. Our results show that DimABSA is a challenging benchmark and provides a foundation for advancing multilingual dimensional ABSA.
DimStance: Multilingual Datasets for Dimensional Stance Analysis
Jan 29, 2026Stance detection is an established task that classifies an author's attitude toward a specific target into categories such as Favor, Neutral, and Against. Beyond categorical stance labels, we leverage a long-established affective science framework to model stance along real-valued dimensions of valence (negative-positive) and arousal (calm-active). This dimensional approach captures nuanced affective states underlying stance expressions, enabling fine-grained stance analysis. To this end, we introduce DimStance, the first dimensional stance resource with valence-arousal (VA) annotations. This resource comprises 11,746 target aspects in 7,365 texts across five languages (English, German, Chinese, Nigerian Pidgin, and Swahili) and two domains (politics and environmental protection). To facilitate the evaluation of stance VA prediction, we formulate the dimensional stance regression task, analyze cross-lingual VA patterns, and benchmark pretrained and large language models under regression and prompting settings. Results show competitive performance of fine-tuned LLM regressors, persistent challenges in low-resource languages, and limitations of token-based generation. DimStance provides a foundation for multilingual, emotion-aware, stance analysis and benchmarking.
Stay Focused: Problem Drift in Multi-Agent Debate
Feb 26, 2025Multi-agent debate - multiple instances of large language models discussing problems in turn-based interaction - has shown promise for solving knowledge and reasoning tasks. However, these methods show limitations, particularly when scaling them to longer reasoning chains. In this study, we unveil a new issue of multi-agent debate: discussions drift away from the initial problem over multiple turns. We define this phenomenon as problem drift and quantify its presence across ten tasks (i.e., three generative, three knowledge, three reasoning, and one instruction-following task). To identify the reasons for this issue, we perform a human study with eight experts on discussions suffering from problem drift, who find the most common issues are a lack of progress (35% of cases), low-quality feedback (26% of cases), and a lack of clarity (25% of cases). To systematically address the issue of problem drift, we propose DRIFTJudge, a method based on LLM-as-a-judge, to detect problem drift at test-time. We further propose DRIFTPolicy, a method to mitigate 31% of problem drift cases. Our study can be seen as a first step to understanding a key limitation of multi-agent debate, highlighting pathways for improving their effectiveness in the future.
Voting or Consensus? Decision-Making in Multi-Agent Debate
Feb 26, 2025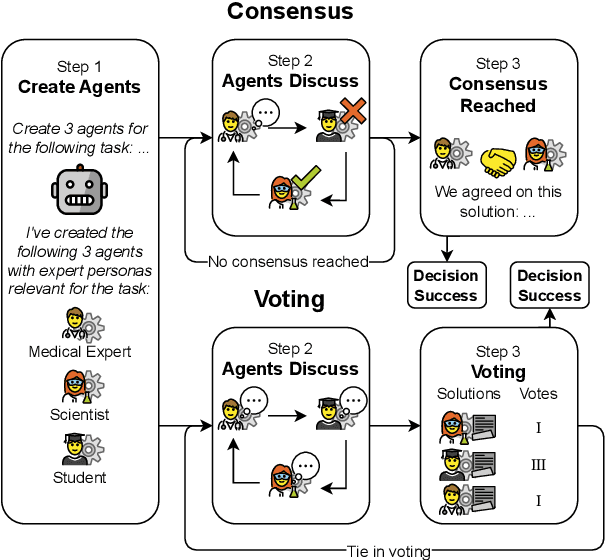
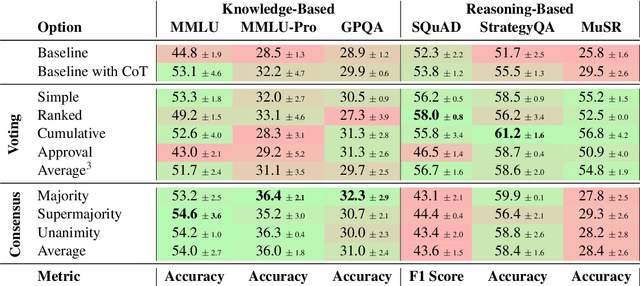
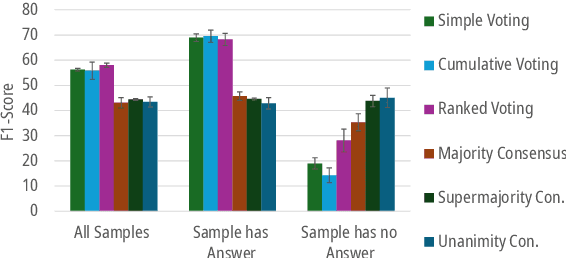

Much of the success of multi-agent debates depends on carefully choosing the right parameters. Among them, the decision-making protocol stands out. Systematic comparison of decision protocols is difficult because studies alter multiple discussion parameters beyond the protocol. So far, it has been largely unknown how decision-making addresses the challenges of different tasks. This work systematically evaluates the impact of seven decision protocols (e.g., majority voting, unanimity consensus). We change only one variable at a time (i.e., decision protocol) to analyze how different methods affect the collaboration between agents and test different protocols on knowledge (MMLU, MMLU-Pro, GPQA) and reasoning datasets (StrategyQA, MuSR, SQuAD 2.0). Our results show that voting protocols improve performance by 13.2% in reasoning tasks and consensus protocols by 2.8% in knowledge tasks over the other decision protocol. Increasing the number of agents improves performance, while more discussion rounds before voting reduces it. To improve decision-making by increasing answer diversity, we propose two new methods, All-Agents Drafting (AAD) and Collective Improvement (CI). Our methods improve task performance by up to 3.3% with AAD and up to 7.4% with CI. This work demonstrates the importance of decision-making in multi-agent debates beyond scaling.
Multi-Agent Large Language Models for Conversational Task-Solving
Oct 30, 2024In an era where single large language models have dominated the landscape of artificial intelligence for years, multi-agent systems arise as new protagonists in conversational task-solving. While previous studies have showcased their potential in reasoning tasks and creative endeavors, an analysis of their limitations concerning the conversational paradigms and the impact of individual agents is missing. It remains unascertained how multi-agent discussions perform across tasks of varying complexity and how the structure of these conversations influences the process. To fill that gap, this work systematically evaluates multi-agent systems across various discussion paradigms, assessing their strengths and weaknesses in both generative tasks and question-answering tasks. Alongside the experiments, I propose a taxonomy of 20 multi-agent research studies from 2022 to 2024, followed by the introduction of a framework for deploying multi-agent LLMs in conversational task-solving. I demonstrate that while multi-agent systems excel in complex reasoning tasks, outperforming a single model by leveraging expert personas, they fail on basic tasks. Concretely, I identify three challenges that arise: 1) While longer discussions enhance reasoning, agents fail to maintain conformity to strict task requirements, which leads to problem drift, making shorter conversations more effective for basic tasks. 2) Prolonged discussions risk alignment collapse, raising new safety concerns for these systems. 3) I showcase discussion monopolization through long generations, posing the problem of fairness in decision-making for tasks like summarization. This work uncovers both the potential and challenges that arise with multi-agent interaction and varying conversational paradigms, providing insights into how future research could improve the efficiency, performance, and safety of multi-agent LLMs.
Text Generation: A Systematic Literature Review of Tasks, Evaluation, and Challenges
May 24, 2024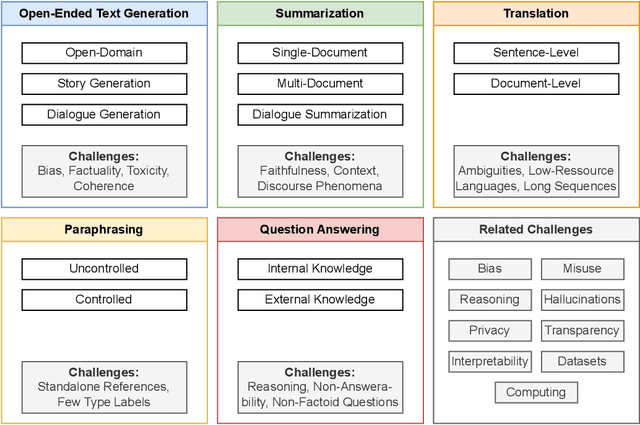

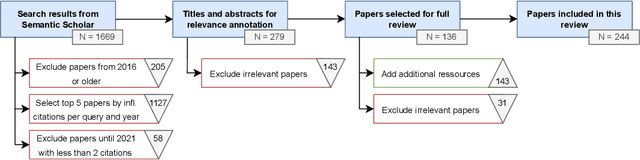
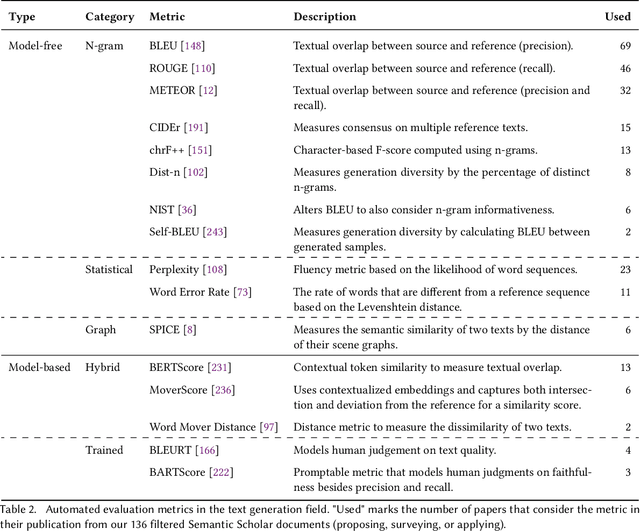
Text generation has become more accessible than ever, and the increasing interest in these systems, especially those using large language models, has spurred an increasing number of related publications. We provide a systematic literature review comprising 244 selected papers between 2017 and 2024. This review categorizes works in text generation into five main tasks: open-ended text generation, summarization, translation, paraphrasing, and question answering. For each task, we review their relevant characteristics, sub-tasks, and specific challenges (e.g., missing datasets for multi-document summarization, coherence in story generation, and complex reasoning for question answering). Additionally, we assess current approaches for evaluating text generation systems and ascertain problems with current metrics. Our investigation shows nine prominent challenges common to all tasks and sub-tasks in recent text generation publications: bias, reasoning, hallucinations, misuse, privacy, interpretability, transparency, datasets, and computing. We provide a detailed analysis of these challenges, their potential solutions, and which gaps still require further engagement from the community. This systematic literature review targets two main audiences: early career researchers in natural language processing looking for an overview of the field and promising research directions, as well as experienced researchers seeking a detailed view of tasks, evaluation methodologies, open challenges, and recent mitigation strategies.
Paraphrase Detection: Human vs. Machine Content
Mar 24, 2023The growing prominence of large language models, such as GPT-4 and ChatGPT, has led to increased concerns over academic integrity due to the potential for machine-generated content and paraphrasing. Although studies have explored the detection of human- and machine-paraphrased content, the comparison between these types of content remains underexplored. In this paper, we conduct a comprehensive analysis of various datasets commonly employed for paraphrase detection tasks and evaluate an array of detection methods. Our findings highlight the strengths and limitations of different detection methods in terms of performance on individual datasets, revealing a lack of suitable machine-generated datasets that can be aligned with human expectations. Our main finding is that human-authored paraphrases exceed machine-generated ones in terms of difficulty, diversity, and similarity implying that automatically generated texts are not yet on par with human-level performance. Transformers emerged as the most effective method across datasets with TF-IDF excelling on semantically diverse corpora. Additionally, we identify four datasets as the most diverse and challenging for paraphrase detection.