Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Word Sense Disambiguation in Neural Language Models
Paper and Code
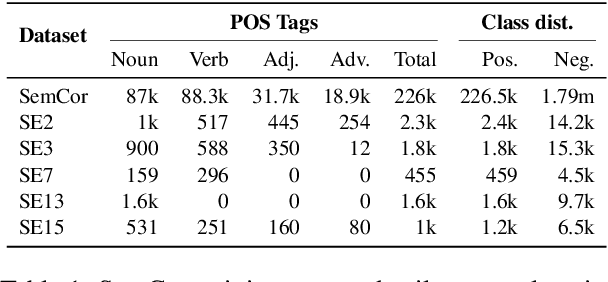
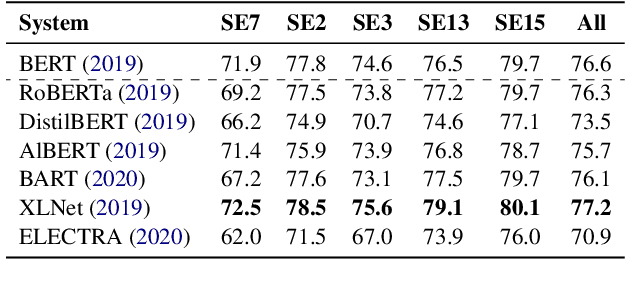


We present two supervised (pre-)training methods to incorporate gloss definitions from lexical resources into neural language models (LMs). The training improves our models' performance for Word Sense Disambiguation (WSD) but also benefits general language understanding tasks while adding almost no parameters. We evaluate our techniques with seven different neural LMs and find that XLNet is more suitable for WSD than BERT. Our best-performing methods exceeds state-of-the-art WSD techniques on the SemCor 3.0 dataset by 0.5% F1 and increase BERT's performance on the GLUE benchmark by 1.1% on average.
View paper on