 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-NVS: A 3D Supervision Approach for Next View Selection
Paper and Code
Dec 03, 2020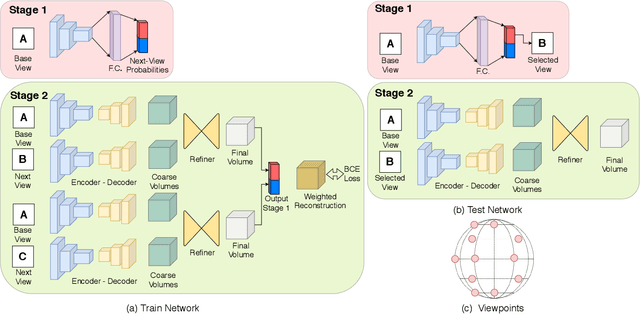
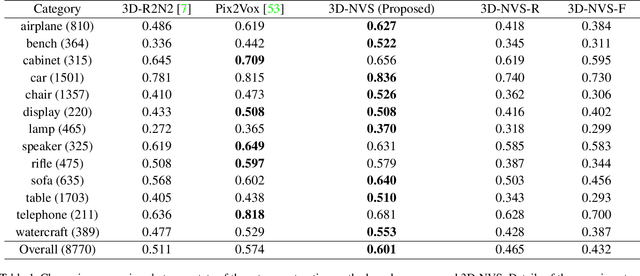
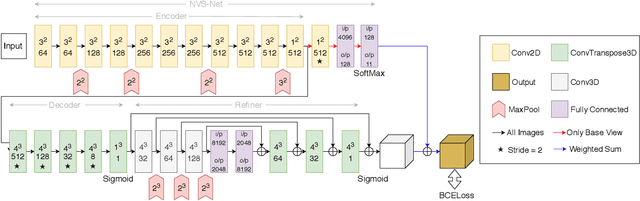
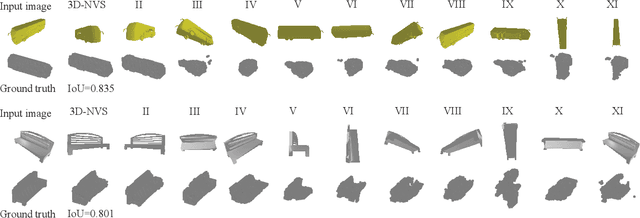
We present a classification based approach for the next best view selection and show how we can plausibly obtain a supervisory signal for this task. The proposed approach is end-to-end trainable and aims to get the best possible 3D reconstruction quality with a pair of passively acquired 2D views. The proposed model consists of two stages: a classifier and a reconstructor network trained jointly via the indirect 3D supervision from ground truth voxels. While testing, the proposed method assumes no prior knowledge of the underlying 3D shape for selecting the next best view. We demonstrate the proposed method's effectiveness via detailed experiments on synthetic and real images and show how it provides improved reconstruction quality than the existing state of the art 3D reconstruction and the next best view prediction techniques.