 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-Aware Content-Based Recommendations for Mathematical Research Papers
May 05, 2026Content-based research paper recommendation (CbRPR) has seen advances in computer science and biomedicine, but remains unexplored for mathematics, where paper relatedness is more conceptual than explicit textual or citation-based similarity. Mathematics papers may be connected through shared proof techniques, logical implications, or natural generalizations, yet exhibit minimal textual or citation overlap, rendering existing CbRPR ineffective. To address this gap, we first conduct an expert-driven study characterizing mathematical recommendations, revealing that relevance is inherently \textit{aspect}-driven. Grounded in this insight, we introduce GoldRiM (small, expert-annotated) and SilverRiM (large, automatically derived), the first datasets for \textit{aspect}-aware CbRPR in mathematics. Recognizing that LLM embeddings of mathematical content alone yield suboptimal representation, we propose AchGNN, an \textit{aspect}-conditioned heterogeneous GNN that jointly models textual semantics, citation structure, and author lineage. Across GoldRiM and SilverRiM, AchGNN consistently outperforms prior \textit{aspect}-based CbRPR methods, achieving substantial gains across all evaluated \textit{aspects}. We conduct ablation studies to analyze the contributions of individual \textit{aspect} supervision, authorship lineage, and graph-structural signals to AchGNN's performance. To assess domain generality, we further evaluate AchGNN on the \textit{Papers with Code} dataset of machine learning publications, demonstrating that our \textit{aspect}-aware approach effectively transfers beyond mathematics. We deploy our system on the MaRDI platform to help mathematicians with recommendations and release datasets and code publicly for reproducibility.
Reducing the climate impact of data portals: a case study
Jun 06, 2024The carbon footprint share of the information and communication technology (ICT) sector has steadily increased in the past decade and is predicted to make up as much as 23 \% of global emissions in 2030. This shows a pressing need for developers, including the information retrieval community, to make their code more energy-efficient. In this project proposal, we discuss techniques to reduce the energy footprint of the MaRDI (Mathematical Research Data Initiative) Portal, a MediaWiki-based knowledge base. In future work, we plan to implement these changes and provide concrete measurements on the gain in energy efficiency. Researchers developing similar knowledge bases can adapt our measures to reduce their environmental footprint. In this way, we are working on mitigating the climate impact of Information Retrieval research.
Can LLMs Master Math? Investigating Large Language Models on Math Stack Exchange
Mar 30, 2024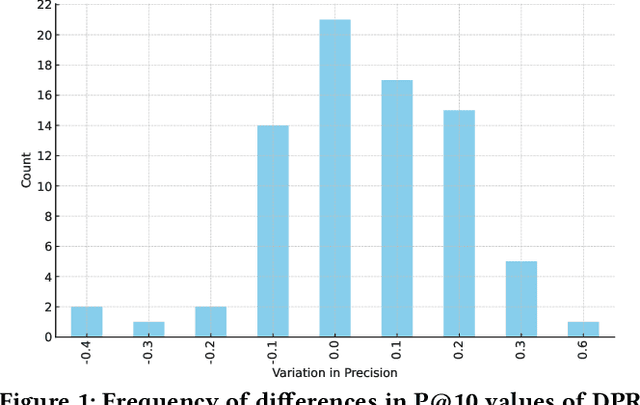
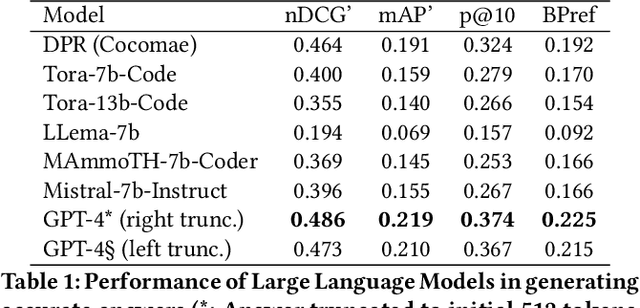
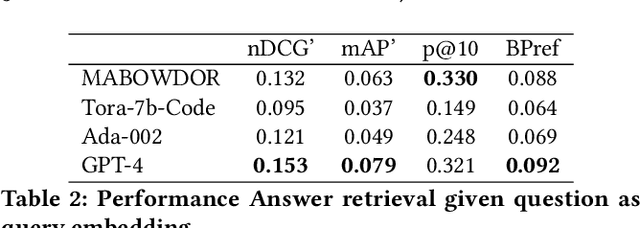
Large Language Models (LLMs) have demonstrated exceptional capabilities in various natural language tasks, often achieving performances that surpass those of humans. Despite these advancements, the domain of mathematics presents a distinctive challenge, primarily due to its specialized structure and the precision it demands. In this study, we adopted a two-step approach for investigating the proficiency of LLMs in answering mathematical questions. First, we employ the most effective LLMs, as identified by their performance on math question-answer benchmarks, to generate answers to 78 questions from the Math Stack Exchange (MSE). Second, a case analysis is conducted on the LLM that showed the highest performance, focusing on the quality and accuracy of its answers through manual evaluation. We found that GPT-4 performs best (nDCG of 0.48 and P@10 of 0.37) amongst existing LLMs fine-tuned for answering mathematics questions and outperforms the current best approach on ArqMATH3 Task1, considering P@10. Our Case analysis indicates that while the GPT-4 can generate relevant responses in certain instances, it does not consistently answer all questions accurately. This paper explores the current limitations of LLMs in navigating complex mathematical problem-solving. Through case analysis, we shed light on the gaps in LLM capabilities within mathematics, thereby setting the stage for future research and advancements in AI-driven mathematical reasoning. We make our code and findings publicly available for research: \url{https://github.com/gipplab/LLM-Investig-MathStackExchange}
Taxonomy of Mathematical Plagiarism
Jan 30, 2024Plagiarism is a pressing concern, even more so with the availability of large language models. Existing plagiarism detection systems reliably find copied and moderately reworded text but fail for idea plagiarism, especially in mathematical science, which heavily uses formal mathematical notation. We make two contributions. First, we establish a taxonomy of mathematical content reuse by annotating potentially plagiarised 122 scientific document pairs. Second, we analyze the best-performing approaches to detect plagiarism and mathematical content similarity on the newly established taxonomy. We found that the best-performing methods for plagiarism and math content similarity achieve an overall detection score (PlagDet) of 0.06 and 0.16, respectively. The best-performing methods failed to detect most cases from all seven newly established math similarity types. Outlined contributions will benefit research in plagiarism detection systems, recommender systems, question-answering systems, and search engines. We make our experiment's code and annotated dataset available to the community: https://github.com/gipplab/Taxonomy-of-Mathematical-Plagiarism
TEIMMA: The First Content Reuse Annotator for Text, Images, and Math
May 22, 2023This demo paper presents the first tool to annotate the reuse of text, images, and mathematical formulae in a document pair -- TEIMMA. Annotating content reuse is particularly useful to develop plagiarism detection algorithms. Real-world content reuse is often obfuscated, which makes it challenging to identify such cases. TEIMMA allows entering the obfuscation type to enable novel classifications for confirmed cases of plagiarism. It enables recording different reuse types for text, images, and mathematical formulae in HTML and supports users by visualizing the content reuse in a document pair using similarity detection methods for text and math.
Caching and Reproducibility: Making Data Science experiments faster and FAIRer
Nov 09, 2022
Small to medium-scale data science experiments often rely on research software developed ad-hoc by individual scientists or small teams. Often there is no time to make the research software fast, reusable, and open access. The consequence is twofold. First, subsequent researchers must spend significant work hours building upon the proposed hypotheses or experimental framework. In the worst case, others cannot reproduce the experiment and reuse the findings for subsequent research. Second, suppose the ad-hoc research software fails during often long-running computationally expensive experiments. In that case, the overall effort to iteratively improve the software and rerun the experiments creates significant time pressure on the researchers. We suggest making caching an integral part of the research software development process, even before the first line of code is written. This article outlines caching recommendations for developing research software in data science projects. Our recommendations provide a perspective to circumvent common problems such as propriety dependence, speed, etc. At the same time, caching contributes to the reproducibility of experiments in the open science workflow. Concerning the four guiding principles, i.e., Findability, Accessibility, Interoperability, and Reusability (FAIR), we foresee that including the proposed recommendation in a research software development will make the data related to that software FAIRer for both machines and humans. We exhibit the usefulness of some of the proposed recommendations on our recently completed research software project in mathematical information retrieval.
* 8 pages, 1 table