 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Cross-Language Plagiarism using Open Knowledge Graphs
Paper and Code
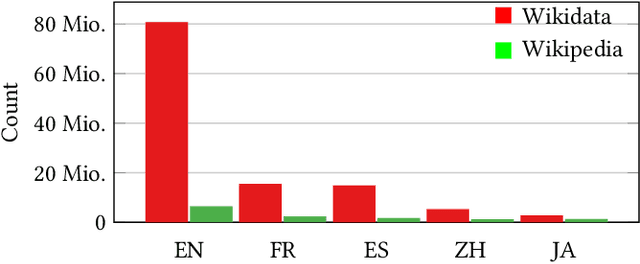
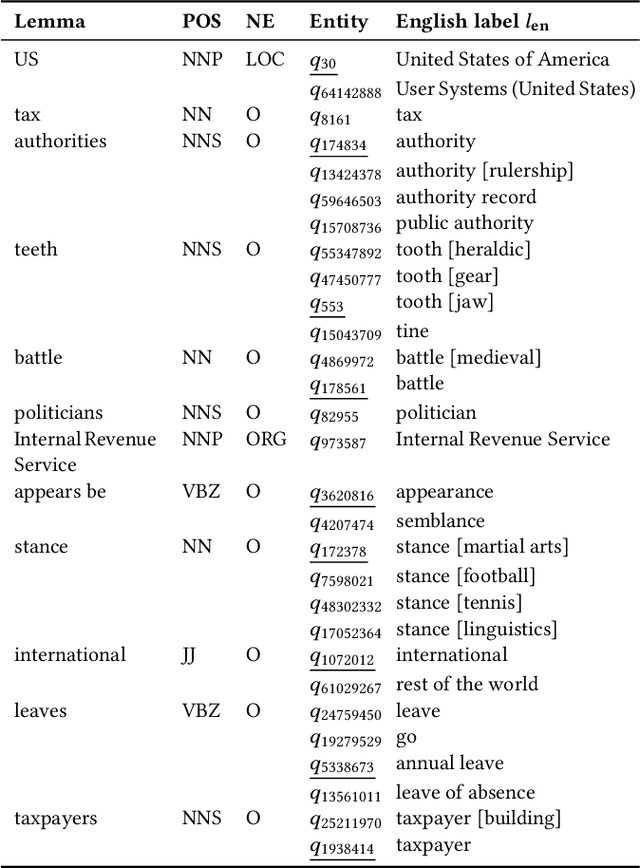
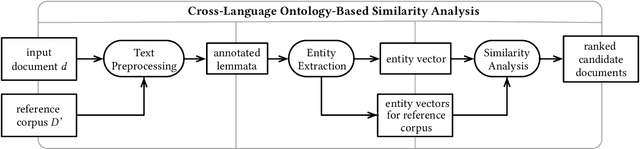
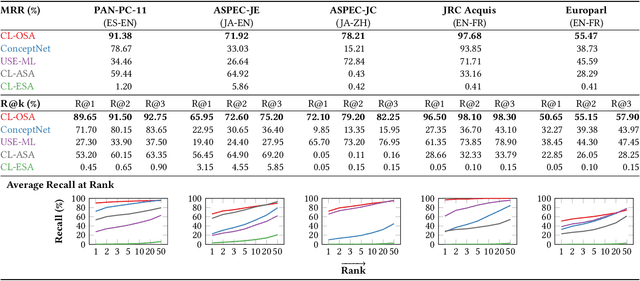
Identifying cross-language plagiarism is challenging, especially for distant language pairs and sense-for-sense translations. We introduce the new multilingual retrieval model Cross-Language Ontology-Based Similarity Analysis (CL\nobreakdash-OSA) for this task. CL-OSA represents documents as entity vectors obtained from the open knowledge graph Wikidata. Opposed to other methods, CL\nobreakdash-OSA does not require computationally expensive machine translation, nor pre-training using comparable or parallel corpora. It reliably disambiguates homonyms and scales to allow its application to Web-scale document collections. We show that CL-OSA outperforms state-of-the-art methods for retrieving candidate documents from five large, topically diverse test corpora that include distant language pairs like Japanese-English. For identifying cross-language plagiarism at the character level, CL-OSA primarily improves the detection of sense-for-sense translations. For these challenging cases, CL-OSA's performance in terms of the well-established PlagDet score exceeds that of the best competitor by more than factor two. The code and data of our study are openly available.