 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiecing Together Cross-Document Coreference Resolution Datasets: Systematic Dataset Analysis and Unification
Mar 03, 2026Research in CDCR remains fragmented due to heterogeneous dataset formats, varying annotation standards, and the predominance of the CDCR definition as the event coreference resolution (ECR). To address these challenges, we introduce uCDCR, a unified dataset that consolidates diverse publicly available English CDCR corpora across various domains into a consistent format, which we analyze with standardized metrics and evaluation protocols. uCDCR incorporates both entity and event coreference, corrects known inconsistencies, and enriches datasets with missing attributes to facilitate reproducible research. We establish a cohesive framework for fair, interpretable, and cross-dataset analysis in CDCR and compare the datasets on their lexical properties, e.g., lexical composition of the annotated mentions, lexical diversity and ambiguity metrics, discuss the annotation rules and principles that lead to high lexical diversity, and examine how these metrics influence performance on the same-head-lemma baseline. Our dataset analysis shows that ECB+, the state-of-the-art benchmark for CDCR, has one of the lowest lexical diversities, and its CDCR complexity, measured by the same-head-lemma baseline, lies in the middle among all uCDCR datasets. Moreover, comparing document and mention distributions between ECB+ and uCDCR shows that using all uCDCR datasets for model training and evaluation will improve the generalizability of CDCR models. Finally, the almost identical performance on the same-head-lemma baseline, separately applied to events and entities, shows that resolving both types is a complex task and should not be steered toward ECR alone. The uCDCR dataset is available at https://huggingface.co/datasets/AnZhu/uCDCR, and the code for parsing, analyzing, and scoring the dataset is available at https://github.com/anastasia-zhukova/uCDCR.
Diverse Word Choices, Same Reference: Annotating Lexically-Rich Cross-Document Coreference
Feb 19, 2026Cross-document coreference resolution (CDCR) identifies and links mentions of the same entities and events across related documents, enabling content analysis that aggregates information at the level of discourse participants. However, existing datasets primarily focus on event resolution and employ a narrow definition of coreference, which limits their effectiveness in analyzing diverse and polarized news coverage where wording varies widely. This paper proposes a revised CDCR annotation scheme of the NewsWCL50 dataset, treating coreference chains as discourse elements (DEs) and conceptual units of analysis. The approach accommodates both identity and near-identity relations, e.g., by linking "the caravan" - "asylum seekers" - "those contemplating illegal entry", allowing models to capture lexical diversity and framing variation in media discourse, while maintaining the fine-grained annotation of DEs. We reannotate the NewsWCL50 and a subset of ECB+ using a unified codebook and evaluate the new datasets through lexical diversity metrics and a same-head-lemma baseline. The results show that the reannotated datasets align closely, falling between the original ECB+ and NewsWCL50, thereby supporting balanced and discourse-aware CDCR research in the news domain.
Contrastive Learning Using Graph Embeddings for Domain Adaptation of Language Models in the Process Industry
Oct 06, 2025Recent trends in NLP utilize knowledge graphs (KGs) to enhance pretrained language models by incorporating additional knowledge from the graph structures to learn domain-specific terminology or relationships between documents that might otherwise be overlooked. This paper explores how SciNCL, a graph-aware neighborhood contrastive learning methodology originally designed for scientific publications, can be applied to the process industry domain, where text logs contain crucial information about daily operations and are often structured as sparse KGs. Our experiments demonstrate that language models fine-tuned with triplets derived from GE outperform a state-of-the-art mE5-large text encoder by 9.8-14.3% (5.4-8.0p) on the proprietary process industry text embedding benchmark (PITEB) while being 3-5 times smaller in size.
Link Prediction for Event Logs in the Process Industry
Aug 12, 2025Knowledge management (KM) is vital in the process industry for optimizing operations, ensuring safety, and enabling continuous improvement through effective use of operational data and past insights. A key challenge in this domain is the fragmented nature of event logs in shift books, where related records, e.g., entries documenting issues related to equipment or processes and the corresponding solutions, may remain disconnected. This fragmentation hinders the recommendation of previous solutions to the users. To address this problem, we investigate record linking (RL) as link prediction, commonly studied in graph-based machine learning, by framing it as a cross-document coreference resolution (CDCR) task enhanced with natural language inference (NLI) and semantic text similarity (STS) by shifting it into the causal inference (CI). We adapt CDCR, traditionally applied in the news domain, into an RL model to operate at the passage level, similar to NLI and STS, while accommodating the process industry's specific text formats, which contain unstructured text and structured record attributes. Our RL model outperformed the best versions of NLI- and STS-driven baselines by 28% (11.43 points) and 27% (11.21 points), respectively. Our work demonstrates how domain adaptation of the state-of-the-art CDCR models, enhanced with reasoning capabilities, can be effectively tailored to the process industry, improving data quality and connectivity in shift logs.
Efficient Domain-adaptive Continual Pretraining for the Process Industry in the German Language
Apr 30, 2025Domain-adaptive continual pretraining (DAPT) is a state-of-the-art technique that further trains a language model (LM) on its pretraining task, e.g., language masking. Although popular, it requires a significant corpus of domain-related data, which is difficult to obtain for specific domains in languages other than English, such as the process industry in the German language. This paper introduces an efficient approach called ICL-augmented pretraining or ICL-APT that leverages in-context learning (ICL) and k-nearest neighbors (kNN) to augment target data with domain-related and in-domain texts, significantly reducing GPU time while maintaining strong model performance. Our results show that this approach performs better than traditional DAPT by 3.5 points of the average IR metrics (e.g., mAP, MRR, and nDCG) and requires almost 4 times less computing time, providing a cost-effective solution for industries with limited computational capacity. The findings highlight the broader applicability of this framework to other low-resource industries, making NLP-based solutions more accessible and feasible in production environments.
Automated Collection of Evaluation Dataset for Semantic Search in Low-Resource Domain Language
Dec 13, 2024Domain-specific languages that use a lot of specific terminology often fall into the category of low-resource languages. Collecting test datasets in a narrow domain is time-consuming and requires skilled human resources with domain knowledge and training for the annotation task. This study addresses the challenge of automated collecting test datasets to evaluate semantic search in low-resource domain-specific German language of the process industry. Our approach proposes an end-to-end annotation pipeline for automated query generation to the score reassessment of query-document pairs. To overcome the lack of text encoders trained in the German chemistry domain, we explore a principle of an ensemble of "weak" text encoders trained on common knowledge datasets. We combine individual relevance scores from diverse models to retrieve document candidates and relevance scores generated by an LLM, aiming to achieve consensus on query-document alignment. Evaluation results demonstrate that the ensemble method significantly improves alignment with human-assigned relevance scores, outperforming individual models in both inter-coder agreement and accuracy metrics. These findings suggest that ensemble learning can effectively adapt semantic search systems for specialized, low-resource languages, offering a practical solution to resource limitations in domain-specific contexts.
Domain Adaptation of Multilingual Semantic Search -- Literature Review
Feb 05, 2024


This literature review gives an overview of current approaches to perform domain adaptation in a low-resource and approaches to perform multilingual semantic search in a low-resource setting. We developed a new typology to cluster domain adaptation approaches based on the part of dense textual information retrieval systems, which they adapt, focusing on how to combine them efficiently. We also explore the possibilities of combining multilingual semantic search with domain adaptation approaches for dense retrievers in a low-resource setting.
Generative User-Experience Research for Developing Domain-specific Natural Language Processing Applications
Jun 28, 2023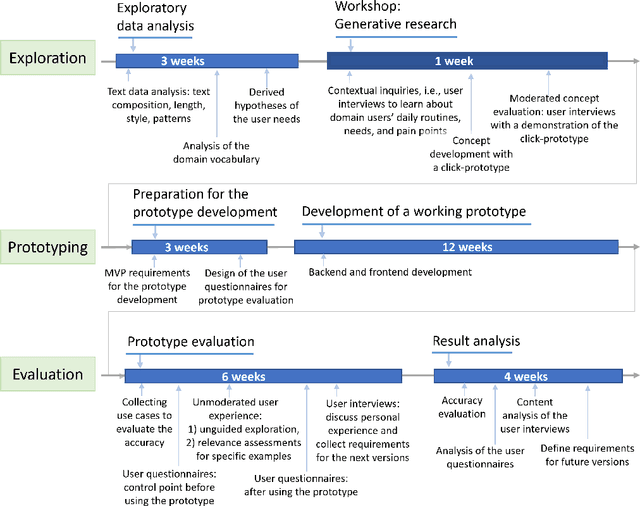
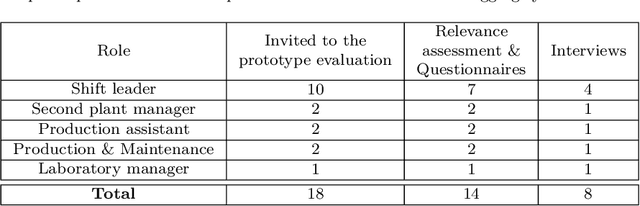


User experience (UX) is a part of human-computer interaction (HCI) research and focuses on increasing intuitiveness, transparency, simplicity, and trust for system users. Most of the UX research for machine learning (ML) or natural language processing (NLP) focuses on a data-driven methodology, i.e., it fails to focus on users' requirements, and engages domain users mainly for usability evaluation. Moreover, more typical UX methods tailor the systems towards user usability, unlike learning about the user needs first. The paper proposes a methodology for integrating generative UX research into developing domain NLP applications. Generative UX research employs domain users at the initial stages of prototype development, i.e., ideation and concept evaluation, and the last stage for evaluating the change in user value. In the case study, we report the full-cycle prototype development of a domain-specific semantic search for daily operations in the process industry. Our case study shows that involving domain experts increases their interest and trust in the final NLP application. Moreover, we show that synergetic UX+NLP research efficiently considers data- and user-driven opportunities and constraints, which can be crucial for NLP applications in narrow domains
ANEA: Automated (Named) Entity Annotation for German Domain-Specific Texts
Dec 13, 2021


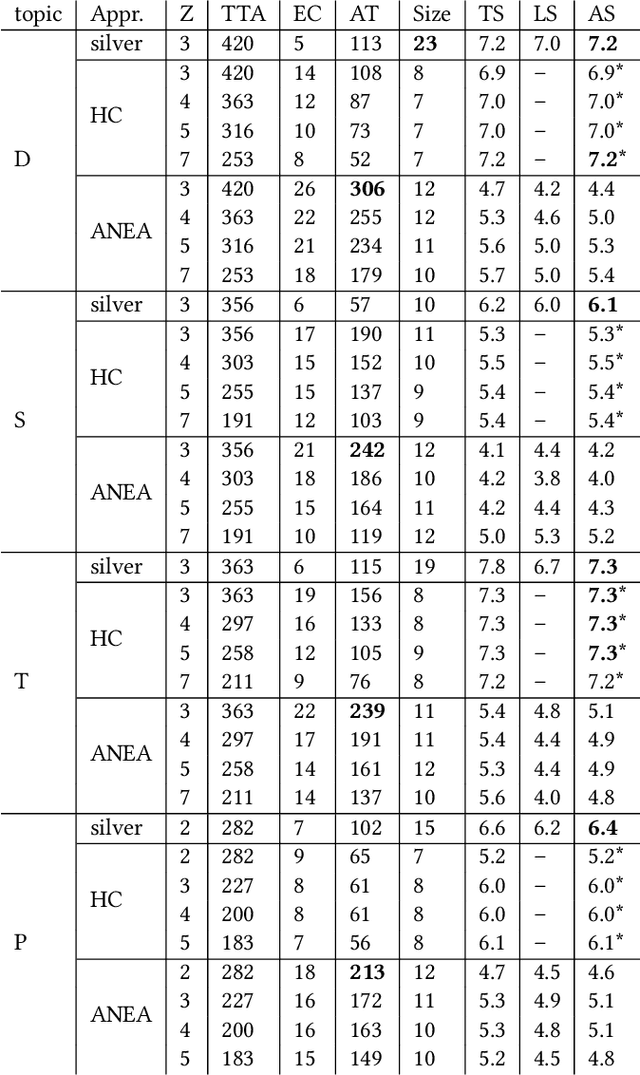
Named entity recognition (NER) is an important task that aims to resolve universal categories of named entities, e.g., persons, locations, organizations, and times. Despite its common and viable use in many use cases, NER is barely applicable in domains where general categories are suboptimal, such as engineering or medicine. To facilitate NER of domain-specific types, we propose ANEA, an automated (named) entity annotator to assist human annotators in creating domain-specific NER corpora for German text collections when given a set of domain-specific texts. In our evaluation, we find that ANEA automatically identifies terms that best represent the texts' content, identifies groups of coherent terms, and extracts and assigns descriptive labels to these groups, i.e., annotates text datasets into the domain (named) entities.
Newsalyze: Effective Communication of Person-Targeting Biases in News Articles
Oct 18, 2021



Media bias and its extreme form, fake news, can decisively affect public opinion. Especially when reporting on policy issues, slanted news coverage may strongly influence societal decisions, e.g., in democratic elections. Our paper makes three contributions to address this issue. First, we present a system for bias identification, which combines state-of-the-art methods from natural language understanding. Second, we devise bias-sensitive visualizations to communicate bias in news articles to non-expert news consumers. Third, our main contribution is a large-scale user study that measures bias-awareness in a setting that approximates daily news consumption, e.g., we present respondents with a news overview and individual articles. We not only measure the visualizations' effect on respondents' bias-awareness, but we can also pinpoint the effects on individual components of the visualizations by employing a conjoint design. Our bias-sensitive overviews strongly and significantly increase bias-awareness in respondents. Our study further suggests that our content-driven identification method detects groups of similarly slanted news articles due to substantial biases present in individual news articles. In contrast, the reviewed prior work rather only facilitates the visibility of biases, e.g., by distinguishing left- and right-wing outlets.