 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior2Posterior: Model Prior Correction for Long-Tailed Learning
Dec 21, 2024



Learning-based solutions for long-tailed recognition face difficulties in generalizing on balanced test datasets. Due to imbalanced data prior, the learned \textit{a posteriori} distribution is biased toward the most frequent (head) classes, leading to an inferior performance on the least frequent (tail) classes. In general, the performance can be improved by removing such a bias by eliminating the effect of imbalanced prior modeled using the number of class samples (frequencies). We first observe that the \textit{effective prior} on the classes, learned by the model at the end of the training, can differ from the empirical prior obtained using class frequencies. Thus, we propose a novel approach to accurately model the effective prior of a trained model using \textit{a posteriori} probabilities. We propose to correct the imbalanced prior by adjusting the predicted \textit{a posteriori} probabilities (Prior2Posterior: P2P) using the calculated prior in a post-hoc manner after the training, and show that it can result in improved model performance. We present theoretical analysis showing the optimality of our approach for models trained with naive cross-entropy loss as well as logit adjusted loss. Our experiments show that the proposed approach achieves new state-of-the-art (SOTA) on several benchmark datasets from the long-tail literature in the category of logit adjustment methods. Further, the proposed approach can be used to inspect any existing method to capture the \textit{effective prior} and remove any residual bias to improve its performance, post-hoc, without model retraining. We also show that by using the proposed post-hoc approach, the performance of many existing methods can be improved further.
SBAF: A New Activation Function for Artificial Neural Net based Habitability Classification
Jun 06, 2018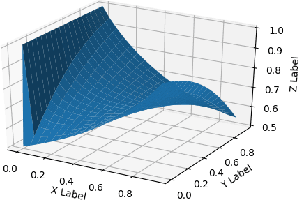
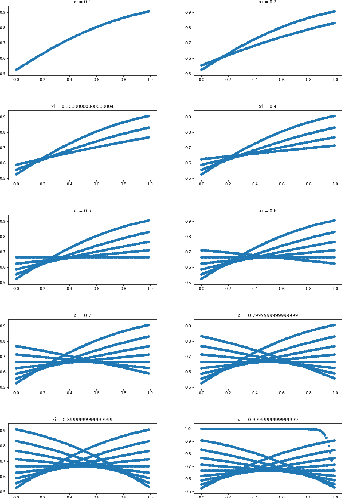
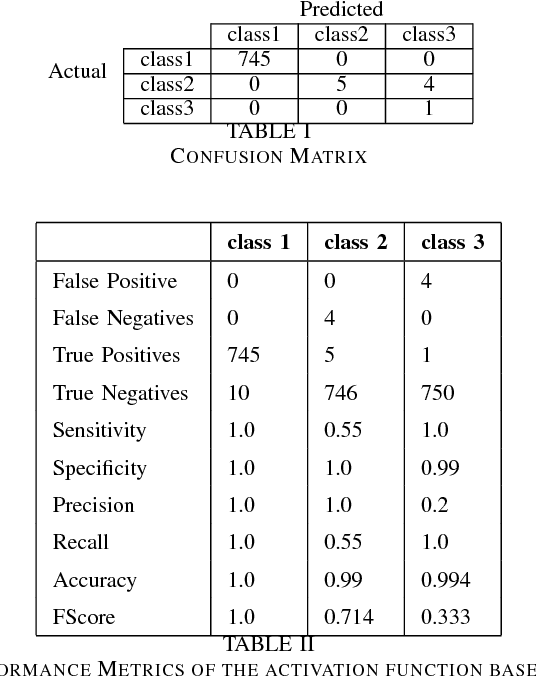
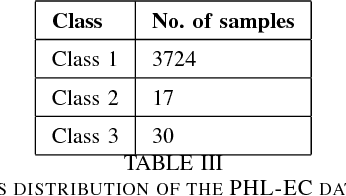
We explore the efficacy of using a novel activation function in Artificial Neural Networks (ANN) in characterizing exoplanets into different classes. We call this Saha-Bora Activation Function (SBAF) as the motivation is derived from long standing understanding of using advanced calculus in modeling habitability score of Exoplanets. The function is demonstrated to possess nice analytical properties and doesn't seem to suffer from local oscillation problems. The manuscript presents the analytical properties of the activation function and the architecture implemented on the function. Keywords: Astroinformatics, Machine Learning, Exoplanets, ANN, Activation Function.
Machine Learning in Astronomy: A Case Study in Quasar-Star Classification
Apr 13, 2018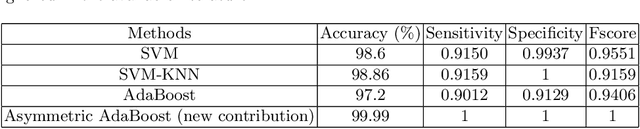
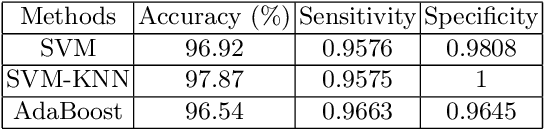
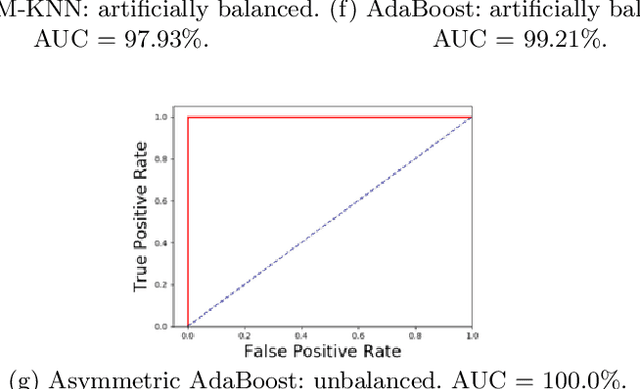

We present the results of various automated classification methods, based on machine learning (ML), of objects from data releases 6 and 7 (DR6 and DR7) of the Sloan Digital Sky Survey (SDSS), primarily distinguishing stars from quasars. We provide a careful scrutiny of approaches available in the literature and have highlighted the pitfalls in those approaches based on the nature of data used for the study. The aim is to investigate the appropriateness of the application of certain ML methods. The manuscript argues convincingly in favor of the efficacy of asymmetric AdaBoost to classify photometric data. The paper presents a critical review of existing study and puts forward an application of asymmetric AdaBoost, as an offspring of that exercise.
ASTROMLSKIT: A New Statistical Machine Learning Toolkit: A Platform for Data Analytics in Astronomy
Apr 29, 2015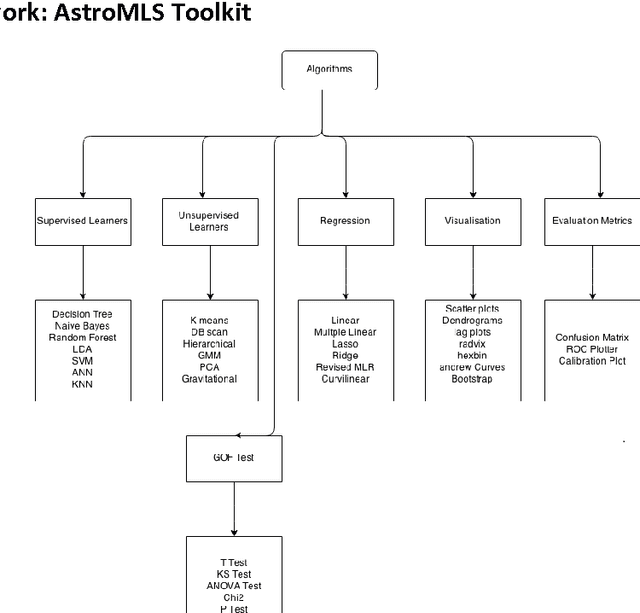
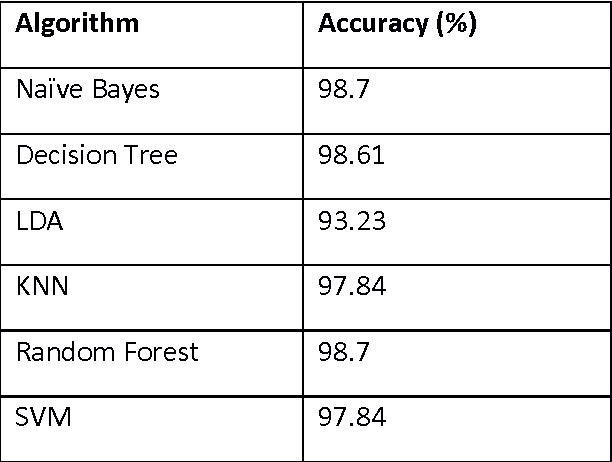
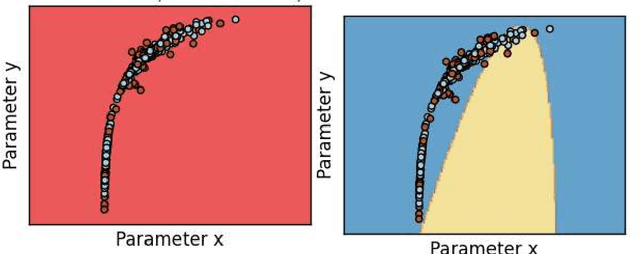
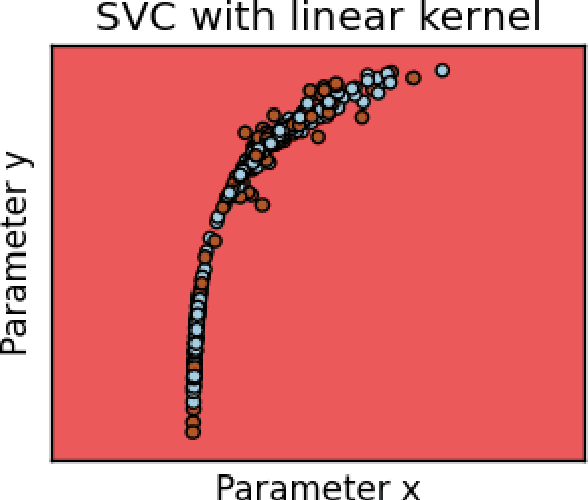
Astroinformatics is a new impact area in the world of astronomy, occasionally called the final frontier, where several astrophysicists, statisticians and computer scientists work together to tackle various data intensive astronomical problems. Exponential growth in the data volume and increased complexity of the data augments difficult questions to the existing challenges. Classical problems in Astronomy are compounded by accumulation of astronomical volume of complex data, rendering the task of classification and interpretation incredibly laborious. The presence of noise in the data makes analysis and interpretation even more arduous. Machine learning algorithms and data analytic techniques provide the right platform for the challenges posed by these problems. A diverse range of open problem like star-galaxy separation, detection and classification of exoplanets, classification of supernovae is discussed. The focus of the paper is the applicability and efficacy of various machine learning algorithms like K Nearest Neighbor (KNN), random forest (RF), decision tree (DT), Support Vector Machine (SVM), Na\"ive Bayes and Linear Discriminant Analysis (LDA) in analysis and inference of the decision theoretic problems in Astronomy. The machine learning algorithms, integrated into ASTROMLSKIT, a toolkit developed in the course of the work, have been used to analyze HabCat data and supernovae data. Accuracy has been found to be appreciably good.