 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Scalable Apache Spark Based Feature Extraction Approaches for Huge Protein Sequence and their Clustering Performance Analysis
Paper and Code
Apr 21, 2022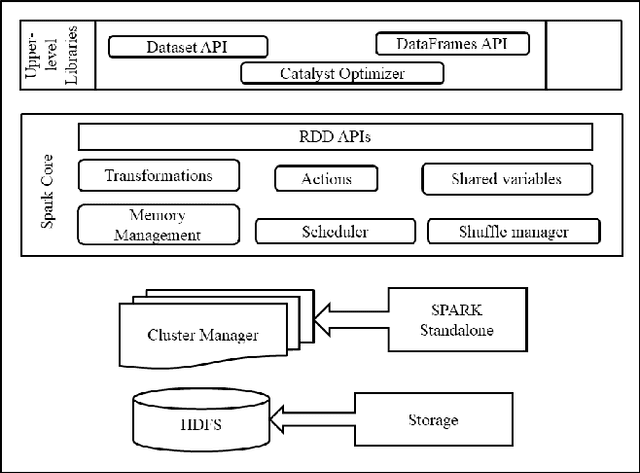

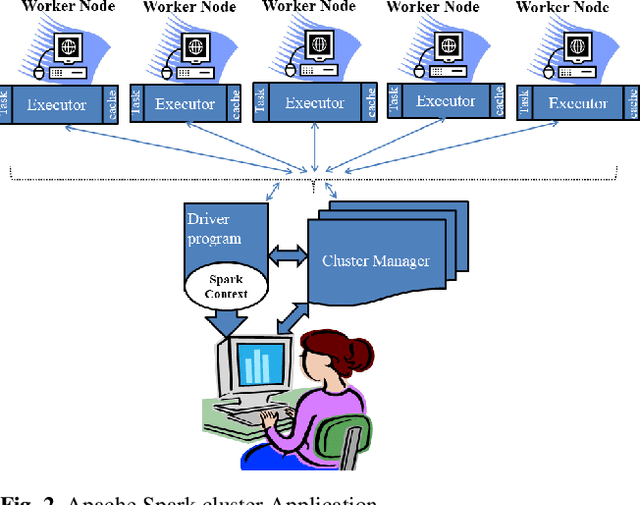

Genome sequencing projects are rapidly increasing the number of high-dimensional protein sequence datasets. Clustering a high-dimensional protein sequence dataset using traditional machine learning approaches poses many challenges. Many different feature extraction methods exist and are widely used. However, extracting features from millions of protein sequences becomes impractical because they are not scalable with current algorithms. Therefore, there is a need for an efficient feature extraction approach that extracts significant features. We have proposed two scalable feature extraction approaches for extracting features from huge protein sequences using Apache Spark, which are termed 60d-SPF (60-dimensional Scalable Protein Feature) and 6d-SCPSF (6-dimensional Scalable Co-occurrence-based Probability-Specific Feature). The proposed 60d-SPF and 6d-SCPSF approaches capture the statistical properties of amino acids to create a fixed-length numeric feature vector that represents each protein sequence in terms of 60-dimensional and 6-dimensional features, respectively. The preprocessed huge protein sequences are used as an input in two clustering algorithms, i.e., Scalable Random Sampling with Iterative Optimization Fuzzy c-Means (SRSIO-FCM) and Scalable Literal Fuzzy C-Means (SLFCM) for clustering. We have conducted extensive experiments on various soybean protein datasets to demonstrate the effectiveness of the proposed feature extraction methods, 60d-SPF, 6d-SCPSF, and existing feature extraction methods on SRSIO-FCM and SLFCM clustering algorithms. The reported results in terms of the Silhouette index and the Davies-Bouldin index show that the proposed 60d-SPF extraction method on SRSIO-FCM and SLFCM clustering algorithms achieves significantly better results than the proposed 6d-SCPSF and existing feature extraction approaches.