 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Lifelong Generalized Zero-Shot Learning
Mar 22, 2021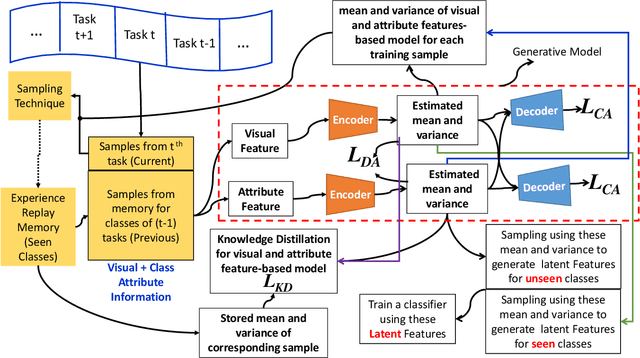
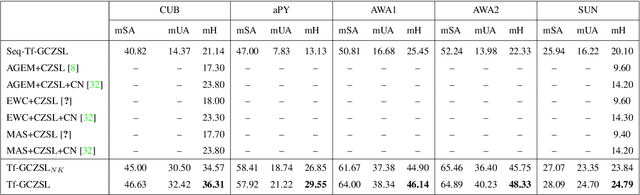
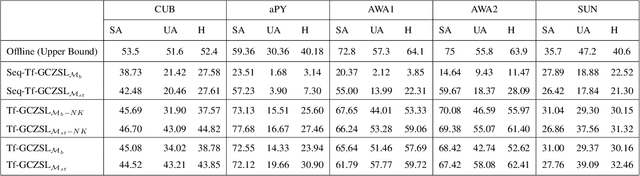
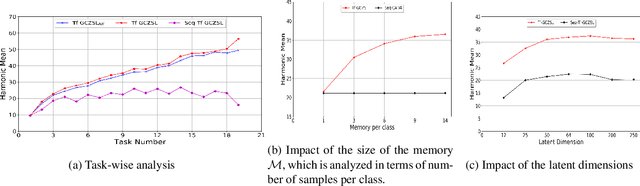
Methods proposed in the literature for zero-shot learning (ZSL) are typically suitable for offline learning and cannot continually learn from sequential streaming data. The sequential data comes in the form of tasks during training. Recently, a few attempts have been made to handle this issue and develop continual ZSL (CZSL) methods. However, these CZSL methods require clear task-boundary information between the tasks during training, which is not practically possible. This paper proposes a task-free (i.e., task-agnostic) CZSL method, which does not require any task information during continual learning. The proposed task-free CZSL method employs a variational autoencoder (VAE) for performing ZSL. To develop the CZSL method, we combine the concept of experience replay with knowledge distillation and regularization. Here, knowledge distillation is performed using the training sample's dark knowledge, which essentially helps overcome the catastrophic forgetting issue. Further, it is enabled for task-free learning using short-term memory. Finally, a classifier is trained on the synthetic features generated at the latent space of the VAE. Moreover, the experiments are conducted in a challenging and practical ZSL setup, i.e., generalized ZSL (GZSL). These experiments are conducted for two kinds of single-head continual learning settings: (i) mild setting-: task-boundary is known only during training but not during testing; (ii) strict setting-: task-boundary is not known at training, as well as testing. Experimental results on five benchmark datasets exhibit the validity of the approach for CZSL.
Generative Replay-based Continual Zero-Shot Learning
Jan 22, 2021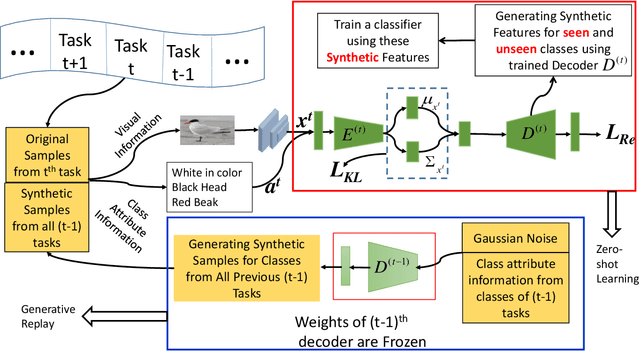


Zero-shot learning is a new paradigm to classify objects from classes that are not available at training time. Zero-shot learning (ZSL) methods have attracted considerable attention in recent years because of their ability to classify unseen/novel class examples. Most of the existing approaches on ZSL works when all the samples from seen classes are available to train the model, which does not suit real life. In this paper, we tackle this hindrance by developing a generative replay-based continual ZSL (GRCZSL). The proposed method endows traditional ZSL to learn from streaming data and acquire new knowledge without forgetting the previous tasks' gained experience. We handle catastrophic forgetting in GRCZSL by replaying the synthetic samples of seen classes, which have appeared in the earlier tasks. These synthetic samples are synthesized using the trained conditional variational autoencoder (VAE) over the immediate past task. Moreover, we only require the current and immediate previous VAE at any time for training and testing. The proposed GRZSL method is developed for a single-head setting of continual learning, simulating a real-world problem setting. In this setting, task identity is given during training but unavailable during testing. GRCZSL performance is evaluated on five benchmark datasets for the generalized setup of ZSL with fixed and incremental class settings of continual learning. Experimental results show that the proposed method significantly outperforms the baseline method and makes it more suitable for real-world applications.
Meta-Cognition-Based Simple And Effective Approach To Object Detection
Dec 02, 2020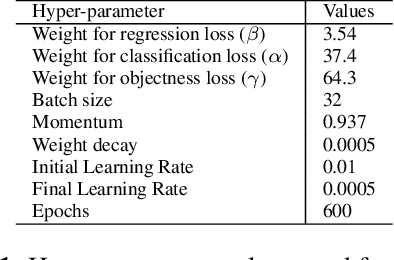



Recently, many researchers have attempted to improve deep learning-based object detection models, both in terms of accuracy and operational speeds. However, frequently, there is a trade-off between speed and accuracy of such models, which encumbers their use in practical applications such as autonomous navigation. In this paper, we explore a meta-cognitive learning strategy for object detection to improve generalization ability while at the same time maintaining detection speed. The meta-cognitive method selectively samples the object instances in the training dataset to reduce overfitting. We use YOLO v3 Tiny as a base model for the work and evaluate the performance using the MS COCO dataset. The experimental results indicate an improvement in absolute precision of 2.6% (minimum), and 4.4% (maximum), with no overhead to inference time.
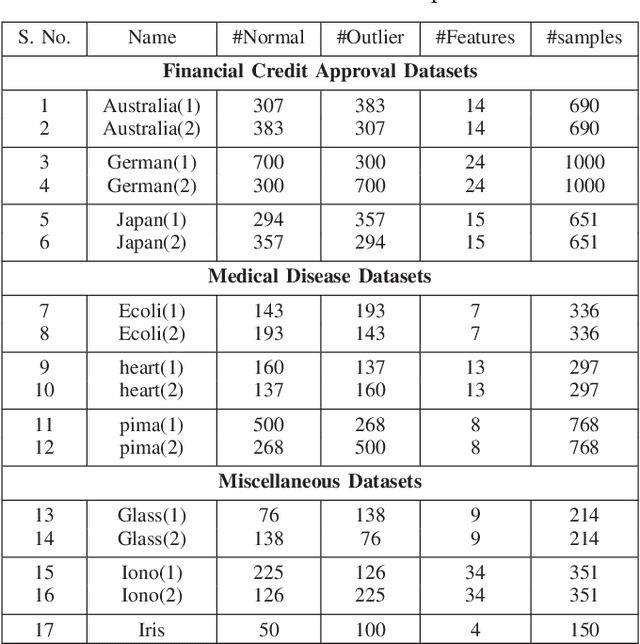
Minimum Variance Embedded Auto-associative Kernel Extreme Learning Machine for One-class Classification
Nov 24, 2020
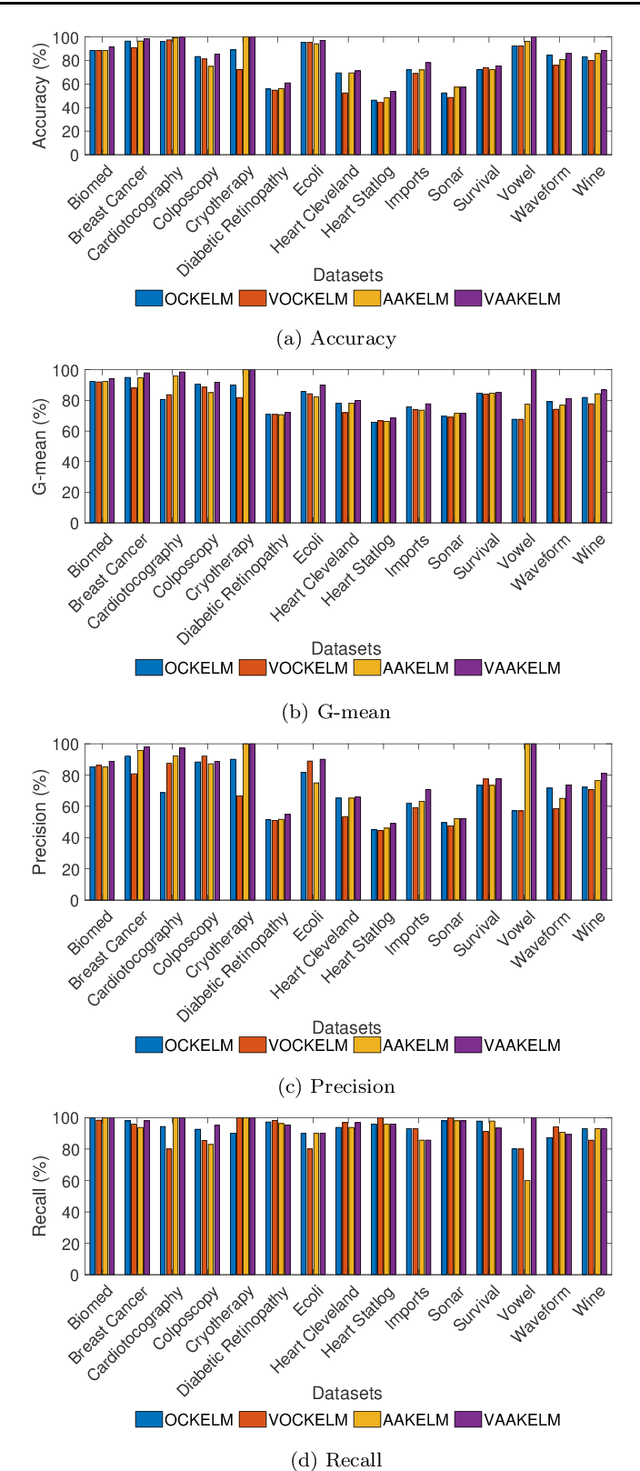


One-class classification (OCC) needs samples from only a single class to train the classifier. Recently, an auto-associative kernel extreme learning machine was developed for the OCC task. This paper introduces a novel extension of this classifier by embedding minimum variance information within its architecture and is referred to as VAAKELM. The minimum variance embedding forces the network output weights to focus in regions of low variance and reduces the intra-class variance. This leads to a better separation of target samples and outliers, resulting in an improvement in the generalization performance of the classifier. The proposed classifier follows a reconstruction-based approach to OCC and minimizes the reconstruction error by using the kernel extreme learning machine as the base classifier. It uses the deviation in reconstruction error to identify the outliers. We perform experiments on 15 small-size and 10 medium-size one-class benchmark datasets to demonstrate the efficiency of the proposed classifier. We compare the results with 13 existing one-class classifiers by considering the mean F1 score as the comparison metric. The experimental results show that VAAKELM consistently performs better than the existing classifiers, making it a viable alternative for the OCC task.
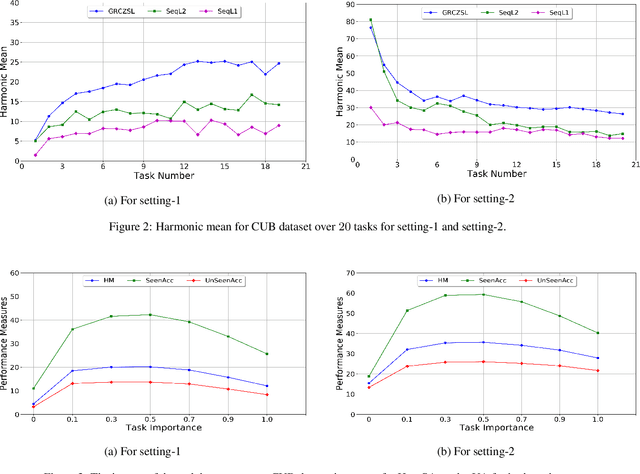
Generalized Continual Zero-Shot Learning
Nov 17, 2020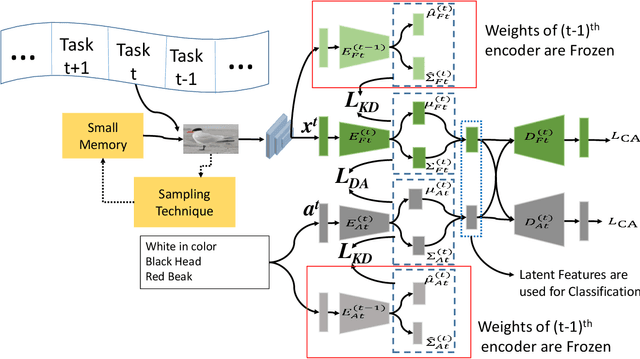
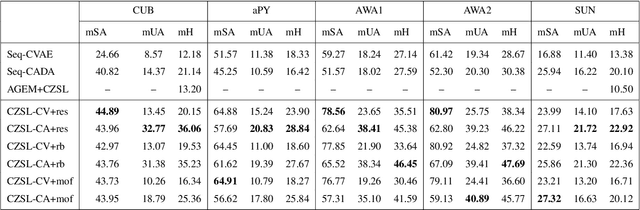
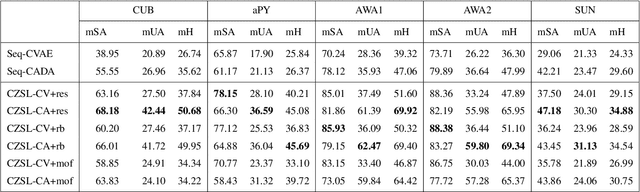
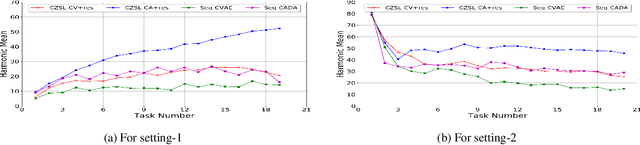
Recently, zero-shot learning (ZSL) emerged as an exciting topic and attracted a lot of attention. ZSL aims to classify unseen classes by transferring the knowledge from seen classes to unseen classes based on the class description. Despite showing promising performance, ZSL approaches assume that the training samples from all seen classes are available during the training, which is practically not feasible. To address this issue, we propose a more generalized and practical setup for ZSL, i.e., continual ZSL (CZSL), where classes arrive sequentially in the form of a task and it actively learns from the changing environment by leveraging the past experience. Further, to enhance the reliability, we develop CZSL for a single head continual learning setting where task identity is revealed during the training process but not during the testing. To avoid catastrophic forgetting and intransigence, we use knowledge distillation and storing and replay the few samples from previous tasks using a small episodic memory. We develop baselines and evaluate generalized CZSL on five ZSL benchmark datasets for two different settings of continual learning: with and without class incremental. Moreover, CZSL is developed for two types of variational autoencoders, which generates two types of features for classification: (i) generated features at output space and (ii) generated discriminative features at the latent space. The experimental results clearly indicate the single head CZSL is more generalizable and suitable for practical applications.
OCKELM+: Kernel Extreme Learning Machine based One-class Classification using Privileged Information (or KOC+: Kernel Ridge Regression or Least Square SVM with zero bias based One-class Classification using Privileged Information)
Apr 13, 2019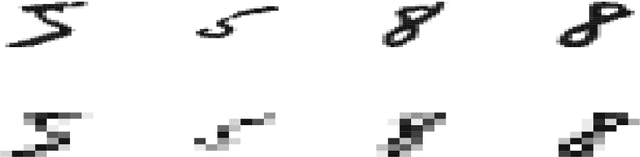
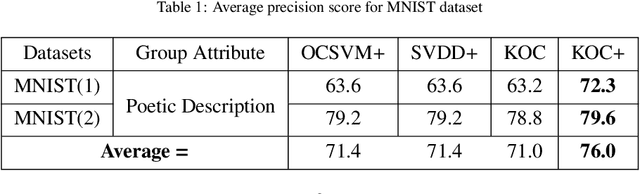

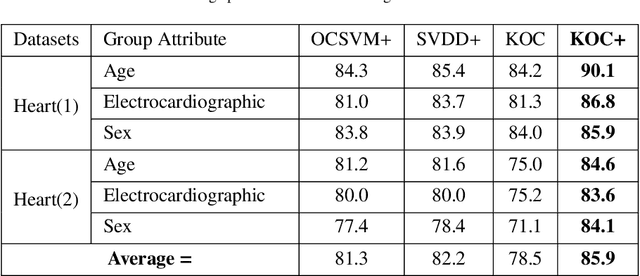
Kernel method-based one-class classifier is mainly used for outlier or novelty detection. In this letter, kernel ridge regression (KRR) based one-class classifier (KOC) has been extended for learning using privileged information (LUPI). LUPI-based KOC method is referred to as KOC+. This privileged information is available as a feature with the dataset but only for training (not for testing). KOC+ utilizes the privileged information differently compared to normal feature information by using a so-called correction function. Privileged information helps KOC+ in achieving better generalization performance which is exhibited in this letter by testing the classifiers with and without privileged information. Existing and proposed classifiers are evaluated on the datasets from UCI machine learning repository and also on MNIST dataset. Moreover, experimental results evince the advantage of KOC+ over KOC and support vector machine (SVM) based one-class classifiers.
Graph-Embedded Multi-layer Kernel Extreme Learning Machine for One-class Classification or (Graph-Embedded Multi-layer Kernel Ridge Regression for One-class Classification)
Apr 13, 2019
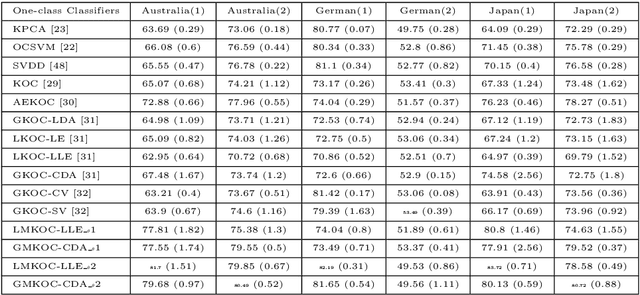
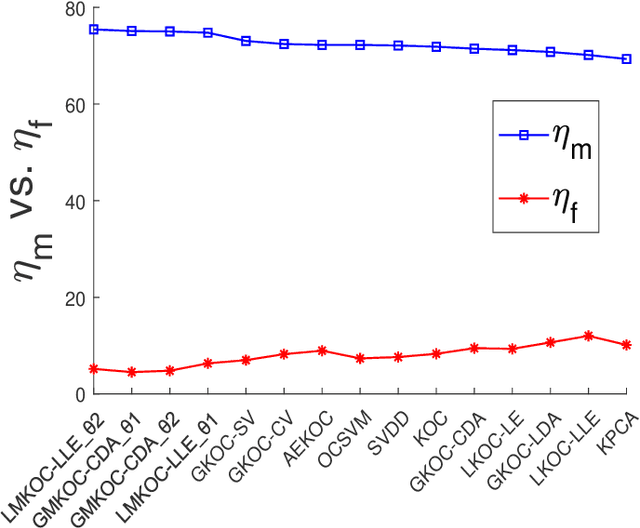
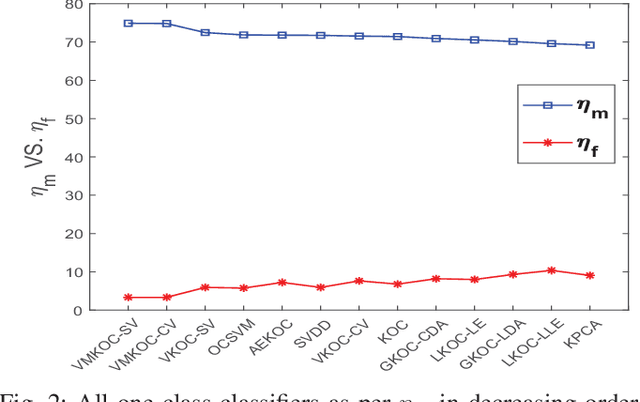
A brain can detect outlier just by using only normal samples. Similarly, one-class classification (OCC) also uses only normal samples to train the model and trained model can be used for outlier detection. In this paper, a multi-layer architecture for OCC is proposed by stacking various Graph-Embedded Kernel Ridge Regression (KRR) based Auto-Encoders in a hierarchical fashion. These Auto-Encoders are formulated under two types of Graph-Embedding, namely, local and global variance-based embedding. This Graph-Embedding explores the relationship between samples and multi-layers of Auto-Encoder project the input features into new feature space. The last layer of this proposed architecture is Graph-Embedded regression-based one-class classifier. The Auto-Encoders use an unsupervised approach of learning and the final layer uses semi-supervised (trained by only positive samples and obtained closed-form solution) approach to learning. The proposed method is experimentally evaluated on 21 publicly available benchmark datasets. Experimental results verify the effectiveness of the proposed one-class classifiers over 11 existing state-of-the-art kernel-based one-class classifiers. Friedman test is also performed to verify the statistical significance of the claim of the superiority of the proposed one-class classifiers over the existing state-of-the-art methods. By using two types of Graph-Embedding, 4 variants of Graph-Embedded multi-layer KRR-based one-class classifier has been presented in this paper. All 4 variants performed better than the existing one-class classifiers in terms of various discussed criteria in this paper. Hence, it can be a viable alternative for OCC task. In the future, various other types of Auto-Encoders can be explored within proposed architecture.
Localized Multiple Kernel Learning for Anomaly Detection: One-class Classification
Jul 17, 2018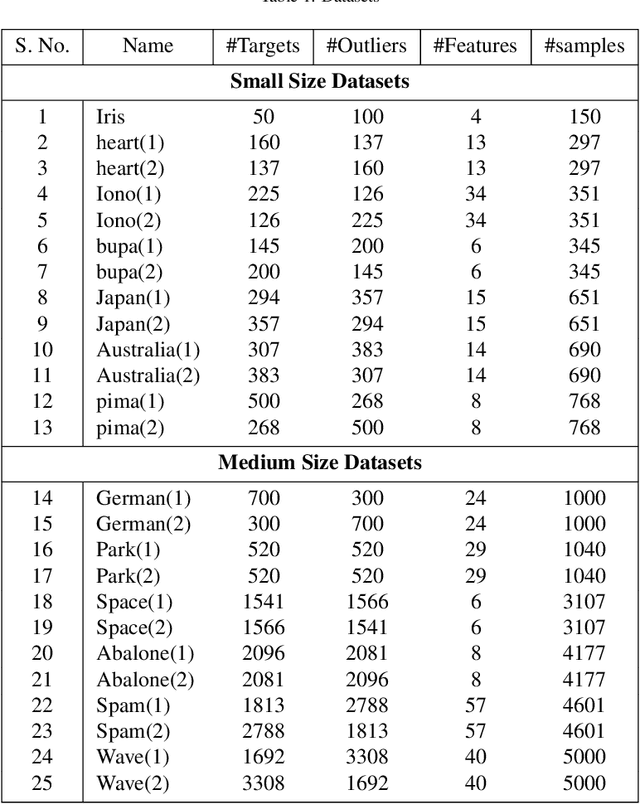
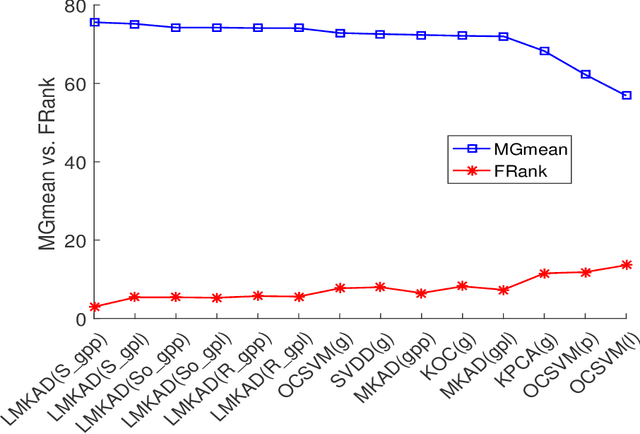
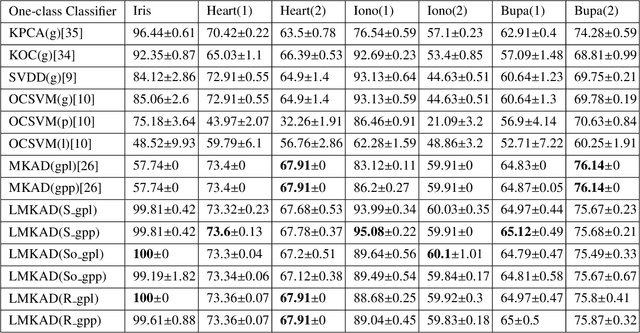
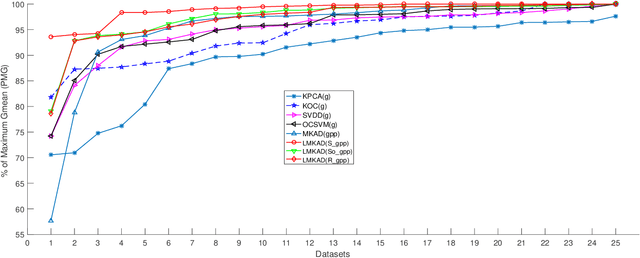
Multi-kernel learning has been well explored in the recent past and has exhibited promising outcomes for multi-class classification and regression tasks. In this paper, we present a multiple kernel learning approach for the One-class Classification (OCC) task and employ it for anomaly detection. Recently, the basic multi-kernel approach has been proposed to solve the OCC problem, which is simply a convex combination of different kernels with equal weights. This paper proposes a Localized Multiple Kernel learning approach for Anomaly Detection (LMKAD) using OCC, where the weight for each kernel is assigned locally. Proposed LMKAD approach adapts the weight for each kernel using a gating function. The parameters of the gating function and one-class classifier are optimized simultaneously through a two-step optimization process. We present the empirical results of the performance of LMKAD on 25 benchmark datasets from various disciplines. This performance is evaluated against existing Multi Kernel Anomaly Detection (MKAD) algorithm, and four other existing kernel-based one-class classifiers to showcase the credibility of our approach. Our algorithm achieves significantly better Gmean scores while using a lesser number of support vectors compared to MKAD. Friedman test is also performed to verify the statistical significance of the results claimed in this paper.
Multi-layer Kernel Ridge Regression for One-class Classification
Jun 01, 2018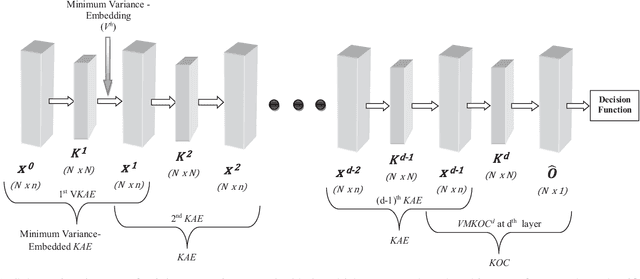

In this paper, a multi-layer architecture (in a hierarchical fashion) by stacking various Kernel Ridge Regression (KRR) based Auto-Encoder for one-class classification is proposed and is referred as MKOC. MKOC has many layers of Auto-Encoders to project the input features into new feature space and the last layer was regression based one class classifier. The Auto-Encoders use an unsupervised approach of learning and the final layer uses semi-supervised (trained by only positive samples) approach of learning. The proposed MKOC is experimentally evaluated on 15 publicly available benchmark datasets. Experimental results verify the effectiveness of the proposed approach over 11 existing state-of-the-art kernel-based one-class classifiers. Friedman test is also performed to verify the statistical significance of the claim of the superiority of the proposed one-class classifiers over the existing state-of-the-art methods.
Online Learning with Regularized Kernel for One-class Classification
Apr 09, 2018
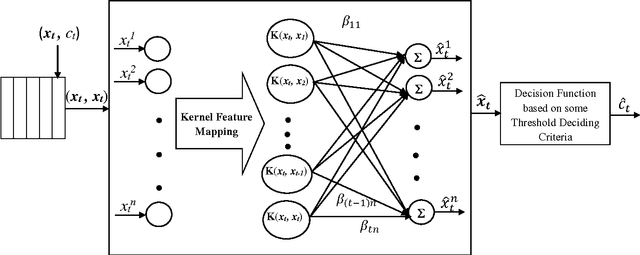
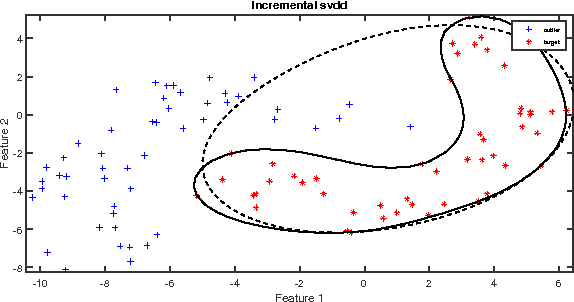

This paper presents an online learning with regularized kernel based one-class extreme learning machine (ELM) classifier and is referred as online RK-OC-ELM. The baseline kernel hyperplane model considers whole data in a single chunk with regularized ELM approach for offline learning in case of one-class classification (OCC). Further, the basic hyper plane model is adapted in an online fashion from stream of training samples in this paper. Two frameworks viz., boundary and reconstruction are presented to detect the target class in online RKOC-ELM. Boundary framework based one-class classifier consists of single node output architecture and classifier endeavors to approximate all data to any real number. However, one-class classifier based on reconstruction framework is an autoencoder architecture, where output nodes are identical to input nodes and classifier endeavor to reconstruct input layer at the output layer. Both these frameworks employ regularized kernel ELM based online learning and consistency based model selection has been employed to select learning algorithm parameters. The performance of online RK-OC-ELM has been evaluated on standard benchmark datasets as well as on artificial datasets and the results are compared with existing state-of-the art one-class classifiers. The results indicate that the online learning one-class classifier is slightly better or same as batch learning based approaches. As, base classifier used for the proposed classifiers are based on the ELM, hence, proposed classifiers would also inherit the benefit of the base classifier i.e. it will perform faster computation compared to traditional autoencoder based one-class classifier.