 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Script E2E framework for Multilingual and Code-Switching ASR
Jun 02, 2021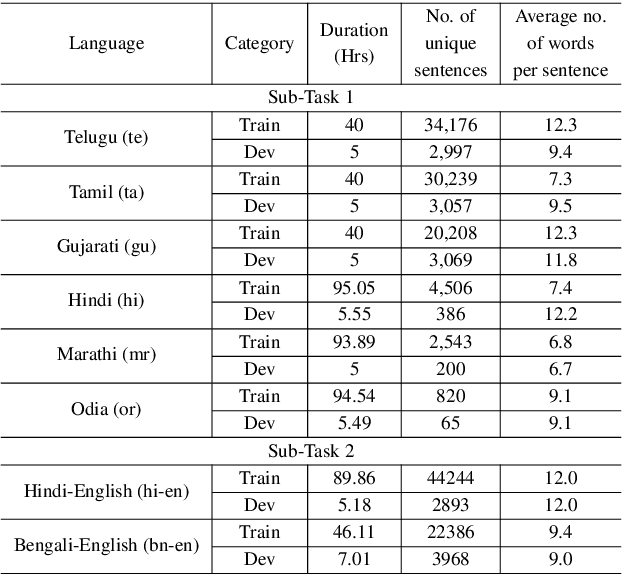
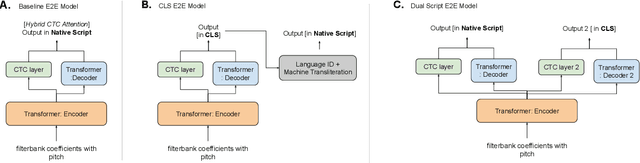
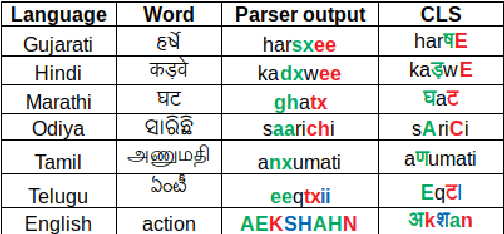
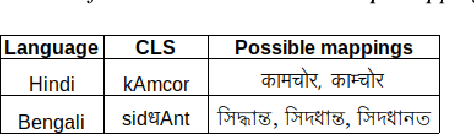
India is home to multiple languages, and training automatic speech recognition (ASR) systems for languages is challenging. Over time, each language has adopted words from other languages, such as English, leading to code-mixing. Most Indian languages also have their own unique scripts, which poses a major limitation in training multilingual and code-switching ASR systems. Inspired by results in text-to-speech synthesis, in this work, we use an in-house rule-based phoneme-level common label set (CLS) representation to train multilingual and code-switching ASR for Indian languages. We propose two end-to-end (E2E) ASR systems. In the first system, the E2E model is trained on the CLS representation, and we use a novel data-driven back-end to recover the native language script. In the second system, we propose a modification to the E2E model, wherein the CLS representation and the native language characters are used simultaneously for training. We show our results on the multilingual and code-switching tasks of the Indic ASR Challenge 2021. Our best results achieve 6% and 5% improvement (approx) in word error rate over the baseline system for the multilingual and code-switching tasks, respectively, on the challenge development data.
Evidence of Task-Independent Person-Specific Signatures in EEG using Subspace Techniques
Jul 27, 2020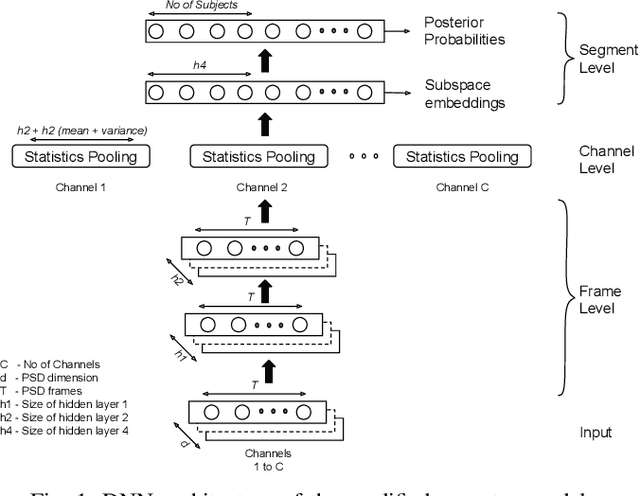
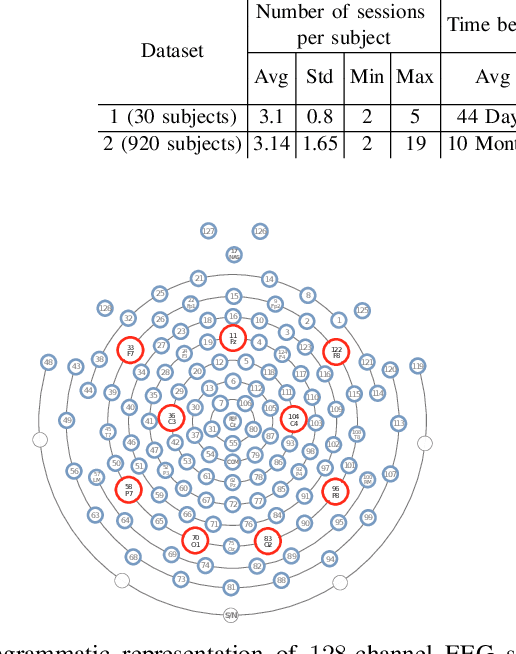
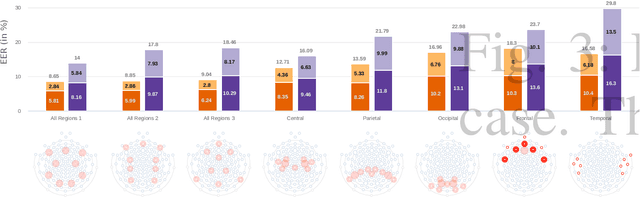
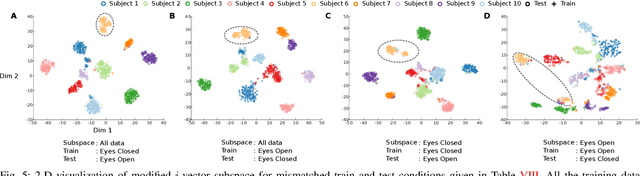
Electroencephalography (EEG) signals are promising as a biometric owing to the increased protection they provide against spoofing. Previous studies have focused on capturing individual variability by analyzing task/condition-specific EEG. This work attempts to model biometric signatures independent of task/condition by normalizing the associated variance. Toward this goal, the paper extends ideas from subspace-based text-independent speaker recognition and proposes novel modification for modeling multi-channel EEG data. The proposed techniques assume that biometric information is present in entirety of the EEG signal. They accumulate statistics across time in a higher dimension space and then project it to a lower-dimensional space such that the biometric information is preserved. The embeddings obtained in the proposed approach are shown to encode task-independent biometric signatures by training and testing on different tasks or conditions. The best subspace system recognizes individuals with an equal error rate (EER) of 5.81% and 16.5% on datasets with 30 and 920 subjects using just nine EEG channels. The paper also provides insights into the scalability of the subspace model to unseen tasks and individuals during training and the number of channels needed for subspace modeling.
Spoof detection using x-vector and feature switching
Apr 16, 2019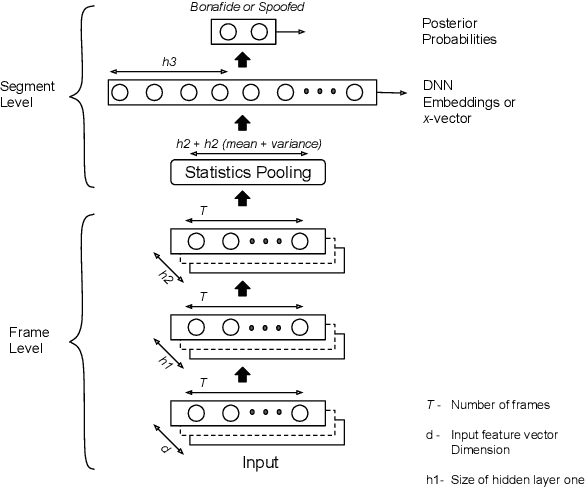
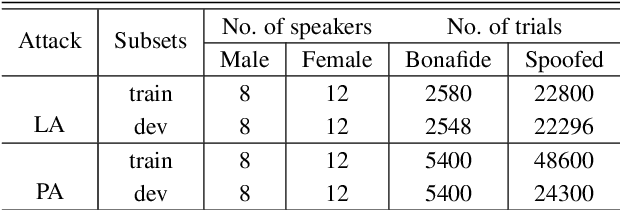
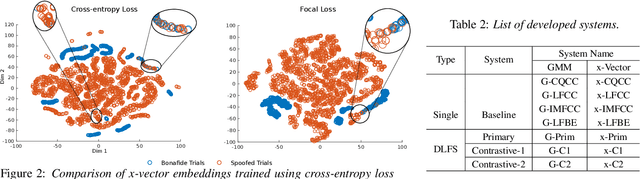
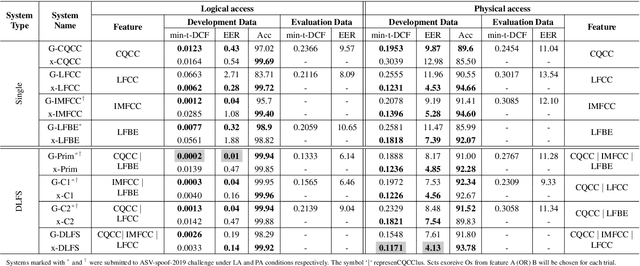
Detecting spoofed utterances is a fundamental problem in voice-based biometrics. Spoofing can be performed either by logical accesses like speech synthesis, voice conversion or by physical accesses such as replaying the pre-recorded utterance. Inspired by the state-of-the-art x-vector based speaker verification approach, this paper proposes a deep neural network (DNN) architecture for spoof detection from both logical and physical access. A novelty of the x-vector approach vis-a-vis conventional DNN based systems is that it can handle variable length utterances during testing. Performance of the proposed x-vector systems and the baseline Gaussian mixture model (GMM) systems is analyzed on the ASV-spoof-2019 dataset. The proposed system surpasses the GMM system for physical access, whereas the GMM system detects logical access better. Compared to the GMM systems, the proposed x-vector approach gives an average relative improvement of 14.64% for physical access. When combined with the decision-level feature switching (DLFS) paradigm, the best system in the proposed approach outperforms the best baseline systems with a relative improvement of 67.48% and 40.04% for both logical and physical access in terms of minimum tandem cost detection function (min-t-DCF), respectively.