 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANEA: Automated (Named) Entity Annotation for German Domain-Specific Texts
Paper and Code



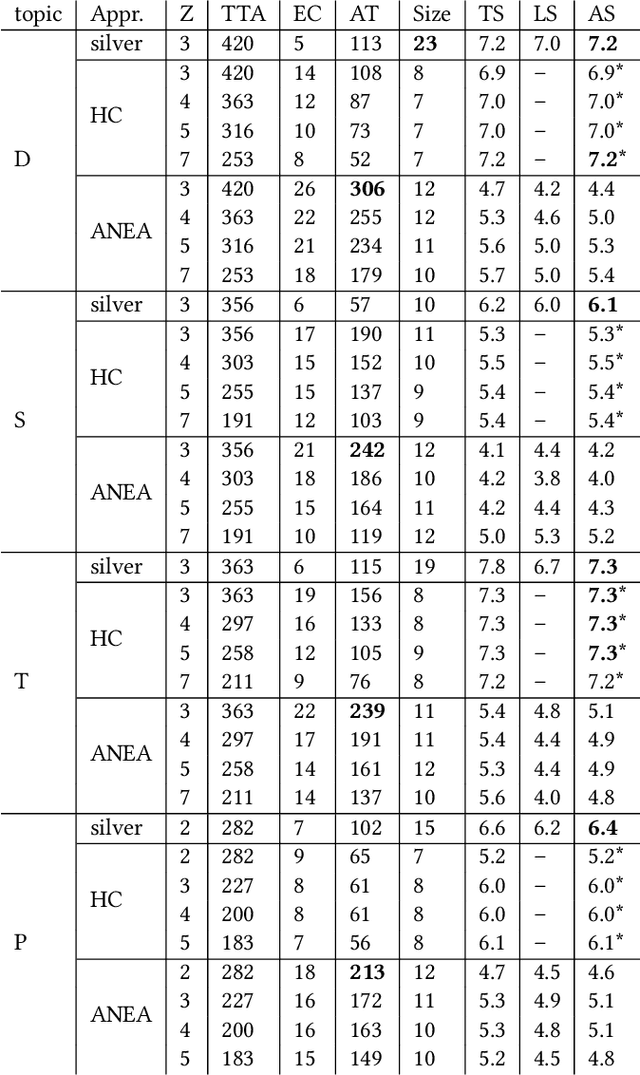
Named entity recognition (NER) is an important task that aims to resolve universal categories of named entities, e.g., persons, locations, organizations, and times. Despite its common and viable use in many use cases, NER is barely applicable in domains where general categories are suboptimal, such as engineering or medicine. To facilitate NER of domain-specific types, we propose ANEA, an automated (named) entity annotator to assist human annotators in creating domain-specific NER corpora for German text collections when given a set of domain-specific texts. In our evaluation, we find that ANEA automatically identifies terms that best represent the texts' content, identifies groups of coherent terms, and extracts and assigns descriptive labels to these groups, i.e., annotates text datasets into the domain (named) entities.