 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Generation: A Systematic Literature Review of Tasks, Evaluation, and Challenges
Paper and Code
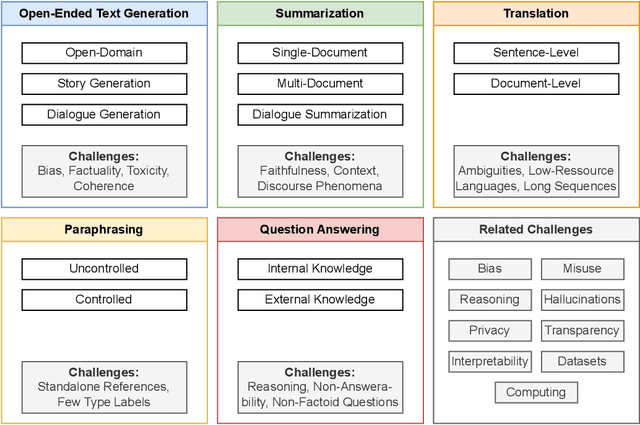

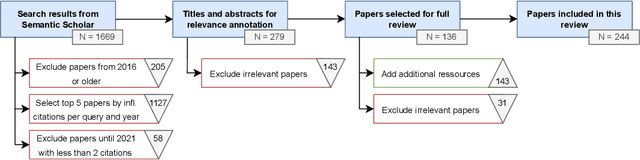
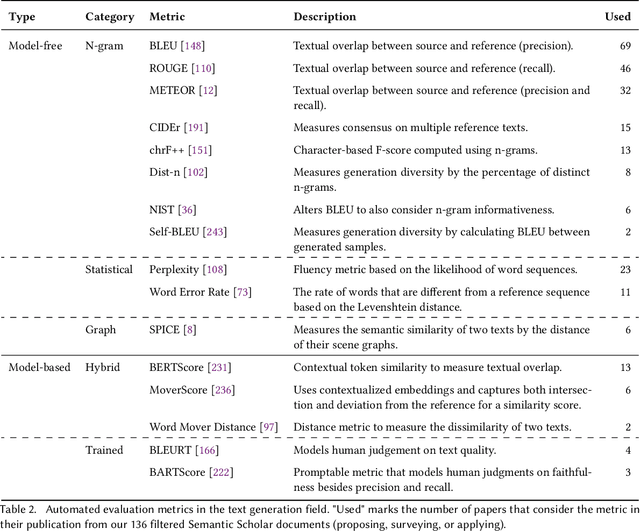
Text generation has become more accessible than ever, and the increasing interest in these systems, especially those using large language models, has spurred an increasing number of related publications. We provide a systematic literature review comprising 244 selected papers between 2017 and 2024. This review categorizes works in text generation into five main tasks: open-ended text generation, summarization, translation, paraphrasing, and question answering. For each task, we review their relevant characteristics, sub-tasks, and specific challenges (e.g., missing datasets for multi-document summarization, coherence in story generation, and complex reasoning for question answering). Additionally, we assess current approaches for evaluating text generation systems and ascertain problems with current metrics. Our investigation shows nine prominent challenges common to all tasks and sub-tasks in recent text generation publications: bias, reasoning, hallucinations, misuse, privacy, interpretability, transparency, datasets, and computing. We provide a detailed analysis of these challenges, their potential solutions, and which gaps still require further engagement from the community. This systematic literature review targets two main audiences: early career researchers in natural language processing looking for an overview of the field and promising research directions, as well as experienced researchers seeking a detailed view of tasks, evaluation methodologies, open challenges, and recent mitigation strategies.