 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox Supervised Video Segmentation Proposal Network
Paper and Code

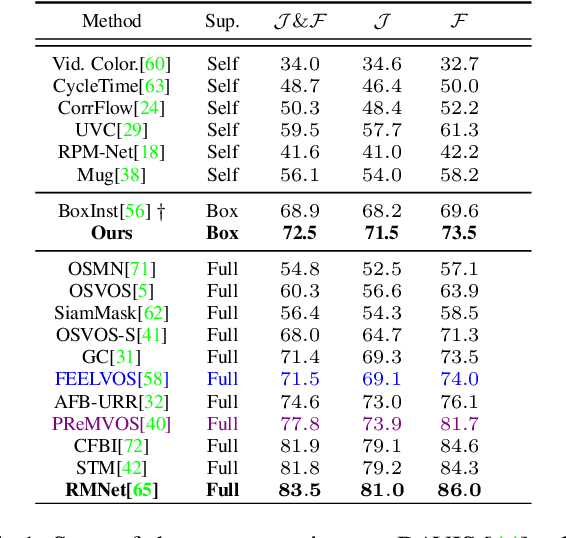
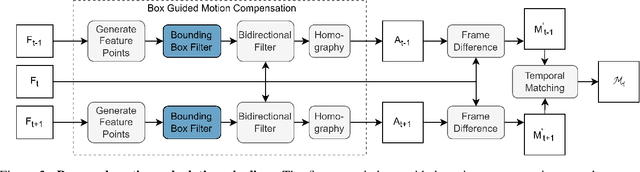
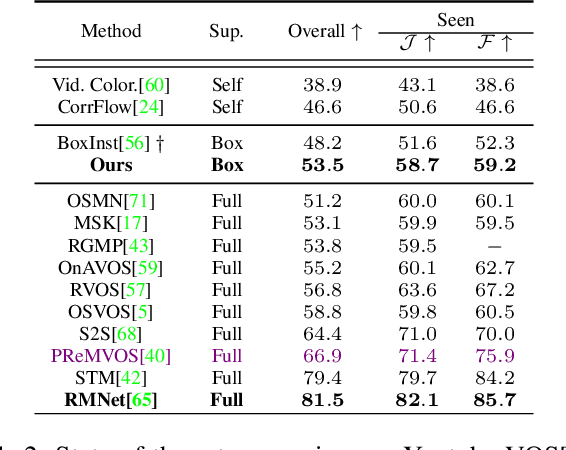
Video Object Segmentation (VOS) has been targeted by various fully-supervised and self-supervised approaches. While fully-supervised methods demonstrate excellent results, self-supervised ones, which do not use pixel-level ground truth, attract much attention. However, self-supervised approaches pose a significant performance gap. Box-level annotations provide a balanced compromise between labeling effort and result quality for image segmentation but have not been exploited for the video domain. In this work, we propose a box-supervised video object segmentation proposal network, which takes advantage of intrinsic video properties. Our method incorporates object motion in the following way: first, motion is computed using a bidirectional temporal difference and a novel bounding box-guided motion compensation. Second, we introduce a novel motion-aware affinity loss that encourages the network to predict positive pixel pairs if they share similar motion and color. The proposed method outperforms the state-of-the-art self-supervised benchmark by 16.4% and 6.9% $\mathcal{J}$ &$\mathcal{F}$ score and the majority of fully supervised methods on the DAVIS and Youtube-VOS dataset without imposing network architectural specifications. We provide extensive tests and ablations on the datasets, demonstrating the robustness of our method.