 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Navigation and Classification via Open Source Large Language Model Processing
Feb 07, 2025This paper presents a novel methodological framework for detecting and classifying latent constructs, including frames, narratives, and topics, from textual data using Open-Source Large Language Models (LLMs). The proposed hybrid approach combines automated summarization with human-in-the-loop validation to enhance the accuracy and interpretability of construct identification. By employing iterative sampling coupled with expert refinement, the framework guarantees methodological robustness and ensures conceptual precision. Applied to diverse data sets, including AI policy debates, newspaper articles on encryption, and the 20 Newsgroups data set, this approach demonstrates its versatility in systematically analyzing complex political discourses, media framing, and topic classification tasks.
Open-Source Large Language Models Outperform Crowd Workers and Approach ChatGPT in Text-Annotation Tasks
Jul 05, 2023This study examines the performance of open-source Large Language Models (LLMs) in text annotation tasks and compares it with proprietary models like ChatGPT and human-based services such as MTurk. While prior research demonstrated the high performance of ChatGPT across numerous NLP tasks, open-source LLMs like HugginChat and FLAN are gaining attention for their cost-effectiveness, transparency, reproducibility, and superior data protection. We assess these models using both zero-shot and few-shot approaches and different temperature parameters across a range of text annotation tasks. Our findings show that while ChatGPT achieves the best performance in most tasks, open-source LLMs not only outperform MTurk but also demonstrate competitive potential against ChatGPT in specific tasks.
ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
Mar 27, 2023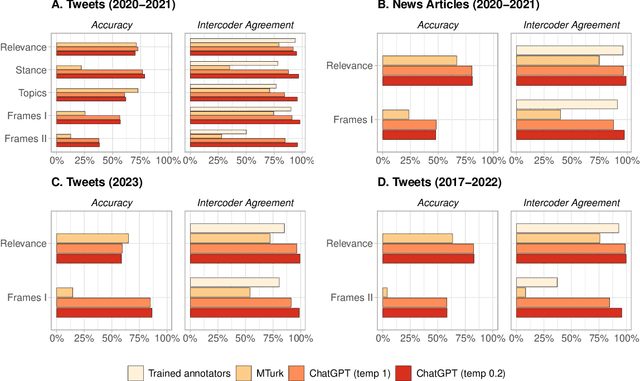
Many NLP applications require manual data annotations for a variety of tasks, notably to train classifiers or evaluate the performance of unsupervised models. Depending on the size and degree of complexity, the tasks may be conducted by crowd-workers on platforms such as MTurk as well as trained annotators, such as research assistants. Using a sample of 2,382 tweets, we demonstrate that ChatGPT outperforms crowd-workers for several annotation tasks, including relevance, stance, topics, and frames detection. Specifically, the zero-shot accuracy of ChatGPT exceeds that of crowd-workers for four out of five tasks, while ChatGPT's intercoder agreement exceeds that of both crowd-workers and trained annotators for all tasks. Moreover, the per-annotation cost of ChatGPT is less than $0.003 -- about twenty times cheaper than MTurk. These results show the potential of large language models to drastically increase the efficiency of text classification.