 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics in Search Engine Query Suggestions for European Politicians
Jan 08, 2026Search engines are commonly used for online political information seeking. Yet, it remains unclear how search query suggestions for political searches that reflect the latent interest of internet users vary across countries and over time. We provide a systematic analysis of Google search engine query suggestions for European and national politicians. Using an original dataset of search query suggestions for European politicians collected in ten countries, we find that query suggestions are less stable over time in politicians' countries of origin, when the politicians hold a supranational role, and for female politicians. Moreover, query suggestions for political leaders and male politicians are more similar across countries. We conclude by discussing possible future directions for studying information search about European politicians in online search.
* 11 pages; 3 figures; 6 tables; published as a conference paper at WebSci '24 (May 21-24, 2024, Stuttgart, Germany)
Perception-Aware Bias Detection for Query Suggestions
Jan 07, 2026Bias in web search has been in the spotlight of bias detection research for quite a while. At the same time, little attention has been paid to query suggestions in this regard. Awareness of the problem of biased query suggestions has been raised. Likewise, there is a rising need for automatic bias detection approaches. This paper adds on the bias detection pipeline for bias detection in query suggestions of person-related search developed by Bonart et al. \cite{Bonart_2019a}. The sparseness and lack of contextual metadata of query suggestions make them a difficult subject for bias detection. Furthermore, query suggestions are perceived very briefly and subliminally. To overcome these issues, perception-aware metrics are introduced. Consequently, the enhanced pipeline is able to better detect systematic topical bias in search engine query suggestions for person-related searches. The results of an analysis performed with the developed pipeline confirm this assumption. Due to the perception-aware bias detection metrics, findings produced by the pipeline can be assumed to reflect bias that users would discern.
* 13 pages (pp. 130-142); 2 figures; 2 tables; Workshop paper (BIAS 2021) published in CCIS vol. 1418 (Springer)
Auditing Search Query Suggestion Bias Through Recursive Algorithm Interrogation
Jan 06, 2026Despite their important role in online information search, search query suggestions have not been researched as much as most other aspects of search engines. Although reasons for this are multi-faceted, the sparseness of context and the limited data basis of up to ten suggestions per search query pose the most significant problem in identifying bias in search query suggestions. The most proven method to reduce sparseness and improve the validity of bias identification of search query suggestions so far is to consider suggestions from subsequent searches over time for the same query. This work presents a new, alternative approach to search query bias identification that includes less high-level suggestions to deepen the data basis of bias analyses. We employ recursive algorithm interrogation techniques and create suggestion trees that enable access to more subliminal search query suggestions. Based on these suggestions, we investigate topical group bias in person-related searches in the political domain.
Pairwise Comparison for Bias Identification and Quantification
Dec 16, 2025



Linguistic bias in online news and social media is widespread but difficult to measure. Yet, its identification and quantification remain difficult due to subjectivity, context dependence, and the scarcity of high-quality gold-label datasets. We aim to reduce annotation effort by leveraging pairwise comparison for bias annotation. To overcome the costliness of the approach, we evaluate more efficient implementations of pairwise comparison-based rating. We achieve this by investigating the effects of various rating techniques and the parameters of three cost-aware alternatives in a simulation environment. Since the approach can in principle be applied to both human and large language model annotation, our work provides a basis for creating high-quality benchmark datasets and for quantifying biases and other subjective linguistic aspects. The controlled simulations include latent severity distributions, distance-calibrated noise, and synthetic annotator bias to probe robustness and cost-quality trade-offs. In applying the approach to human-labeled bias benchmark datasets, we then evaluate the most promising setups and compare them to direct assessment by large language models and unmodified pairwise comparison labels as baselines. Our findings support the use of pairwise comparison as a practical foundation for quantifying subjective linguistic aspects, enabling reproducible bias analysis. We contribute an optimization of comparison and matchmaking components, an end-to-end evaluation including simulation and real-data application, and an implementation blueprint for cost-aware large-scale annotation
REANIMATOR: Reanimate Retrieval Test Collections with Extracted and Synthetic Resources
Apr 10, 2025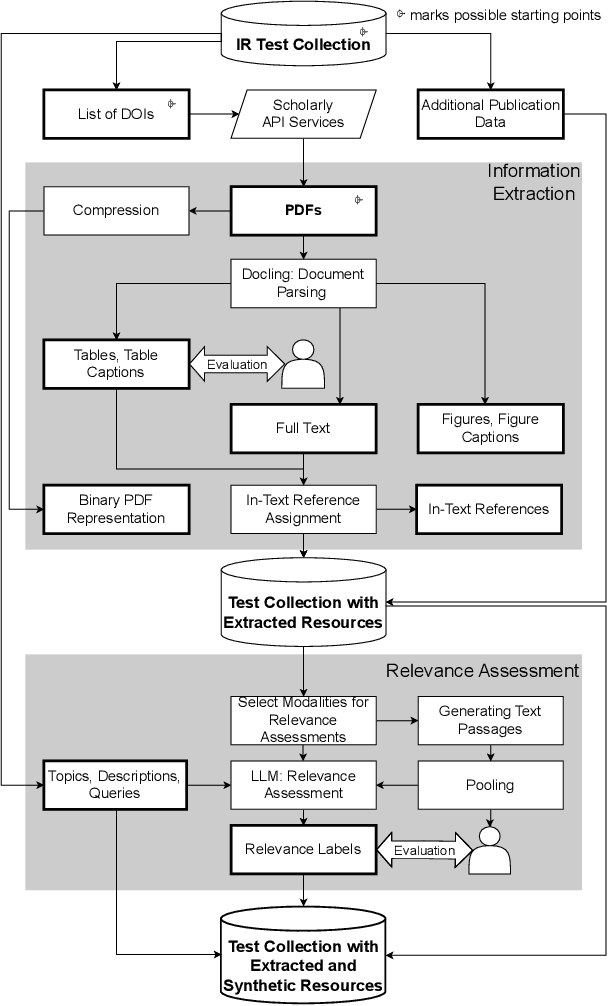


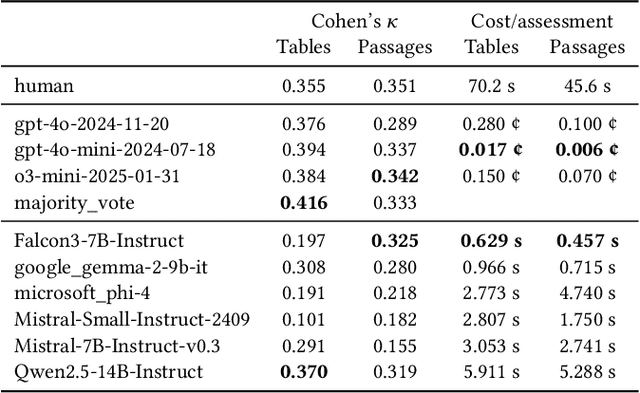
Retrieval test collections are essential for evaluating information retrieval systems, yet they often lack generalizability across tasks. To overcome this limitation, we introduce REANIMATOR, a versatile framework designed to enable the repurposing of existing test collections by enriching them with extracted and synthetic resources. REANIMATOR enhances test collections from PDF files by parsing full texts and machine-readable tables, as well as related contextual information. It then employs state-of-the-art large language models to produce synthetic relevance labels. Including an optional human-in-the-loop step can help validate the resources that have been extracted and generated. We demonstrate its potential with a revitalized version of the TREC-COVID test collection, showcasing the development of a retrieval-augmented generation system and evaluating the impact of tables on retrieval-augmented generation. REANIMATOR enables the reuse of test collections for new applications, lowering costs and broadening the utility of legacy resources.
Investigating Bias in Political Search Query Suggestions by Relative Comparison with LLMs
Oct 31, 2024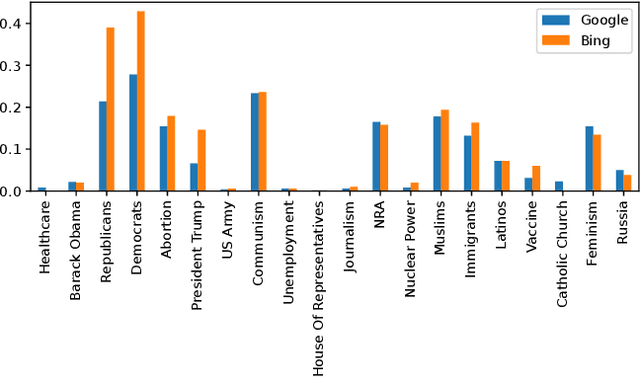

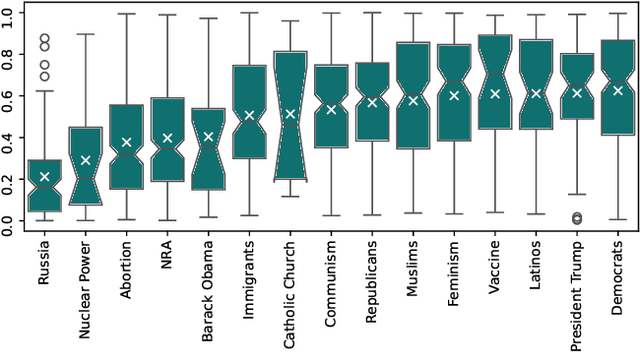
Search query suggestions affect users' interactions with search engines, which then influences the information they encounter. Thus, bias in search query suggestions can lead to exposure to biased search results and can impact opinion formation. This is especially critical in the political domain. Detecting and quantifying bias in web search engines is difficult due to its topic dependency, complexity, and subjectivity. The lack of context and phrasality of query suggestions emphasizes this problem. In a multi-step approach, we combine the benefits of large language models, pairwise comparison, and Elo-based scoring to identify and quantify bias in English search query suggestions. We apply our approach to the U.S. political news domain and compare bias in Google and Bing.
The Media Bias Taxonomy: A Systematic Literature Review on the Forms and Automated Detection of Media Bias
Jan 10, 2024
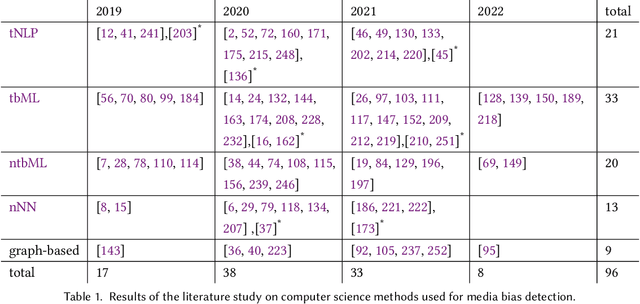

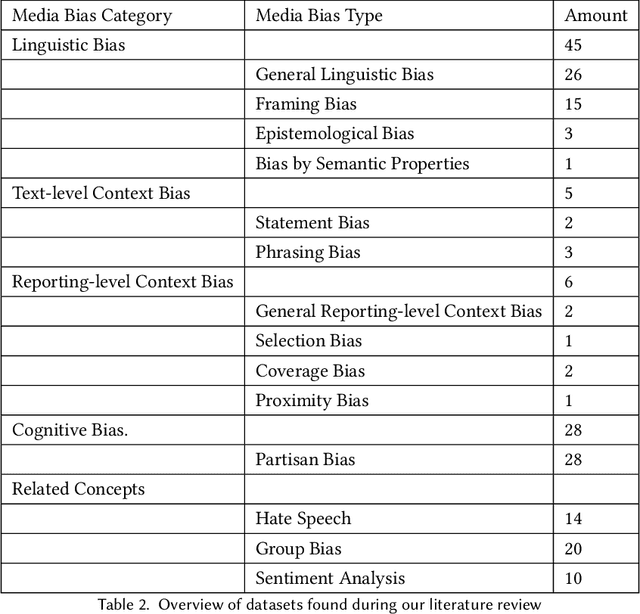
The way the media presents events can significantly affect public perception, which in turn can alter people's beliefs and views. Media bias describes a one-sided or polarizing perspective on a topic. This article summarizes the research on computational methods to detect media bias by systematically reviewing 3140 research papers published between 2019 and 2022. To structure our review and support a mutual understanding of bias across research domains, we introduce the Media Bias Taxonomy, which provides a coherent overview of the current state of research on media bias from different perspectives. We show that media bias detection is a highly active research field, in which transformer-based classification approaches have led to significant improvements in recent years. These improvements include higher classification accuracy and the ability to detect more fine-granular types of bias. However, we have identified a lack of interdisciplinarity in existing projects, and a need for more awareness of the various types of media bias to support methodologically thorough performance evaluations of media bias detection systems. Concluding from our analysis, we see the integration of recent machine learning advancements with reliable and diverse bias assessment strategies from other research areas as the most promising area for future research contributions in the field.
$Q_{bias}$ -- A Dataset on Media Bias in Search Queries and Query Suggestions
Nov 29, 2023

This publication describes the motivation and generation of $Q_{bias}$, a large dataset of Google and Bing search queries, a scraping tool and dataset for biased news articles, as well as language models for the investigation of bias in online search. Web search engines are a major factor and trusted source in information search, especially in the political domain. However, biased information can influence opinion formation and lead to biased opinions. To interact with search engines, users formulate search queries and interact with search query suggestions provided by the search engines. A lack of datasets on search queries inhibits research on the subject. We use $Q_{bias}$ to evaluate different approaches to fine-tuning transformer-based language models with the goal of producing models capable of biasing text with left and right political stance. Additionally to this work we provided datasets and language models for biasing texts that allow further research on bias in online information search.
Text Simplification of Scientific Texts for Non-Expert Readers
Jul 07, 2023Reading levels are highly individual and can depend on a text's language, a person's cognitive abilities, or knowledge on a topic. Text simplification is the task of rephrasing a text to better cater to the abilities of a specific target reader group. Simplification of scientific abstracts helps non-experts to access the core information by bypassing formulations that require domain or expert knowledge. This is especially relevant for, e.g., cancer patients reading about novel treatment options. The SimpleText lab hosts the simplification of scientific abstracts for non-experts (Task 3) to advance this field. We contribute three runs employing out-of-the-box summarization models (two based on T5, one based on PEGASUS) and one run using ChatGPT with complex phrase identification.