 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Word Choices, Same Reference: Annotating Lexically-Rich Cross-Document Coreference
Feb 19, 2026Cross-document coreference resolution (CDCR) identifies and links mentions of the same entities and events across related documents, enabling content analysis that aggregates information at the level of discourse participants. However, existing datasets primarily focus on event resolution and employ a narrow definition of coreference, which limits their effectiveness in analyzing diverse and polarized news coverage where wording varies widely. This paper proposes a revised CDCR annotation scheme of the NewsWCL50 dataset, treating coreference chains as discourse elements (DEs) and conceptual units of analysis. The approach accommodates both identity and near-identity relations, e.g., by linking "the caravan" - "asylum seekers" - "those contemplating illegal entry", allowing models to capture lexical diversity and framing variation in media discourse, while maintaining the fine-grained annotation of DEs. We reannotate the NewsWCL50 and a subset of ECB+ using a unified codebook and evaluate the new datasets through lexical diversity metrics and a same-head-lemma baseline. The results show that the reannotated datasets align closely, falling between the original ECB+ and NewsWCL50, thereby supporting balanced and discourse-aware CDCR research in the news domain.
Human-in-the-Loop Hate Speech Classification in a Multilingual Context
Dec 05, 2022



The shift of public debate to the digital sphere has been accompanied by a rise in online hate speech. While many promising approaches for hate speech classification have been proposed, studies often focus only on a single language, usually English, and do not address three key concerns: post-deployment performance, classifier maintenance and infrastructural limitations. In this paper, we introduce a new human-in-the-loop BERT-based hate speech classification pipeline and trace its development from initial data collection and annotation all the way to post-deployment. Our classifier, trained using data from our original corpus of over 422k examples, is specifically developed for the inherently multilingual setting of Switzerland and outperforms with its F1 score of 80.5 the currently best-performing BERT-based multilingual classifier by 5.8 F1 points in German and 3.6 F1 points in French. Our systematic evaluations over a 12-month period further highlight the vital importance of continuous, human-in-the-loop classifier maintenance to ensure robust hate speech classification post-deployment.
Assisted Text Annotation Using Active Learning to Achieve High Quality with Little Effort
Dec 15, 2021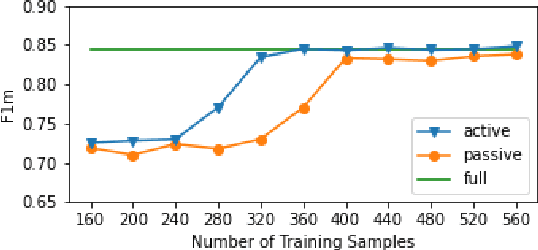
Large amounts of annotated data have become more important than ever, especially since the rise of deep learning techniques. However, manual annotations are costly. We propose a tool that enables researchers to create large, high-quality, annotated datasets with only a few manual annotations, thus strongly reducing annotation cost and effort. For this purpose, we combine an active learning (AL) approach with a pre-trained language model to semi-automatically identify annotation categories in the given text documents. To highlight our research direction's potential, we evaluate the approach on the task of identifying frames in news articles. Our preliminary results show that employing AL strongly reduces the number of annotations for correct classification of even these complex and subtle frames. On the framing dataset, the AL approach needs only 16.3\% of the annotations to reach the same performance as a model trained on the full dataset.
Newsalyze: Effective Communication of Person-Targeting Biases in News Articles
Oct 18, 2021



Media bias and its extreme form, fake news, can decisively affect public opinion. Especially when reporting on policy issues, slanted news coverage may strongly influence societal decisions, e.g., in democratic elections. Our paper makes three contributions to address this issue. First, we present a system for bias identification, which combines state-of-the-art methods from natural language understanding. Second, we devise bias-sensitive visualizations to communicate bias in news articles to non-expert news consumers. Third, our main contribution is a large-scale user study that measures bias-awareness in a setting that approximates daily news consumption, e.g., we present respondents with a news overview and individual articles. We not only measure the visualizations' effect on respondents' bias-awareness, but we can also pinpoint the effects on individual components of the visualizations by employing a conjoint design. Our bias-sensitive overviews strongly and significantly increase bias-awareness in respondents. Our study further suggests that our content-driven identification method detects groups of similarly slanted news articles due to substantial biases present in individual news articles. In contrast, the reviewed prior work rather only facilitates the visibility of biases, e.g., by distinguishing left- and right-wing outlets.
How to Effectively Identify and Communicate Person-Targeting Media Bias in Daily News Consumption?
Oct 18, 2021

Slanted news coverage strongly affects public opinion. This is especially true for coverage on politics and related issues, where studies have shown that bias in the news may influence elections and other collective decisions. Due to its viable importance, news coverage has long been studied in the social sciences, resulting in comprehensive models to describe it and effective yet costly methods to analyze it, such as content analysis. We present an in-progress system for news recommendation that is the first to automate the manual procedure of content analysis to reveal person-targeting biases in news articles reporting on policy issues. In a large-scale user study, we find very promising results regarding this interdisciplinary research direction. Our recommender detects and reveals substantial frames that are actually present in individual news articles. In contrast, prior work rather only facilitates the visibility of biases, e.g., by distinguishing left- and right-wing outlets. Further, our study shows that recommending news articles that differently frame an event significantly improves respondents' awareness of bias.
XCoref: Cross-document Coreference Resolution in the Wild
Sep 11, 2021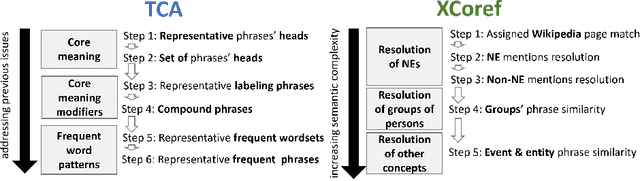



Datasets and methods for cross-document coreference resolution (CDCR) focus on events or entities with strict coreference relations. They lack, however, annotating and resolving coreference mentions with more abstract or loose relations that may occur when news articles report about controversial and polarized events. Bridging and loose coreference relations trigger associations that may lead to exposing news readers to bias by word choice and labeling. For example, coreferential mentions of "direct talks between U.S. President Donald Trump and Kim" such as "an extraordinary meeting following months of heated rhetoric" or "great chance to solve a world problem" form a more positive perception of this event. A step towards bringing awareness of bias by word choice and labeling is the reliable resolution of coreferences with high lexical diversity. We propose an unsupervised method named XCoref, which is a CDCR method that capably resolves not only previously prevalent entities, such as persons, e.g., "Donald Trump," but also abstractly defined concepts, such as groups of persons, "caravan of immigrants," events and actions, e.g., "marching to the U.S. border." In an extensive evaluation, we compare the proposed XCoref to a state-of-the-art CDCR method and a previous method TCA that resolves such complex coreference relations and find that XCoref outperforms these methods. Outperforming an established CDCR model shows that the new CDCR models need to be evaluated on semantically complex mentions with more loose coreference relations to indicate their applicability of models to resolve mentions in the "wild" of political news articles.
Concept Identification of Directly and Indirectly Related Mentions Referring to Groups of Persons
Jul 02, 2021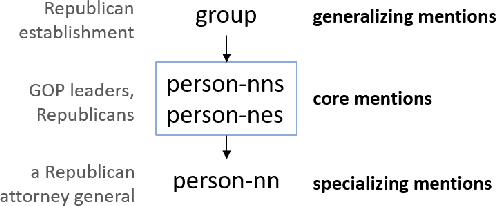
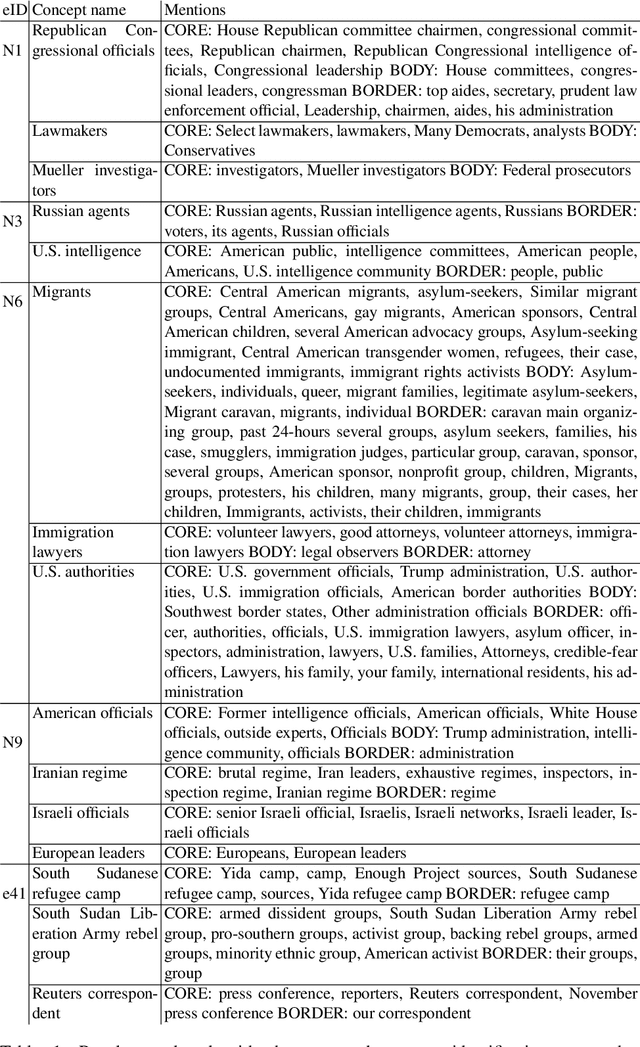
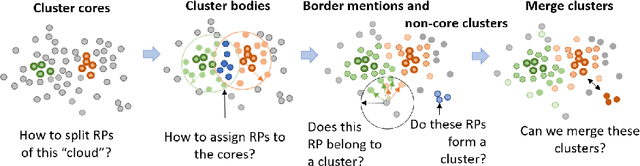
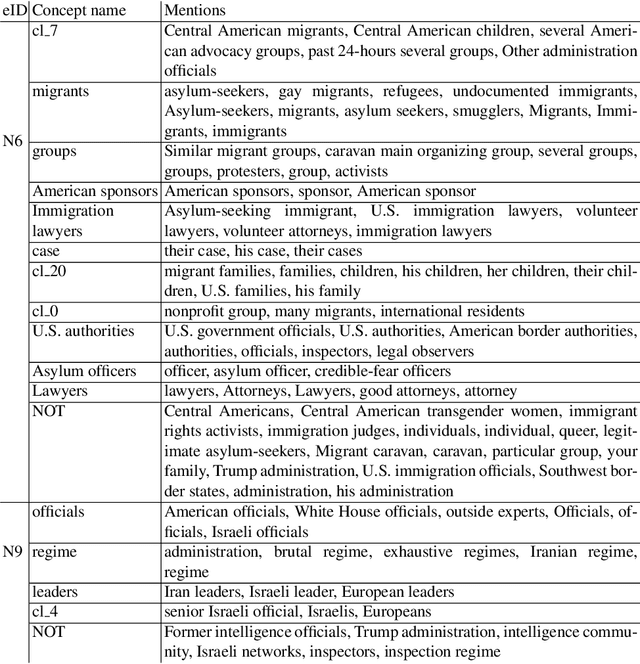
Unsupervised concept identification through clustering, i.e., identification of semantically related words and phrases, is a common approach to identify contextual primitives employed in various use cases, e.g., text dimension reduction, i.e., replace words with the concepts to reduce the vocabulary size, summarization, and named entity resolution. We demonstrate the first results of an unsupervised approach for the identification of groups of persons as actors extracted from a set of related articles. Specifically, the approach clusters mentions of groups of persons that act as non-named entity actors in the texts, e.g., "migrant families" = "asylum-seekers." Compared to our baseline, the approach keeps the mentions of the geopolitical entities separated, e.g., "Iran leaders" != "European leaders," and clusters (in)directly related mentions with diverse wording, e.g., "American officials" = "Trump Administration."
Towards Target-dependent Sentiment Classification in News Articles
May 20, 2021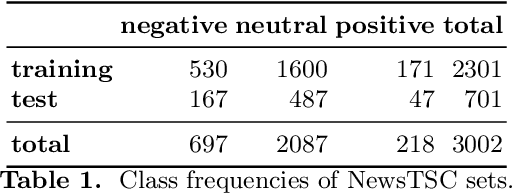
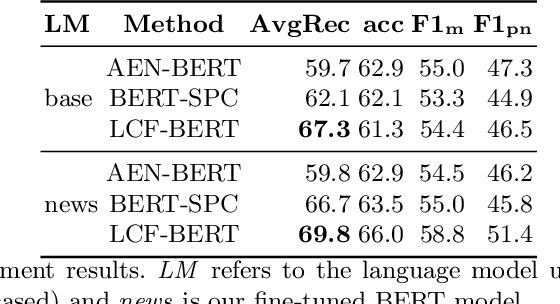
Extensive research on target-dependent sentiment classification (TSC) has led to strong classification performances in domains where authors tend to explicitly express sentiment about specific entities or topics, such as in reviews or on social media. We investigate TSC in news articles, a much less researched domain, despite the importance of news as an essential information source in individual and societal decision making. This article introduces NewsTSC, a manually annotated dataset to explore TSC on news articles. Investigating characteristics of sentiment in news and contrasting them to popular TSC domains, we find that sentiment in the news is expressed less explicitly, is more dependent on context and readership, and requires a greater degree of interpretation. In an extensive evaluation, we find that the state of the art in TSC performs worse on news articles than on other domains (average recall AvgRec = 69.8 on NewsTSC compared to AvgRev = [75.6, 82.2] on established TSC datasets). Reasons include incorrectly resolved relation of target and sentiment-bearing phrases and off-context dependence. As a major improvement over previous news TSC, we find that BERT's natural language understanding capabilities capture the less explicit sentiment used in news articles.