 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciClaimEval: Cross-modal Claim Verification in Scientific Papers
Feb 07, 2026We present SciClaimEval, a new scientific dataset for the claim verification task. Unlike existing resources, SciClaimEval features authentic claims, including refuted ones, directly extracted from published papers. To create refuted claims, we introduce a novel approach that modifies the supporting evidence (figures and tables), rather than altering the claims or relying on large language models (LLMs) to fabricate contradictions. The dataset provides cross-modal evidence with diverse representations: figures are available as images, while tables are provided in multiple formats, including images, LaTeX source, HTML, and JSON. SciClaimEval contains 1,664 annotated samples from 180 papers across three domains, machine learning, natural language processing, and medicine, validated through expert annotation. We benchmark 11 multimodal foundation models, both open-source and proprietary, across the dataset. Results show that figure-based verification remains particularly challenging for all models, as a substantial performance gap remains between the best system and human baseline.
The Promises and Pitfalls of LLM Annotations in Dataset Labeling: a Case Study on Media Bias Detection
Nov 17, 2024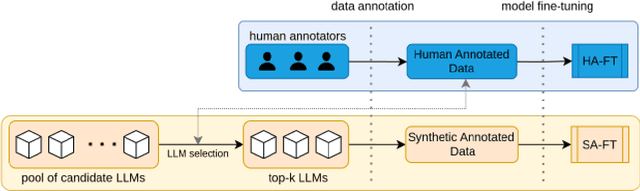
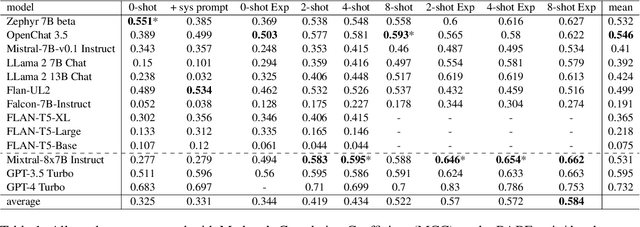
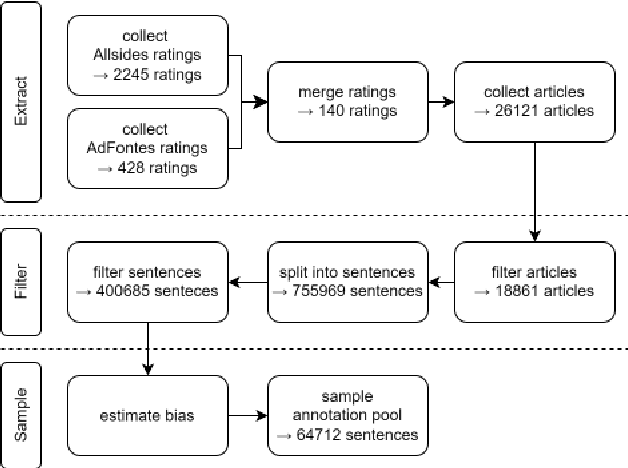
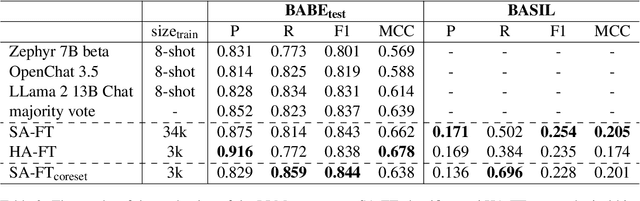
High annotation costs from hiring or crowdsourcing complicate the creation of large, high-quality datasets needed for training reliable text classifiers. Recent research suggests using Large Language Models (LLMs) to automate the annotation process, reducing these costs while maintaining data quality. LLMs have shown promising results in annotating downstream tasks like hate speech detection and political framing. Building on the success in these areas, this study investigates whether LLMs are viable for annotating the complex task of media bias detection and whether a downstream media bias classifier can be trained on such data. We create annolexical, the first large-scale dataset for media bias classification with over 48000 synthetically annotated examples. Our classifier, fine-tuned on this dataset, surpasses all of the annotator LLMs by 5-9 percent in Matthews Correlation Coefficient (MCC) and performs close to or outperforms the model trained on human-labeled data when evaluated on two media bias benchmark datasets (BABE and BASIL). This study demonstrates how our approach significantly reduces the cost of dataset creation in the media bias domain and, by extension, the development of classifiers, while our subsequent behavioral stress-testing reveals some of its current limitations and trade-offs.
Can LLMs Master Math? Investigating Large Language Models on Math Stack Exchange
Mar 30, 2024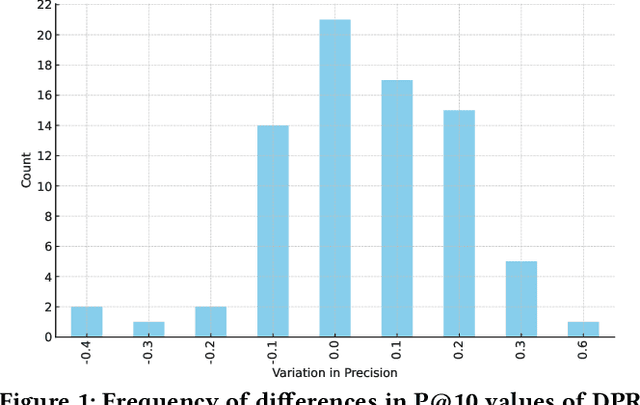
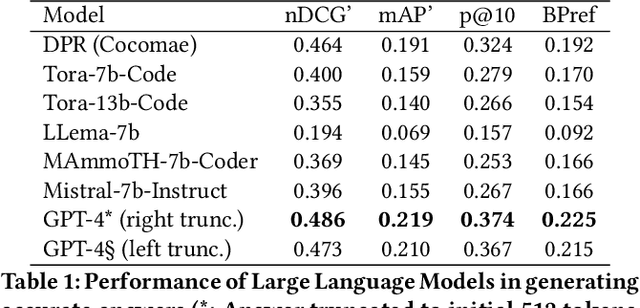
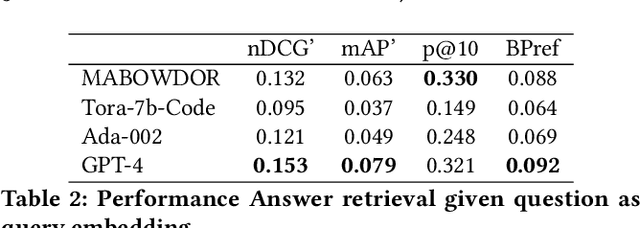
Large Language Models (LLMs) have demonstrated exceptional capabilities in various natural language tasks, often achieving performances that surpass those of humans. Despite these advancements, the domain of mathematics presents a distinctive challenge, primarily due to its specialized structure and the precision it demands. In this study, we adopted a two-step approach for investigating the proficiency of LLMs in answering mathematical questions. First, we employ the most effective LLMs, as identified by their performance on math question-answer benchmarks, to generate answers to 78 questions from the Math Stack Exchange (MSE). Second, a case analysis is conducted on the LLM that showed the highest performance, focusing on the quality and accuracy of its answers through manual evaluation. We found that GPT-4 performs best (nDCG of 0.48 and P@10 of 0.37) amongst existing LLMs fine-tuned for answering mathematics questions and outperforms the current best approach on ArqMATH3 Task1, considering P@10. Our Case analysis indicates that while the GPT-4 can generate relevant responses in certain instances, it does not consistently answer all questions accurately. This paper explores the current limitations of LLMs in navigating complex mathematical problem-solving. Through case analysis, we shed light on the gaps in LLM capabilities within mathematics, thereby setting the stage for future research and advancements in AI-driven mathematical reasoning. We make our code and findings publicly available for research: \url{https://github.com/gipplab/LLM-Investig-MathStackExchange}
Taxonomy of Mathematical Plagiarism
Jan 30, 2024Plagiarism is a pressing concern, even more so with the availability of large language models. Existing plagiarism detection systems reliably find copied and moderately reworded text but fail for idea plagiarism, especially in mathematical science, which heavily uses formal mathematical notation. We make two contributions. First, we establish a taxonomy of mathematical content reuse by annotating potentially plagiarised 122 scientific document pairs. Second, we analyze the best-performing approaches to detect plagiarism and mathematical content similarity on the newly established taxonomy. We found that the best-performing methods for plagiarism and math content similarity achieve an overall detection score (PlagDet) of 0.06 and 0.16, respectively. The best-performing methods failed to detect most cases from all seven newly established math similarity types. Outlined contributions will benefit research in plagiarism detection systems, recommender systems, question-answering systems, and search engines. We make our experiment's code and annotated dataset available to the community: https://github.com/gipplab/Taxonomy-of-Mathematical-Plagiarism
Neural Machine Translation for Mathematical Formulae
May 25, 2023



We tackle the problem of neural machine translation of mathematical formulae between ambiguous presentation languages and unambiguous content languages. Compared to neural machine translation on natural language, mathematical formulae have a much smaller vocabulary and much longer sequences of symbols, while their translation requires extreme precision to satisfy mathematical information needs. In this work, we perform the tasks of translating from LaTeX to Mathematica as well as from LaTeX to semantic LaTeX. While recurrent, recursive, and transformer networks struggle with preserving all contained information, we find that convolutional sequence-to-sequence networks achieve 95.1% and 90.7% exact matches, respectively.
Collaborative and AI-aided Exam Question Generation using Wikidata in Education
Nov 15, 2022Since the COVID-19 outbreak, the use of digital learning or education platforms has significantly increased. Teachers now digitally distribute homework and provide exercise questions. In both cases, teachers need to continuously develop novel and individual questions. This process can be very time-consuming and should be facilitated and accelerated both through exchange with other teachers and by using Artificial Intelligence (AI) capabilities. To address this need, we propose a multilingual Wikimedia framework that allows for collaborative worldwide teacher knowledge engineering and subsequent AI-aided question generation, test, and correction. As a proof of concept, we present >>PhysWikiQuiz<<, a physics question generation and test engine. Our system (hosted by Wikimedia at https://physwikiquiz.wmflabs.org) retrieves physics knowledge from the open community-curated database Wikidata. It can generate questions in different variations and verify answer values and units using a Computer Algebra System (CAS). We evaluate the performance on a public benchmark dataset at each stage of the system workflow. For an average formula with three variables, the system can generate and correct up to 300 questions for individual students based on a single formula concept name as input by the teacher.
Caching and Reproducibility: Making Data Science experiments faster and FAIRer
Nov 09, 2022
Small to medium-scale data science experiments often rely on research software developed ad-hoc by individual scientists or small teams. Often there is no time to make the research software fast, reusable, and open access. The consequence is twofold. First, subsequent researchers must spend significant work hours building upon the proposed hypotheses or experimental framework. In the worst case, others cannot reproduce the experiment and reuse the findings for subsequent research. Second, suppose the ad-hoc research software fails during often long-running computationally expensive experiments. In that case, the overall effort to iteratively improve the software and rerun the experiments creates significant time pressure on the researchers. We suggest making caching an integral part of the research software development process, even before the first line of code is written. This article outlines caching recommendations for developing research software in data science projects. Our recommendations provide a perspective to circumvent common problems such as propriety dependence, speed, etc. At the same time, caching contributes to the reproducibility of experiments in the open science workflow. Concerning the four guiding principles, i.e., Findability, Accessibility, Interoperability, and Reusability (FAIR), we foresee that including the proposed recommendation in a research software development will make the data related to that software FAIRer for both machines and humans. We exhibit the usefulness of some of the proposed recommendations on our recently completed research software project in mathematical information retrieval.
* 8 pages, 1 table