 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Media Bias Taxonomy: A Systematic Literature Review on the Forms and Automated Detection of Media Bias
Jan 10, 2024
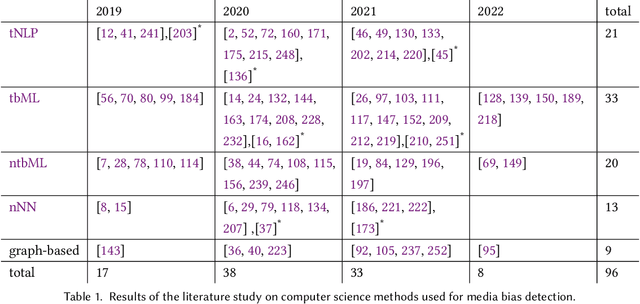

The way the media presents events can significantly affect public perception, which in turn can alter people's beliefs and views. Media bias describes a one-sided or polarizing perspective on a topic. This article summarizes the research on computational methods to detect media bias by systematically reviewing 3140 research papers published between 2019 and 2022. To structure our review and support a mutual understanding of bias across research domains, we introduce the Media Bias Taxonomy, which provides a coherent overview of the current state of research on media bias from different perspectives. We show that media bias detection is a highly active research field, in which transformer-based classification approaches have led to significant improvements in recent years. These improvements include higher classification accuracy and the ability to detect more fine-granular types of bias. However, we have identified a lack of interdisciplinarity in existing projects, and a need for more awareness of the various types of media bias to support methodologically thorough performance evaluations of media bias detection systems. Concluding from our analysis, we see the integration of recent machine learning advancements with reliable and diverse bias assessment strategies from other research areas as the most promising area for future research contributions in the field.
TEIMMA: The First Content Reuse Annotator for Text, Images, and Math
May 22, 2023This demo paper presents the first tool to annotate the reuse of text, images, and mathematical formulae in a document pair -- TEIMMA. Annotating content reuse is particularly useful to develop plagiarism detection algorithms. Real-world content reuse is often obfuscated, which makes it challenging to identify such cases. TEIMMA allows entering the obfuscation type to enable novel classifications for confirmed cases of plagiarism. It enables recording different reuse types for text, images, and mathematical formulae in HTML and supports users by visualizing the content reuse in a document pair using similarity detection methods for text and math.
Methods and Tools to Advance the Retrieval of Mathematical Knowledge from Digital Libraries for Search-, Recommendation-, and Assistance-Systems
May 12, 2023



This project investigated new approaches and technologies to enhance the accessibility of mathematical content and its semantic information for a broad range of information retrieval applications. To achieve this goal, the project addressed three main research challenges: (1) syntactic analysis of mathematical expressions, (2) semantic enrichment of mathematical expressions, and (3) evaluation using quality metrics and demonstrators. To make our research useful for the research community, we published tools that enable researchers to process mathematical expressions more effectively and efficiently.
A Benchmark of PDF Information Extraction Tools using a Multi-Task and Multi-Domain Evaluation Framework for Academic Documents
Mar 17, 2023Extracting information from academic PDF documents is crucial for numerous indexing, retrieval, and analysis use cases. Choosing the best tool to extract specific content elements is difficult because many, technically diverse tools are available, but recent performance benchmarks are rare. Moreover, such benchmarks typically cover only a few content elements like header metadata or bibliographic references and use smaller datasets from specific academic disciplines. We provide a large and diverse evaluation framework that supports more extraction tasks than most related datasets. Our framework builds upon DocBank, a multi-domain dataset of 1.5M annotated content elements extracted from 500K pages of research papers on arXiv. Using the new framework, we benchmark ten freely available tools in extracting document metadata, bibliographic references, tables, and other content elements from academic PDF documents. GROBID achieves the best metadata and reference extraction results, followed by CERMINE and Science Parse. For table extraction, Adobe Extract outperforms other tools, even though the performance is much lower than for other content elements. All tools struggle to extract lists, footers, and equations. We conclude that more research on improving and combining tools is necessary to achieve satisfactory extraction quality for most content elements. Evaluation datasets and frameworks like the one we present support this line of research. We make our data and code publicly available to contribute toward this goal.
Recommending Research Papers to Chemists: A Specialized Interface for Chemical Entity Exploration
May 11, 2022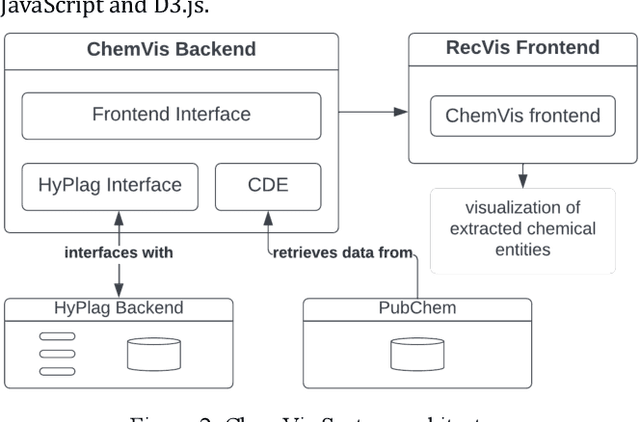
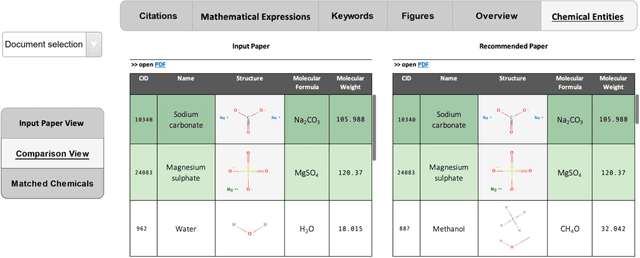
Researchers and scientists increasingly rely on specialized information retrieval (IR) or recommendation systems (RS) to support them in their daily research tasks. Paper recommender systems are one such tool scientists use to stay on top of the ever-increasing number of academic publications in their field. Improving research paper recommender systems is an active research field. However, less research has focused on how the interfaces of research paper recommender systems can be tailored to suit the needs of different research domains. For example, in the field of biomedicine and chemistry, researchers are not only interested in textual relevance but may also want to discover or compare the contained chemical entity information found in a paper's full text. Existing recommender systems for academic literature do not support the discovery of this non-textual, but semantically valuable, chemical entity data. We present the first implementation of a specialized chemistry paper recommender system capable of visualizing the contained chemical structures, chemical formulae, and synonyms for chemical compounds within the document's full text. We review existing tools and related research in this field before describing the implementation of our ChemVis system. With the help of chemists, we are expanding the functionality of ChemVis, and will perform an evaluation of recommendation performance and usability in future work.
TASSY -- A Text Annotation Survey System
Dec 16, 2021


We present a free and open-source tool for creating web-based surveys that include text annotation tasks. Existing tools offer either text annotation or survey functionality but not both. Combining the two input types is particularly relevant for investigating a reader's perception of a text which also depends on the reader's background, such as age, gender, and education. Our tool caters primarily to the needs of researchers in the Library and Information Sciences, the Social Sciences, and the Humanities who apply Content Analysis to investigate, e.g., media bias, political communication, or fake news.
Testing the Generalization of Neural Language Models for COVID-19 Misinformation Detection
Nov 29, 2021


A drastic rise in potentially life-threatening misinformation has been a by-product of the COVID-19 pandemic. Computational support to identify false information within the massive body of data on the topic is crucial to prevent harm. Researchers proposed many methods for flagging online misinformation related to COVID-19. However, these methods predominantly target specific content types (e.g., news) or platforms (e.g., Twitter). The methods' capabilities to generalize were largely unclear so far. We evaluate fifteen Transformer-based models on five COVID-19 misinformation datasets that include social media posts, news articles, and scientific papers to fill this gap. We show tokenizers and models tailored to COVID-19 data do not provide a significant advantage over general-purpose ones. Our study provides a realistic assessment of models for detecting COVID-19 misinformation. We expect that evaluating a broad spectrum of datasets and models will benefit future research in developing misinformation detection systems.
Detecting Cross-Language Plagiarism using Open Knowledge Graphs
Nov 18, 2021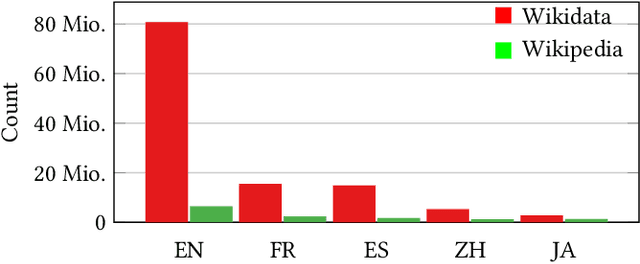
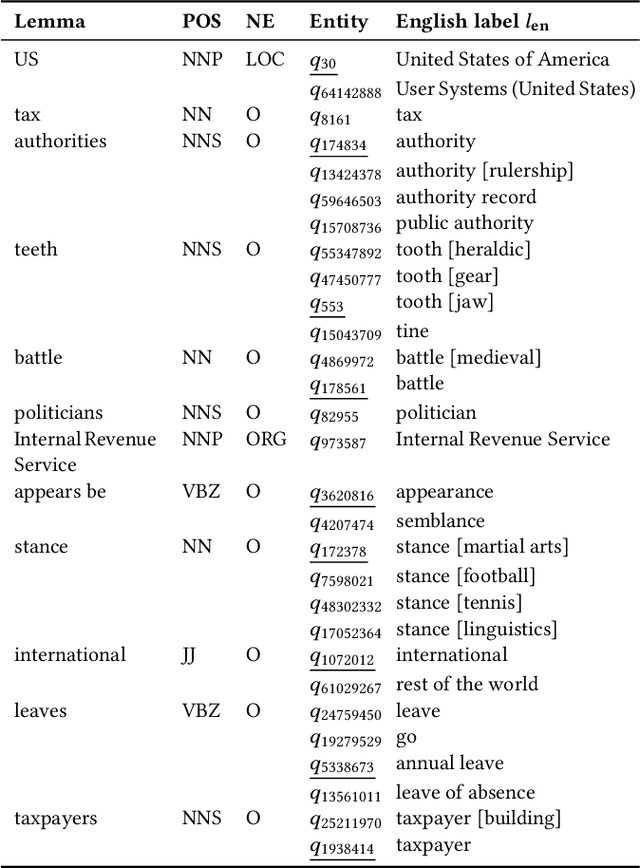
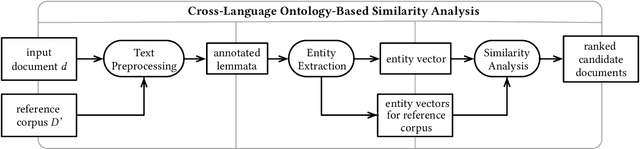
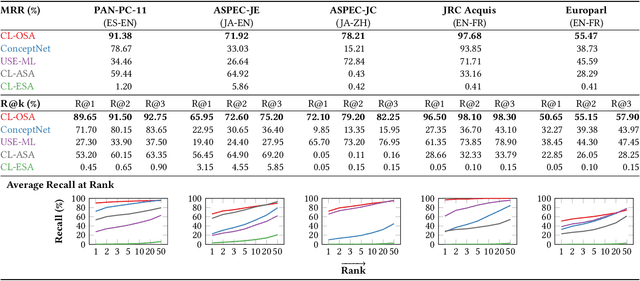
Identifying cross-language plagiarism is challenging, especially for distant language pairs and sense-for-sense translations. We introduce the new multilingual retrieval model Cross-Language Ontology-Based Similarity Analysis (CL\nobreakdash-OSA) for this task. CL-OSA represents documents as entity vectors obtained from the open knowledge graph Wikidata. Opposed to other methods, CL\nobreakdash-OSA does not require computationally expensive machine translation, nor pre-training using comparable or parallel corpora. It reliably disambiguates homonyms and scales to allow its application to Web-scale document collections. We show that CL-OSA outperforms state-of-the-art methods for retrieving candidate documents from five large, topically diverse test corpora that include distant language pairs like Japanese-English. For identifying cross-language plagiarism at the character level, CL-OSA primarily improves the detection of sense-for-sense translations. For these challenging cases, CL-OSA's performance in terms of the well-established PlagDet score exceeds that of the best competitor by more than factor two. The code and data of our study are openly available.
Incorporating Word Sense Disambiguation in Neural Language Models
Jun 15, 2021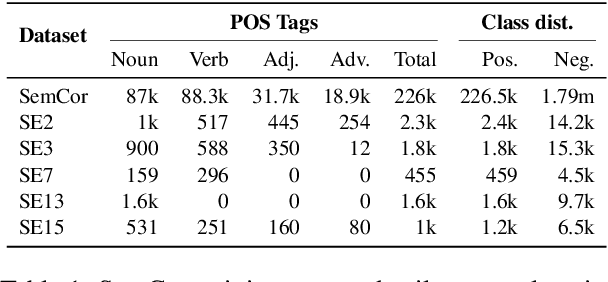
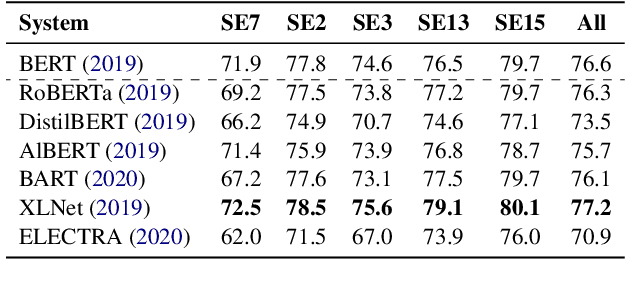


We present two supervised (pre-)training methods to incorporate gloss definitions from lexical resources into neural language models (LMs). The training improves our models' performance for Word Sense Disambiguation (WSD) but also benefits general language understanding tasks while adding almost no parameters. We evaluate our techniques with seven different neural LMs and find that XLNet is more suitable for WSD than BERT. Our best-performing methods exceeds state-of-the-art WSD techniques on the SemCor 3.0 dataset by 0.5% F1 and increase BERT's performance on the GLUE benchmark by 1.1% on average.
Analyzing Non-Textual Content Elements to Detect Academic Plagiarism
Jun 10, 2021



Identifying academic plagiarism is a pressing problem, among others, for research institutions, publishers, and funding organizations. Detection approaches proposed so far analyze lexical, syntactical, and semantic text similarity. These approaches find copied, moderately reworded, and literally translated text. However, reliably detecting disguised plagiarism, such as strong paraphrases, sense-for-sense translations, and the reuse of non-textual content and ideas, is an open research problem. The thesis addresses this problem by proposing plagiarism detection approaches that implement a different concept: analyzing non-textual content in academic documents, specifically citations, images, and mathematical content. To validate the effectiveness of the proposed detection approaches, the thesis presents five evaluations that use real cases of academic plagiarism and exploratory searches for unknown cases. The evaluation results show that non-textual content elements contain a high degree of semantic information, are language-independent, and largely immutable to the alterations that authors typically perform to conceal plagiarism. Analyzing non-textual content complements text-based detection approaches and increases the detection effectiveness, particularly for disguised forms of academic plagiarism. To demonstrate the benefit of combining non-textual and text-based detection methods, the thesis describes the first plagiarism detection system that integrates the analysis of citation-based, image-based, math-based, and text-based document similarity. The system's user interface employs visualizations that significantly reduce the effort and time users must invest in examining content similarity.