 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorFit : Adaptive Singular & Bias Vector Fine-Tuning of Pre-trained Foundation Models
Mar 25, 2025Popular PEFT methods achieve parameter efficiency by assuming that incremental weight updates are inherently low-rank, which often leads to a performance gap compared to full fine-tuning. While recent methods have attempted to address this limitation, they typically lack sufficient parameter and memory efficiency. We propose VectorFit, an effective and easily deployable approach that adaptively trains the singular vectors and biases of pre-trained weight matrices. We demonstrate that the utilization of structural and transformational characteristics of pre-trained weights enables high-rank updates comparable to those of full fine-tuning. As a result, VectorFit achieves superior performance with 9X less trainable parameters compared to state-of-the-art PEFT methods. Through extensive experiments over 17 datasets spanning diverse language and vision tasks such as natural language understanding and generation, question answering, image classification, and image generation, we exhibit that VectorFit consistently outperforms baselines, even in extremely low-budget scenarios.
Obfuscated Memory Malware Detection
Aug 23, 2024



Providing security for information is highly critical in the current era with devices enabled with smart technology, where assuming a day without the internet is highly impossible. Fast internet at a cheaper price, not only made communication easy for legitimate users but also for cybercriminals to induce attacks in various dimensions to breach privacy and security. Cybercriminals gain illegal access and breach the privacy of users to harm them in multiple ways. Malware is one such tool used by hackers to execute their malicious intent. Development in AI technology is utilized by malware developers to cause social harm. In this work, we intend to show how Artificial Intelligence and Machine learning can be used to detect and mitigate these cyber-attacks induced by malware in specific obfuscated malware. We conducted experiments with memory feature engineering on memory analysis of malware samples. Binary classification can identify whether a given sample is malware or not, but identifying the type of malware will only guide what next step to be taken for that malware, to stop it from proceeding with its further action. Hence, we propose a multi-class classification model to detect the three types of obfuscated malware with an accuracy of 89.07% using the Classic Random Forest algorithm. To the best of our knowledge, there is very little amount of work done in classifying multiple obfuscated malware by a single model. We also compared our model with a few state-of-the-art models and found it comparatively better.
System Network Analytics: Evolution and Stable Rules of a State Series
Oct 28, 2022
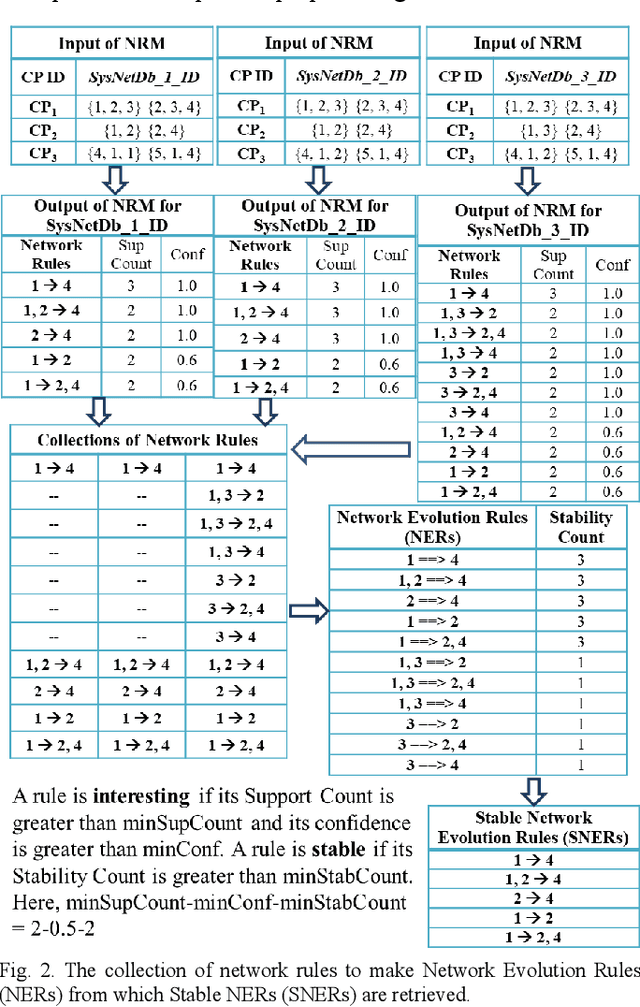
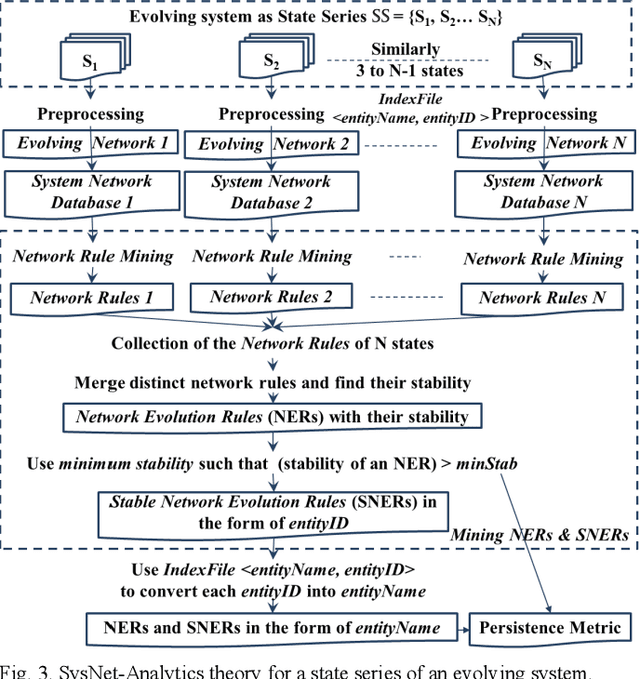
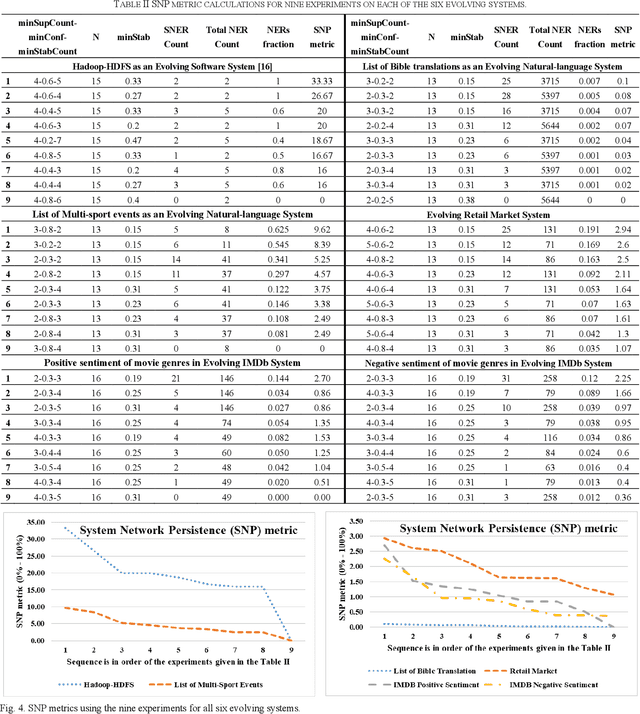
System Evolution Analytics on a system that evolves is a challenge because it makes a State Series SS = {S1, S2... SN} (i.e., a set of states ordered by time) with several inter-connected entities changing over time. We present stability characteristics of interesting evolution rules occurring in multiple states. We defined an evolution rule with its stability as the fraction of states in which the rule is interesting. Extensively, we defined stable rule as the evolution rule having stability that exceeds a given threshold minimum stability (minStab). We also defined persistence metric, a quantitative measure of persistent entity-connections. We explain this with an approach and algorithm for System Network Analytics (SysNet-Analytics), which uses minStab to retrieve Network Evolution Rules (NERs) and Stable NERs (SNERs). The retrieved information is used to calculate a proposed System Network Persistence (SNP) metric. This work is automated as a SysNet-Analytics Tool to demonstrate application on real world systems including: software system, natural-language system, retail market system, and IMDb system. We quantified stability and persistence of entity-connections in a system state series. This results in evolution information, which helps in system evolution analytics based on knowledge discovery and data mining.
* Accepted on IEEE DSAA and Video Presentation https://www.youtube.com/watch?v=ohOeTXoI-IY&list=PLtvWi5o3JBnF3yxcjGdT4KCDLxRBIpsyR
Enhanced Opposition Differential Evolution Algorithm for Multimodal Optimization
Aug 23, 2022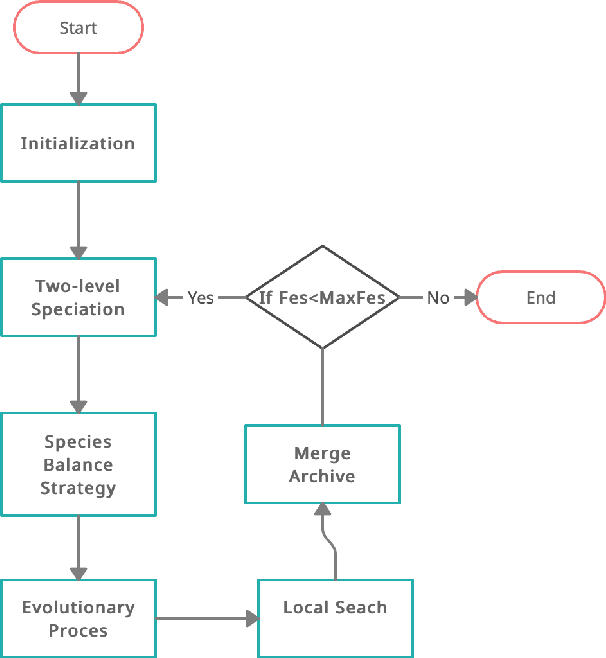
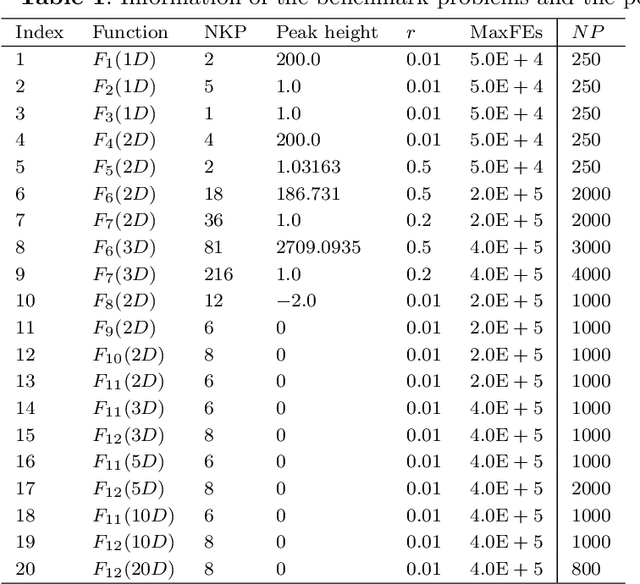


Most of the real-world problems are multimodal in nature that consists of multiple optimum values. Multimodal optimization is defined as the process of finding multiple global and local optima (as opposed to a single solution) of a function. It enables a user to switch between different solutions as per the need while still maintaining the optimal system performance. Classical gradient-based methods fail for optimization problems in which the objective functions are either discontinuous or non-differentiable. Evolutionary Algorithms (EAs) are able to find multiple solutions within a population in a single algorithmic run as compared to classical optimization techniques that need multiple restarts and multiple runs to find different solutions. Hence, several EAs have been proposed to solve such kinds of problems. However, Differential Evolution (DE) algorithm is a population-based heuristic method that can solve such optimization problems, and it is simple to implement. The potential challenge in Multi-Modal Optimization Problems (MMOPs) is to search the function space efficiently to locate most of the peaks accurately. The optimization problem could be to minimize or maximize a given objective function and we aim to solve the maximization problems on multimodal functions in this study. Hence, we have proposed an algorithm known as Enhanced Opposition Differential Evolution (EODE) algorithm to solve the MMOPs. The proposed algorithm has been tested on IEEE Congress on Evolutionary Computation (CEC) 2013 benchmark functions, and it achieves competitive results compared to the existing state-of-the-art approaches.
A Novel Scalable Apache Spark Based Feature Extraction Approaches for Huge Protein Sequence and their Clustering Performance Analysis
Apr 21, 2022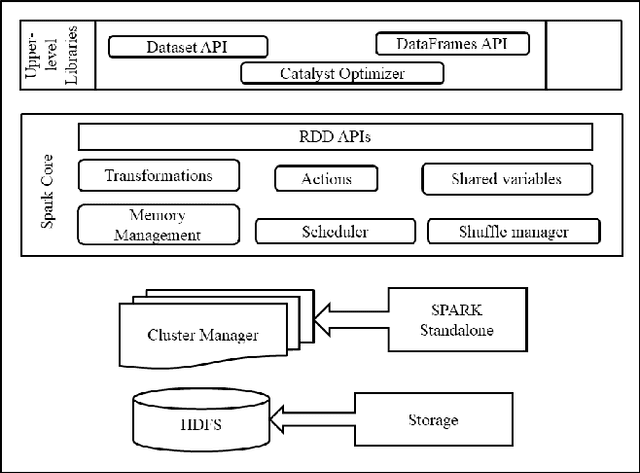

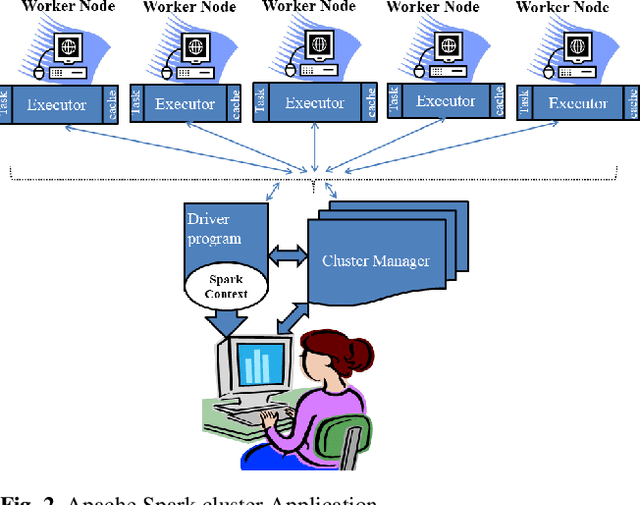

Genome sequencing projects are rapidly increasing the number of high-dimensional protein sequence datasets. Clustering a high-dimensional protein sequence dataset using traditional machine learning approaches poses many challenges. Many different feature extraction methods exist and are widely used. However, extracting features from millions of protein sequences becomes impractical because they are not scalable with current algorithms. Therefore, there is a need for an efficient feature extraction approach that extracts significant features. We have proposed two scalable feature extraction approaches for extracting features from huge protein sequences using Apache Spark, which are termed 60d-SPF (60-dimensional Scalable Protein Feature) and 6d-SCPSF (6-dimensional Scalable Co-occurrence-based Probability-Specific Feature). The proposed 60d-SPF and 6d-SCPSF approaches capture the statistical properties of amino acids to create a fixed-length numeric feature vector that represents each protein sequence in terms of 60-dimensional and 6-dimensional features, respectively. The preprocessed huge protein sequences are used as an input in two clustering algorithms, i.e., Scalable Random Sampling with Iterative Optimization Fuzzy c-Means (SRSIO-FCM) and Scalable Literal Fuzzy C-Means (SLFCM) for clustering. We have conducted extensive experiments on various soybean protein datasets to demonstrate the effectiveness of the proposed feature extraction methods, 60d-SPF, 6d-SCPSF, and existing feature extraction methods on SRSIO-FCM and SLFCM clustering algorithms. The reported results in terms of the Silhouette index and the Davies-Bouldin index show that the proposed 60d-SPF extraction method on SRSIO-FCM and SLFCM clustering algorithms achieves significantly better results than the proposed 6d-SCPSF and existing feature extraction approaches.
Minimum Variance Embedded Auto-associative Kernel Extreme Learning Machine for One-class Classification
Nov 24, 2020
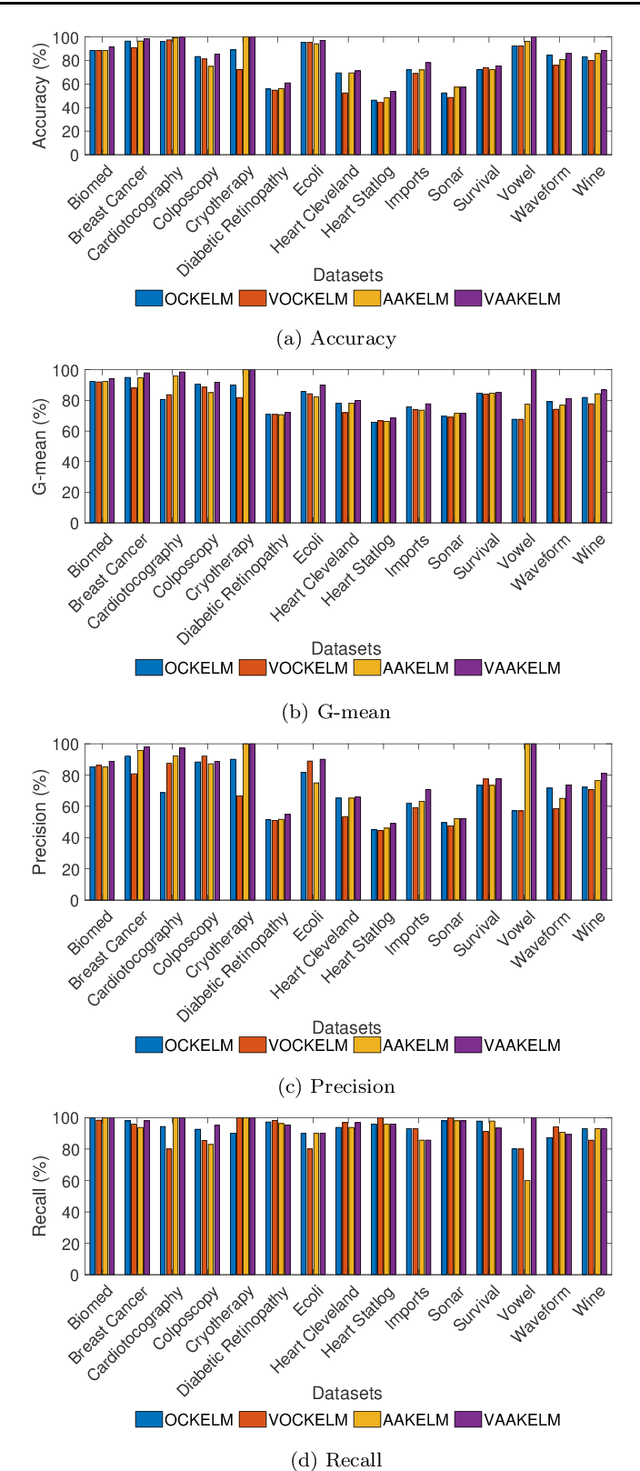


One-class classification (OCC) needs samples from only a single class to train the classifier. Recently, an auto-associative kernel extreme learning machine was developed for the OCC task. This paper introduces a novel extension of this classifier by embedding minimum variance information within its architecture and is referred to as VAAKELM. The minimum variance embedding forces the network output weights to focus in regions of low variance and reduces the intra-class variance. This leads to a better separation of target samples and outliers, resulting in an improvement in the generalization performance of the classifier. The proposed classifier follows a reconstruction-based approach to OCC and minimizes the reconstruction error by using the kernel extreme learning machine as the base classifier. It uses the deviation in reconstruction error to identify the outliers. We perform experiments on 15 small-size and 10 medium-size one-class benchmark datasets to demonstrate the efficiency of the proposed classifier. We compare the results with 13 existing one-class classifiers by considering the mean F1 score as the comparison metric. The experimental results show that VAAKELM consistently performs better than the existing classifiers, making it a viable alternative for the OCC task.
OCKELM+: Kernel Extreme Learning Machine based One-class Classification using Privileged Information (or KOC+: Kernel Ridge Regression or Least Square SVM with zero bias based One-class Classification using Privileged Information)
Apr 13, 2019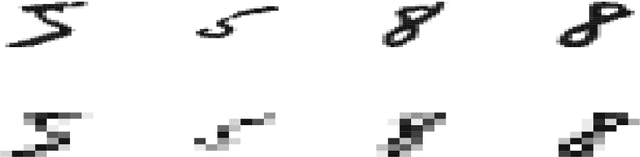
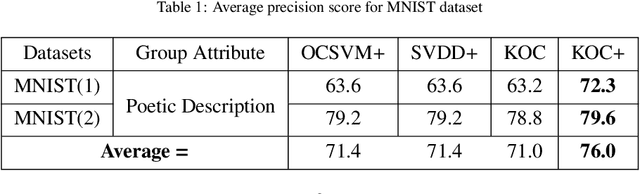

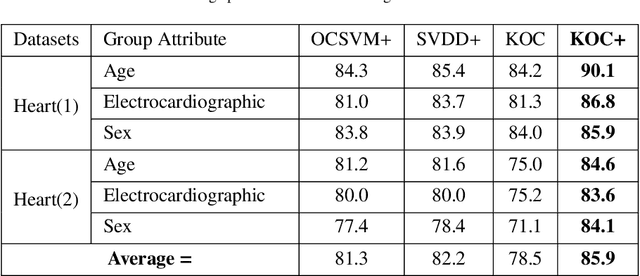
Kernel method-based one-class classifier is mainly used for outlier or novelty detection. In this letter, kernel ridge regression (KRR) based one-class classifier (KOC) has been extended for learning using privileged information (LUPI). LUPI-based KOC method is referred to as KOC+. This privileged information is available as a feature with the dataset but only for training (not for testing). KOC+ utilizes the privileged information differently compared to normal feature information by using a so-called correction function. Privileged information helps KOC+ in achieving better generalization performance which is exhibited in this letter by testing the classifiers with and without privileged information. Existing and proposed classifiers are evaluated on the datasets from UCI machine learning repository and also on MNIST dataset. Moreover, experimental results evince the advantage of KOC+ over KOC and support vector machine (SVM) based one-class classifiers.
Graph-Embedded Multi-layer Kernel Extreme Learning Machine for One-class Classification or (Graph-Embedded Multi-layer Kernel Ridge Regression for One-class Classification)
Apr 13, 2019
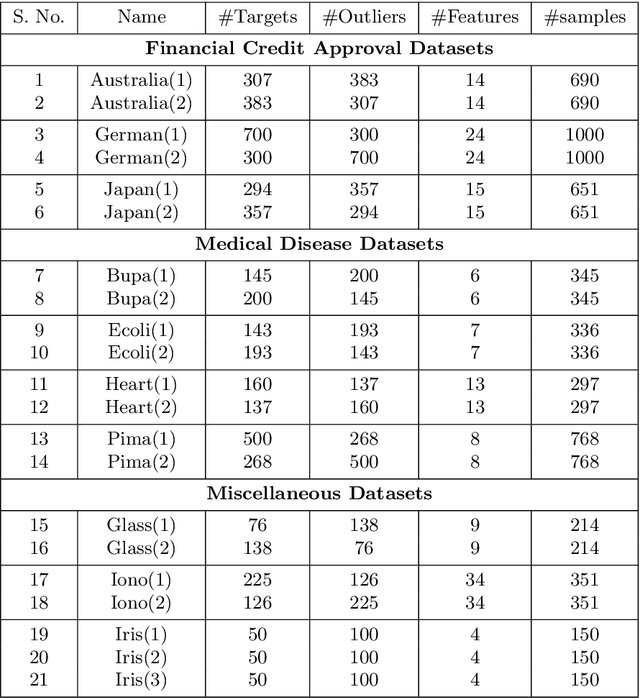
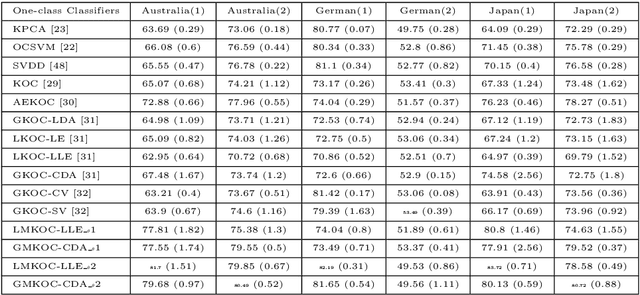
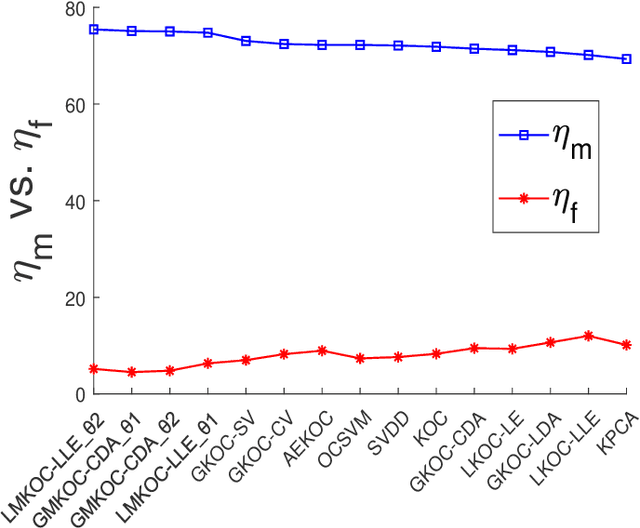
A brain can detect outlier just by using only normal samples. Similarly, one-class classification (OCC) also uses only normal samples to train the model and trained model can be used for outlier detection. In this paper, a multi-layer architecture for OCC is proposed by stacking various Graph-Embedded Kernel Ridge Regression (KRR) based Auto-Encoders in a hierarchical fashion. These Auto-Encoders are formulated under two types of Graph-Embedding, namely, local and global variance-based embedding. This Graph-Embedding explores the relationship between samples and multi-layers of Auto-Encoder project the input features into new feature space. The last layer of this proposed architecture is Graph-Embedded regression-based one-class classifier. The Auto-Encoders use an unsupervised approach of learning and the final layer uses semi-supervised (trained by only positive samples and obtained closed-form solution) approach to learning. The proposed method is experimentally evaluated on 21 publicly available benchmark datasets. Experimental results verify the effectiveness of the proposed one-class classifiers over 11 existing state-of-the-art kernel-based one-class classifiers. Friedman test is also performed to verify the statistical significance of the claim of the superiority of the proposed one-class classifiers over the existing state-of-the-art methods. By using two types of Graph-Embedding, 4 variants of Graph-Embedded multi-layer KRR-based one-class classifier has been presented in this paper. All 4 variants performed better than the existing one-class classifiers in terms of various discussed criteria in this paper. Hence, it can be a viable alternative for OCC task. In the future, various other types of Auto-Encoders can be explored within proposed architecture.
Localized Multiple Kernel Learning for Anomaly Detection: One-class Classification
Jul 17, 2018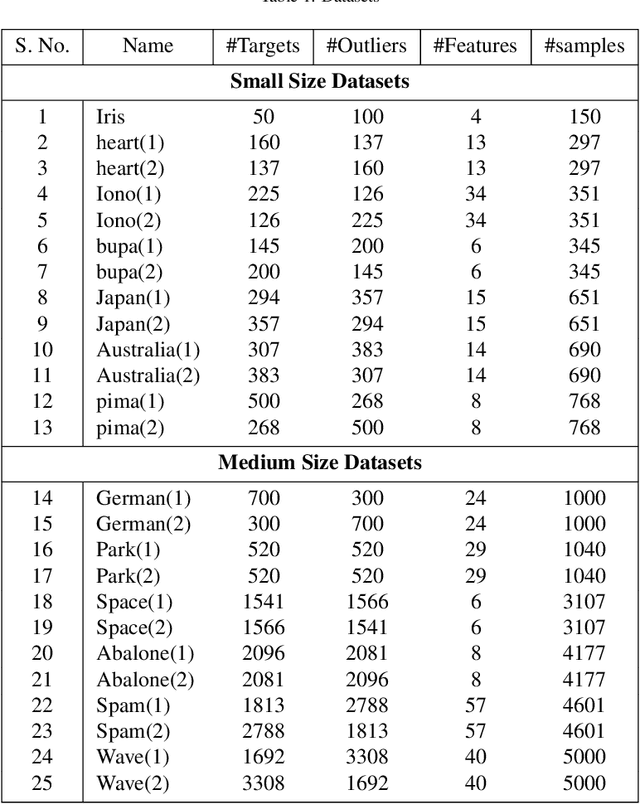
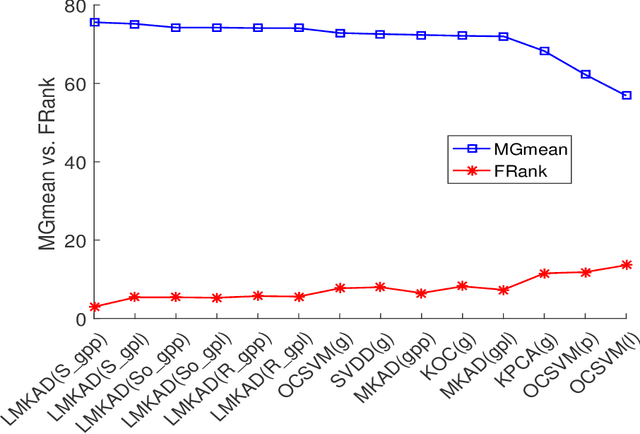
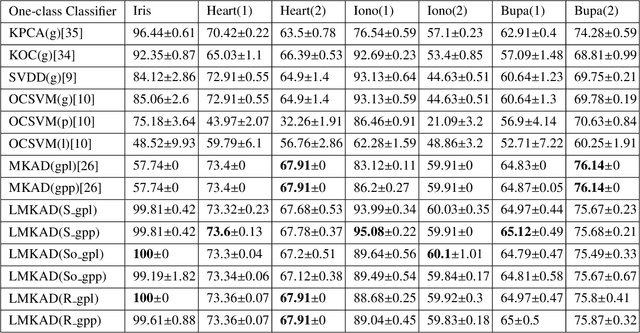
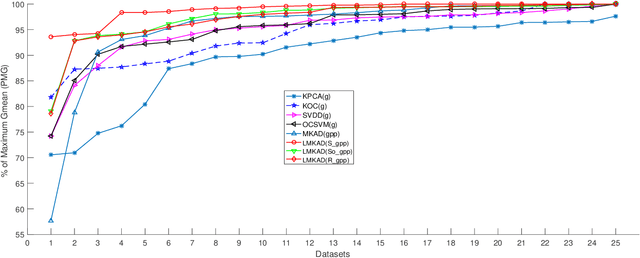
Multi-kernel learning has been well explored in the recent past and has exhibited promising outcomes for multi-class classification and regression tasks. In this paper, we present a multiple kernel learning approach for the One-class Classification (OCC) task and employ it for anomaly detection. Recently, the basic multi-kernel approach has been proposed to solve the OCC problem, which is simply a convex combination of different kernels with equal weights. This paper proposes a Localized Multiple Kernel learning approach for Anomaly Detection (LMKAD) using OCC, where the weight for each kernel is assigned locally. Proposed LMKAD approach adapts the weight for each kernel using a gating function. The parameters of the gating function and one-class classifier are optimized simultaneously through a two-step optimization process. We present the empirical results of the performance of LMKAD on 25 benchmark datasets from various disciplines. This performance is evaluated against existing Multi Kernel Anomaly Detection (MKAD) algorithm, and four other existing kernel-based one-class classifiers to showcase the credibility of our approach. Our algorithm achieves significantly better Gmean scores while using a lesser number of support vectors compared to MKAD. Friedman test is also performed to verify the statistical significance of the results claimed in this paper.
Multi-layer Kernel Ridge Regression for One-class Classification
Jun 01, 2018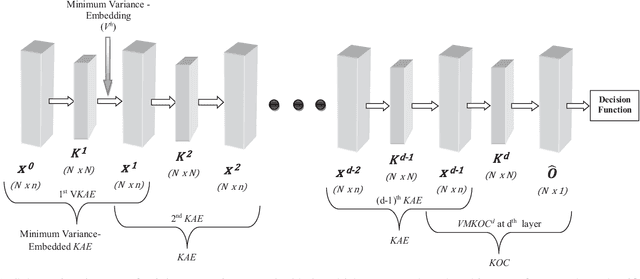
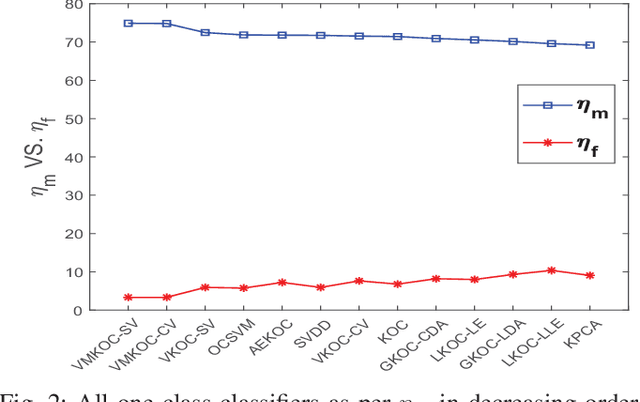

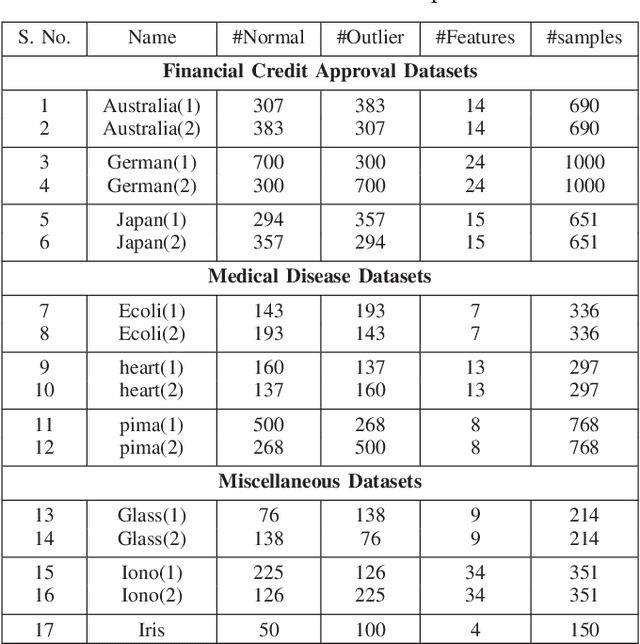
In this paper, a multi-layer architecture (in a hierarchical fashion) by stacking various Kernel Ridge Regression (KRR) based Auto-Encoder for one-class classification is proposed and is referred as MKOC. MKOC has many layers of Auto-Encoders to project the input features into new feature space and the last layer was regression based one class classifier. The Auto-Encoders use an unsupervised approach of learning and the final layer uses semi-supervised (trained by only positive samples) approach of learning. The proposed MKOC is experimentally evaluated on 15 publicly available benchmark datasets. Experimental results verify the effectiveness of the proposed approach over 11 existing state-of-the-art kernel-based one-class classifiers. Friedman test is also performed to verify the statistical significance of the claim of the superiority of the proposed one-class classifiers over the existing state-of-the-art methods.