 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiffusion: A Training-Free Framework for Accurate 3D Geometric Conditioning in Image Generation
Oct 25, 2025Precise geometric control in image generation is essential for engineering \& product design and creative industries to control 3D object features accurately in image space. Traditional 3D editing approaches are time-consuming and demand specialized skills, while current image-based generative methods lack accuracy in geometric conditioning. To address these challenges, we propose GeoDiffusion, a training-free framework for accurate and efficient geometric conditioning of 3D features in image generation. GeoDiffusion employs a class-specific 3D object as a geometric prior to define keypoints and parametric correlations in 3D space. We ensure viewpoint consistency through a rendered image of a reference 3D object, followed by style transfer to meet user-defined appearance specifications. At the core of our framework is GeoDrag, improving accuracy and speed of drag-based image editing on geometry guidance tasks and general instructions on DragBench. Our results demonstrate that GeoDiffusion enables precise geometric modifications across various iterative design workflows.
Finding Dino: A plug-and-play framework for unsupervised detection of out-of-distribution objects using prototypes
Apr 11, 2024



Detecting and localising unknown or Out-of-distribution (OOD) objects in any scene can be a challenging task in vision. Particularly, in safety-critical cases involving autonomous systems like automated vehicles or trains. Supervised anomaly segmentation or open-world object detection models depend on training on exhaustively annotated datasets for every domain and still struggle in distinguishing between background and OOD objects. In this work, we present a plug-and-play generalised framework - PRototype-based zero-shot OOD detection Without Labels (PROWL). It is an inference-based method that does not require training on the domain dataset and relies on extracting relevant features from self-supervised pre-trained models. PROWL can be easily adapted to detect OOD objects in any operational design domain by specifying a list of known classes from this domain. PROWL, as an unsupervised method, outperforms other supervised methods trained without auxiliary OOD data on the RoadAnomaly and RoadObstacle datasets provided in SegmentMeIfYouCan (SMIYC) benchmark. We also demonstrate its suitability for other domains such as rail and maritime scenes.
Enhancing Interpretability of Vertebrae Fracture Grading using Human-interpretable Prototypes
Apr 03, 2024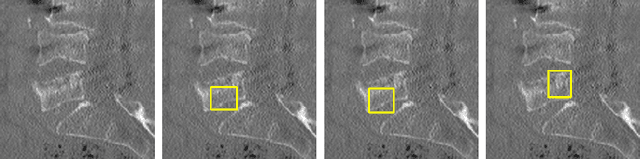

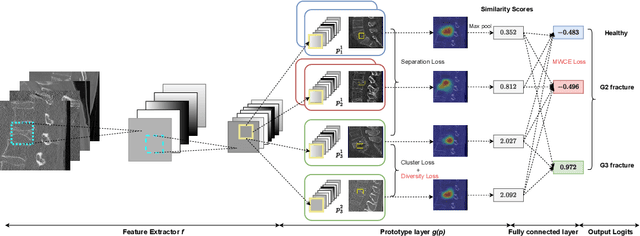

Vertebral fracture grading classifies the severity of vertebral fractures, which is a challenging task in medical imaging and has recently attracted Deep Learning (DL) models. Only a few works attempted to make such models human-interpretable despite the need for transparency and trustworthiness in critical use cases like DL-assisted medical diagnosis. Moreover, such models either rely on post-hoc methods or additional annotations. In this work, we propose a novel interpretable-by-design method, ProtoVerse, to find relevant sub-parts of vertebral fractures (prototypes) that reliably explain the model's decision in a human-understandable way. Specifically, we introduce a novel diversity-promoting loss to mitigate prototype repetitions in small datasets with intricate semantics. We have experimented with the VerSe'19 dataset and outperformed the existing prototype-based method. Further, our model provides superior interpretability against the post-hoc method. Importantly, expert radiologists validated the visual interpretability of our results, showing clinical applicability.
Diffusion Denoised Smoothing for Certified and Adversarial Robust Out-Of-Distribution Detection
Mar 29, 2023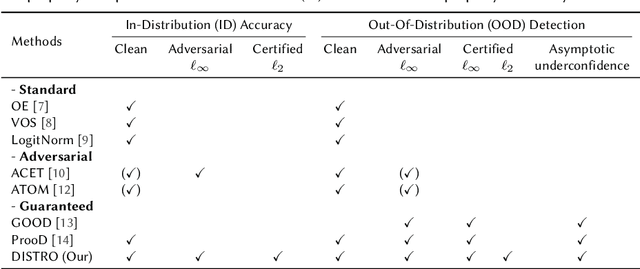
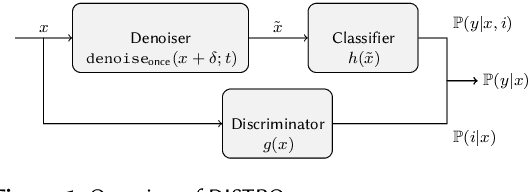
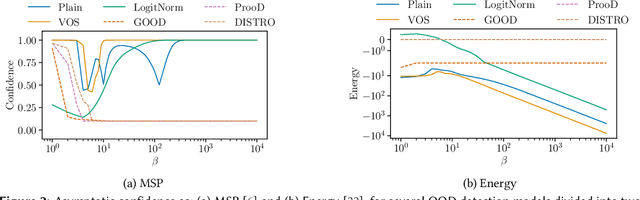
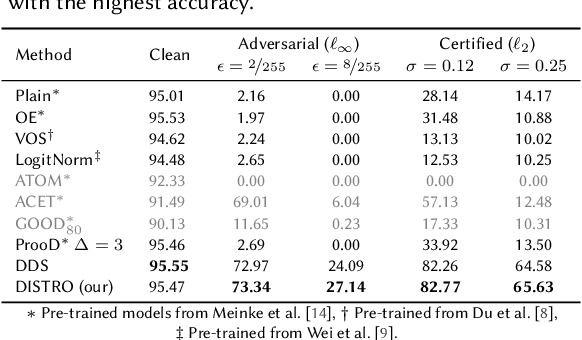
As the use of machine learning continues to expand, the importance of ensuring its safety cannot be overstated. A key concern in this regard is the ability to identify whether a given sample is from the training distribution, or is an "Out-Of-Distribution" (OOD) sample. In addition, adversaries can manipulate OOD samples in ways that lead a classifier to make a confident prediction. In this study, we present a novel approach for certifying the robustness of OOD detection within a $\ell_2$-norm around the input, regardless of network architecture and without the need for specific components or additional training. Further, we improve current techniques for detecting adversarial attacks on OOD samples, while providing high levels of certified and adversarial robustness on in-distribution samples. The average of all OOD detection metrics on CIFAR10/100 shows an increase of $\sim 13 \% / 5\%$ relative to previous approaches.
Item Recommendation with Continuous Experience Evolution of Users using Brownian Motion
Aug 09, 2017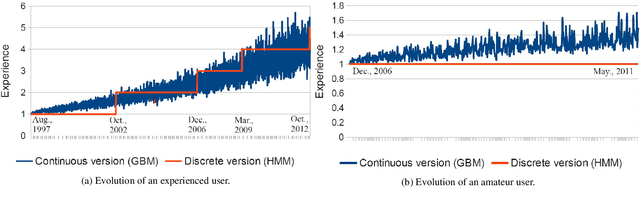
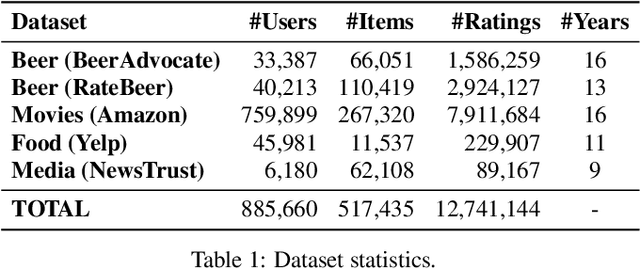

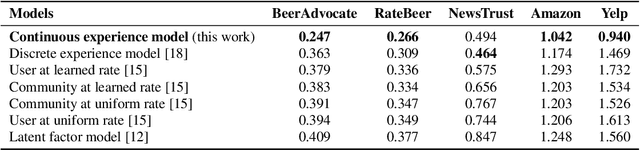
Online review communities are dynamic as users join and leave, adopt new vocabulary, and adapt to evolving trends. Recent work has shown that recommender systems benefit from explicit consideration of user experience. However, prior work assumes a fixed number of discrete experience levels, whereas in reality users gain experience and mature continuously over time. This paper presents a new model that captures the continuous evolution of user experience, and the resulting language model in reviews and other posts. Our model is unsupervised and combines principles of Geometric Brownian Motion, Brownian Motion, and Latent Dirichlet Allocation to trace a smooth temporal progression of user experience and language model respectively. We develop practical algorithms for estimating the model parameters from data and for inference with our model (e.g., to recommend items). Extensive experiments with five real-world datasets show that our model not only fits data better than discrete-model baselines, but also outperforms state-of-the-art methods for predicting item ratings.