 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery and Recognition of Formula Concepts using Machine Learning
Mar 19, 2023Citation-based Information Retrieval (IR) methods for scientific documents have proven effective for IR applications, such as Plagiarism Detection or Literature Recommender Systems in academic disciplines that use many references. In science, technology, engineering, and mathematics, researchers often employ mathematical concepts through formula notation to refer to prior knowledge. Our long-term goal is to generalize citation-based IR methods and apply this generalized method to both classical references and mathematical concepts. In this paper, we suggest how mathematical formulas could be cited and define a Formula Concept Retrieval task with two subtasks: Formula Concept Discovery (FCD) and Formula Concept Recognition (FCR). While FCD aims at the definition and exploration of a 'Formula Concept' that names bundled equivalent representations of a formula, FCR is designed to match a given formula to a prior assigned unique mathematical concept identifier. We present machine learning-based approaches to address the FCD and FCR tasks. We then evaluate these approaches on a standardized test collection (NTCIR arXiv dataset). Our FCD approach yields a precision of 68% for retrieving equivalent representations of frequent formulas and a recall of 72% for extracting the formula name from the surrounding text. FCD and FCR enable the citation of formulas within mathematical documents and facilitate semantic search and question answering as well as document similarity assessments for plagiarism detection or recommender systems.
Recommending Research Papers to Chemists: A Specialized Interface for Chemical Entity Exploration
May 11, 2022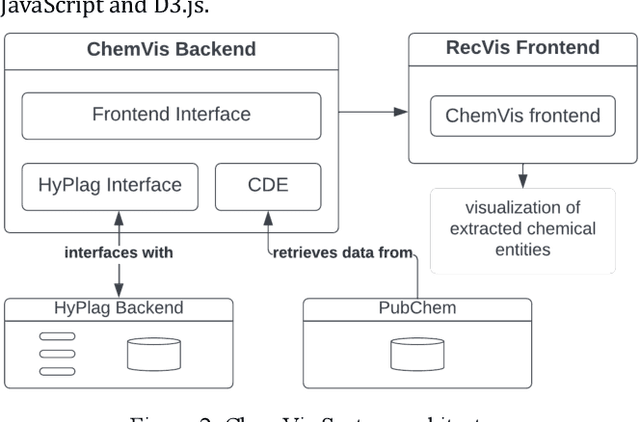
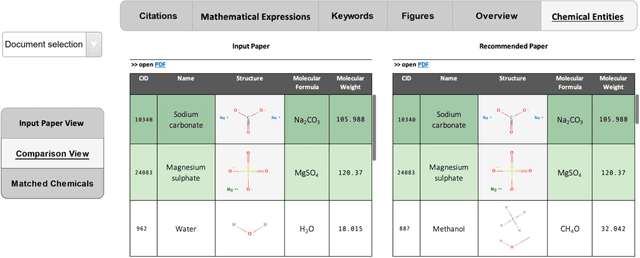
Researchers and scientists increasingly rely on specialized information retrieval (IR) or recommendation systems (RS) to support them in their daily research tasks. Paper recommender systems are one such tool scientists use to stay on top of the ever-increasing number of academic publications in their field. Improving research paper recommender systems is an active research field. However, less research has focused on how the interfaces of research paper recommender systems can be tailored to suit the needs of different research domains. For example, in the field of biomedicine and chemistry, researchers are not only interested in textual relevance but may also want to discover or compare the contained chemical entity information found in a paper's full text. Existing recommender systems for academic literature do not support the discovery of this non-textual, but semantically valuable, chemical entity data. We present the first implementation of a specialized chemistry paper recommender system capable of visualizing the contained chemical structures, chemical formulae, and synonyms for chemical compounds within the document's full text. We review existing tools and related research in this field before describing the implementation of our ChemVis system. With the help of chemists, we are expanding the functionality of ChemVis, and will perform an evaluation of recommendation performance and usability in future work.
A Qualitative Evaluation of User Preference for Link-based vs. Text-based Recommendations of Wikipedia Articles
Sep 16, 2021
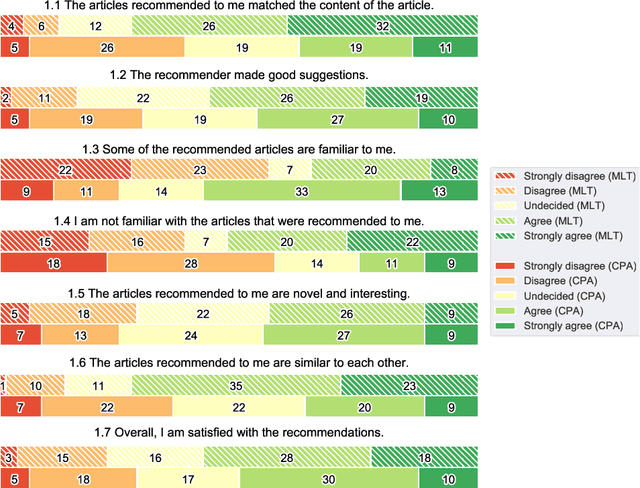
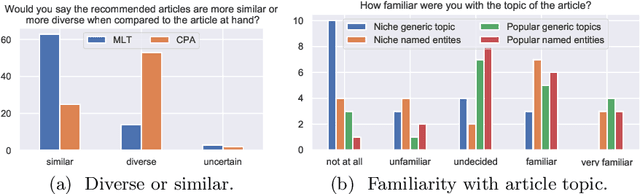
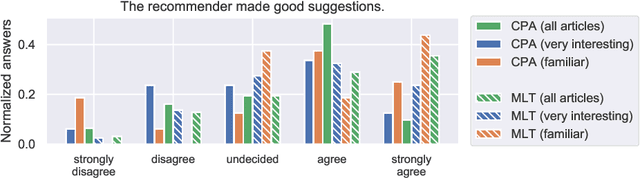
Literature recommendation systems (LRS) assist readers in the discovery of relevant content from the overwhelming amount of literature available. Despite the widespread adoption of LRS, there is a lack of research on the user-perceived recommendation characteristics for fundamentally different approaches to content-based literature recommendation. To complement existing quantitative studies on literature recommendation, we present qualitative study results that report on users' perceptions for two contrasting recommendation classes: (1) link-based recommendation represented by the Co-Citation Proximity (CPA) approach, and (2) text-based recommendation represented by Lucene's MoreLikeThis (MLT) algorithm. The empirical data analyzed in our study with twenty users and a diverse set of 40 Wikipedia articles indicate a noticeable difference between text- and link-based recommendation generation approaches along several key dimensions. The text-based MLT method receives higher satisfaction ratings in terms of user-perceived similarity of recommended articles. In contrast, the CPA approach receives higher satisfaction scores in terms of diversity and serendipity of recommendations. We conclude that users of literature recommendation systems can benefit most from hybrid approaches that combine both link- and text-based approaches, where the user's information needs and preferences should control the weighting for the approaches used. The optimal weighting of multiple approaches used in a hybrid recommendation system is highly dependent on a user's shifting needs.
AutoMSC: Automatic Assignment of Mathematics Subject Classification Labels
May 25, 2020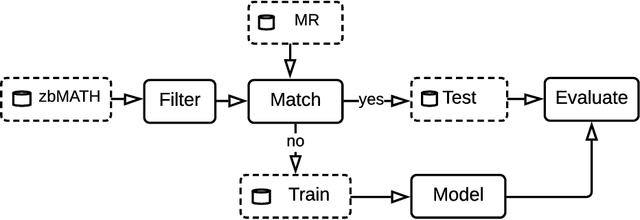
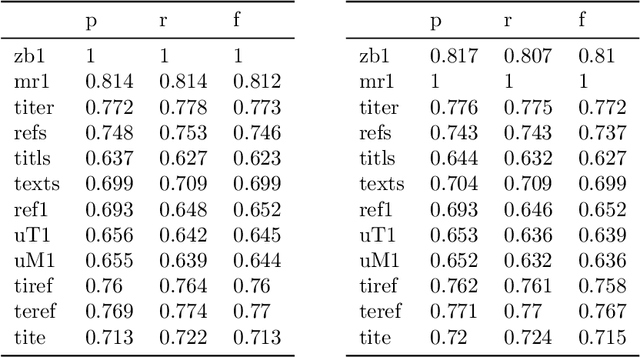
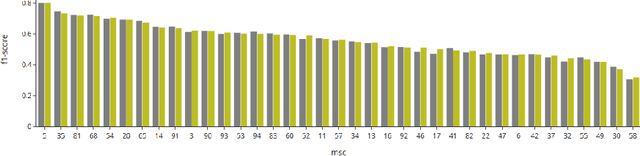
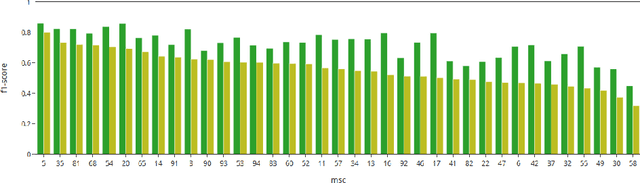
Authors of research papers in the fields of mathematics, and other math-heavy disciplines commonly employ the Mathematics Subject Classification (MSC) scheme to search for relevant literature. The MSC is a hierarchical alphanumerical classification scheme that allows librarians to specify one or multiple codes for publications. Digital Libraries in Mathematics, as well as reviewing services, such as zbMATH and Mathematical Reviews (MR) rely on these MSC labels in their workflows to organize the abstracting and reviewing process. Especially, the coarse-grained classification determines the subject editor who is responsible for the actual reviewing process. In this paper, we investigate the feasibility of automatically assigning a coarse-grained primary classification using the MSC scheme, by regarding the problem as a multi class classification machine learning task. We find that the our method achieves an (F_{1})-score of over 77%, which is remarkably close to the agreement of zbMATH and MR ((F_{1})-score of 81%). Moreover, we find that the method's confidence score allows for reducing the effort by 86\% compared to the manual coarse-grained classification effort while maintaining a precision of 81% for automatically classified articles.
Giveme5W1H: A Universal System for Extracting Main Events from News Articles
Sep 06, 2019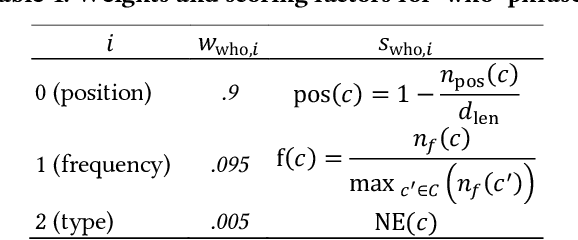
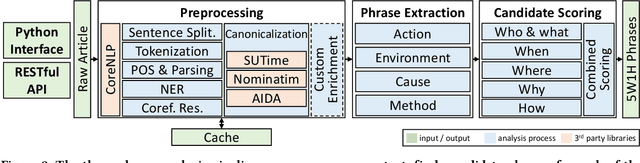


Event extraction from news articles is a commonly required prerequisite for various tasks, such as article summarization, article clustering, and news aggregation. Due to the lack of universally applicable and publicly available methods tailored to news datasets, many researchers redundantly implement event extraction methods for their own projects. The journalistic 5W1H questions are capable of describing the main event of an article, i.e., by answering who did what, when, where, why, and how. We provide an in-depth description of an improved version of Giveme5W1H, a system that uses syntactic and domain-specific rules to automatically extract the relevant phrases from English news articles to provide answers to these 5W1H questions. Given the answers to these questions, the system determines an article's main event. In an expert evaluation with three assessors and 120 articles, we determined an overall precision of p=0.73, and p=0.82 for answering the first four W questions, which alone can sufficiently summarize the main event reported on in a news article. We recently made our system publicly available, and it remains the only universal open-source 5W1H extractor capable of being applied to a wide range of use cases in news analysis.