 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Elicitation of Moral Values from Language Models
Jan 25, 2026As AI systems become pervasive, grounding their behavior in human values is critical. Prior work suggests that language models (LMs) exhibit limited inherent moral reasoning, leading to calls for explicit moral teaching. However, constructing ground truth data for moral evaluation is difficult given plural frameworks and pervasive biases. We investigate unsupervised elicitation as an alternative, asking whether pretrained (base) LMs possess intrinsic moral reasoning capability that can be surfaced without human supervision. Using the Internal Coherence Maximization (ICM) algorithm across three benchmark datasets and four LMs, we test whether ICM can reliably label moral judgments, generalize across moral frameworks, and mitigate social bias. Results show that ICM outperforms all pre-trained and chatbot baselines on the Norm Bank and ETHICS benchmarks, while fine-tuning on ICM labels performs on par with or surpasses those of human labels. Across theoretically motivated moral frameworks, ICM yields its largest relative gains on Justice and Commonsense morality. Furthermore, although chatbot LMs exhibit social bias failure rates comparable to their pretrained ones, ICM reduces such errors by more than half, with the largest improvements in race, socioeconomic status, and politics. These findings suggest that pretrained LMs possess latent moral reasoning capacities that can be elicited through unsupervised methods like ICM, providing a scalable path for AI alignment.
Web-Browsing LLMs Can Access Social Media Profiles and Infer User Demographics
Jul 16, 2025Large language models (LLMs) have traditionally relied on static training data, limiting their knowledge to fixed snapshots. Recent advancements, however, have equipped LLMs with web browsing capabilities, enabling real time information retrieval and multi step reasoning over live web content. While prior studies have demonstrated LLMs ability to access and analyze websites, their capacity to directly retrieve and analyze social media data remains unexplored. Here, we evaluate whether web browsing LLMs can infer demographic attributes of social media users given only their usernames. Using a synthetic dataset of 48 X (Twitter) accounts and a survey dataset of 1,384 international participants, we show that these models can access social media content and predict user demographics with reasonable accuracy. Analysis of the synthetic dataset further reveals how LLMs parse and interpret social media profiles, which may introduce gender and political biases against accounts with minimal activity. While this capability holds promise for computational social science in the post API era, it also raises risks of misuse particularly in information operations and targeted advertising underscoring the need for safeguards. We recommend that LLM providers restrict this capability in public facing applications, while preserving controlled access for verified research purposes.
Societal AI Research Has Become Less Interdisciplinary
Jun 11, 2025As artificial intelligence (AI) systems become deeply embedded in everyday life, calls to align AI development with ethical and societal values have intensified. Interdisciplinary collaboration is often championed as a key pathway for fostering such engagement. Yet it remains unclear whether interdisciplinary research teams are actually leading this shift in practice. This study analyzes over 100,000 AI-related papers published on ArXiv between 2014 and 2024 to examine how ethical values and societal concerns are integrated into technical AI research. We develop a classifier to identify societal content and measure the extent to which research papers express these considerations. We find a striking shift: while interdisciplinary teams remain more likely to produce societally-oriented research, computer science-only teams now account for a growing share of the field's overall societal output. These teams are increasingly integrating societal concerns into their papers and tackling a wide range of domains - from fairness and safety to healthcare and misinformation. These findings challenge common assumptions about the drivers of societal AI and raise important questions. First, what are the implications for emerging understandings of AI safety and governance if most societally-oriented research is being undertaken by exclusively technical teams? Second, for scholars in the social sciences and humanities: in a technical field increasingly responsive to societal demands, what distinctive perspectives can we still offer to help shape the future of AI?
Disclosure of AI-Generated News Increases Engagement but Does Not Reduce Aversion, Despite Positive Quality Ratings
Sep 05, 2024The advancement of artificial intelligence (AI) has led to its application in many areas, including journalism. One key issue is the public's perception of AI-generated content. This preregistered study investigates (i) the perceived quality of AI-assisted and AI-generated versus human-generated news articles, (ii) whether disclosure of AI's involvement in generating these news articles influences engagement with them, and (iii) whether such awareness affects the willingness to read AI-generated articles in the future. We employed a between-subjects survey experiment with 599 participants from the German-speaking part of Switzerland, who evaluated the credibility, readability, and expertise of news articles. These articles were either written by journalists (control group), rewritten by AI (AI-assisted group), or entirely generated by AI (AI-generated group). Our results indicate that all news articles, regardless of whether they were written by journalists or AI, were perceived to be of equal quality. When participants in the treatment groups were subsequently made aware of AI's involvement in generating the articles, they expressed a higher willingness to engage with (i.e., continue reading) the articles than participants in the control group. However, they were not more willing to read AI-generated news in the future. These results suggest that aversion to AI usage in news media is not primarily rooted in a perceived lack of quality, and that by disclosing using AI, journalists could attract more immediate engagement with their content, at least in the short term.
Open-Source Large Language Models Outperform Crowd Workers and Approach ChatGPT in Text-Annotation Tasks
Jul 05, 2023This study examines the performance of open-source Large Language Models (LLMs) in text annotation tasks and compares it with proprietary models like ChatGPT and human-based services such as MTurk. While prior research demonstrated the high performance of ChatGPT across numerous NLP tasks, open-source LLMs like HugginChat and FLAN are gaining attention for their cost-effectiveness, transparency, reproducibility, and superior data protection. We assess these models using both zero-shot and few-shot approaches and different temperature parameters across a range of text annotation tasks. Our findings show that while ChatGPT achieves the best performance in most tasks, open-source LLMs not only outperform MTurk but also demonstrate competitive potential against ChatGPT in specific tasks.
ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
Mar 27, 2023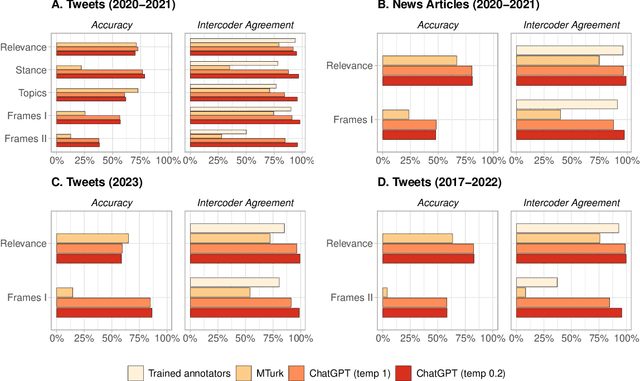
Many NLP applications require manual data annotations for a variety of tasks, notably to train classifiers or evaluate the performance of unsupervised models. Depending on the size and degree of complexity, the tasks may be conducted by crowd-workers on platforms such as MTurk as well as trained annotators, such as research assistants. Using a sample of 2,382 tweets, we demonstrate that ChatGPT outperforms crowd-workers for several annotation tasks, including relevance, stance, topics, and frames detection. Specifically, the zero-shot accuracy of ChatGPT exceeds that of crowd-workers for four out of five tasks, while ChatGPT's intercoder agreement exceeds that of both crowd-workers and trained annotators for all tasks. Moreover, the per-annotation cost of ChatGPT is less than $0.003 -- about twenty times cheaper than MTurk. These results show the potential of large language models to drastically increase the efficiency of text classification.
Human-in-the-Loop Hate Speech Classification in a Multilingual Context
Dec 05, 2022



The shift of public debate to the digital sphere has been accompanied by a rise in online hate speech. While many promising approaches for hate speech classification have been proposed, studies often focus only on a single language, usually English, and do not address three key concerns: post-deployment performance, classifier maintenance and infrastructural limitations. In this paper, we introduce a new human-in-the-loop BERT-based hate speech classification pipeline and trace its development from initial data collection and annotation all the way to post-deployment. Our classifier, trained using data from our original corpus of over 422k examples, is specifically developed for the inherently multilingual setting of Switzerland and outperforms with its F1 score of 80.5 the currently best-performing BERT-based multilingual classifier by 5.8 F1 points in German and 3.6 F1 points in French. Our systematic evaluations over a 12-month period further highlight the vital importance of continuous, human-in-the-loop classifier maintenance to ensure robust hate speech classification post-deployment.