 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssisted Text Annotation Using Active Learning to Achieve High Quality with Little Effort
Paper and Code
Dec 15, 2021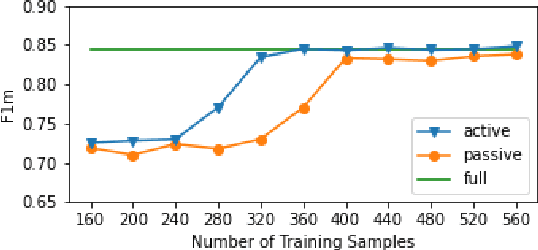
Large amounts of annotated data have become more important than ever, especially since the rise of deep learning techniques. However, manual annotations are costly. We propose a tool that enables researchers to create large, high-quality, annotated datasets with only a few manual annotations, thus strongly reducing annotation cost and effort. For this purpose, we combine an active learning (AL) approach with a pre-trained language model to semi-automatically identify annotation categories in the given text documents. To highlight our research direction's potential, we evaluate the approach on the task of identifying frames in news articles. Our preliminary results show that employing AL strongly reduces the number of annotations for correct classification of even these complex and subtle frames. On the framing dataset, the AL approach needs only 16.3\% of the annotations to reach the same performance as a model trained on the full dataset.