 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Collecting Text-to-Speech Synthesis Datasets for 22 Indian Languages
Oct 18, 2024



The performance of a text-to-speech (TTS) synthesis model depends on various factors, of which the quality of the training data is of utmost importance. Millions of data are collected around the globe for various languages, but resources for Indian languages are few. Although there are many efforts involved in data collection, a common set of protocols for data collection becomes necessary for building TTS systems in Indian languages primarily because of the need for a uniform development of TTS systems across languages. In this paper, we present our learnings on data collection efforts' for Indic languages over 15 years. These databases have been used in unit selection synthesis, hidden Markov model based, and end-to-end frameworks, and for generating prosodically rich TTS systems. The most significant feature of the data collected is that data purity enables building high-quality TTS systems with a comparatively small dataset compared to that of European/Chinese languages.
Exploring an Inter-Pausal Unit (IPU) based Approach for Indic End-to-End TTS Systems
Sep 18, 2024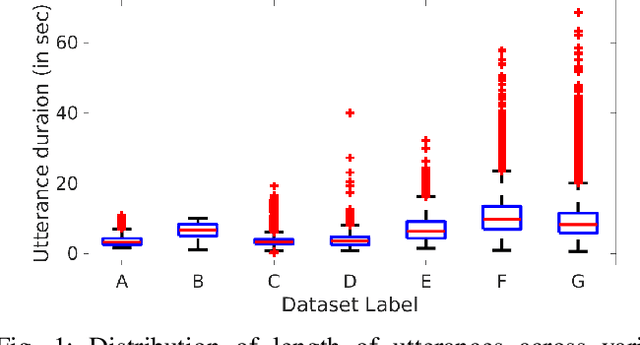
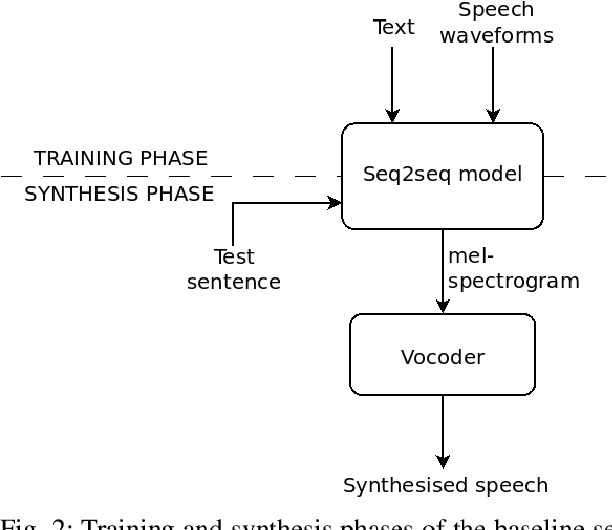
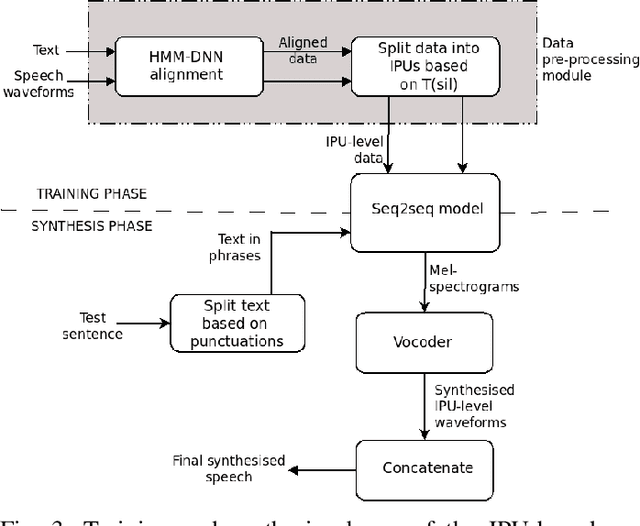
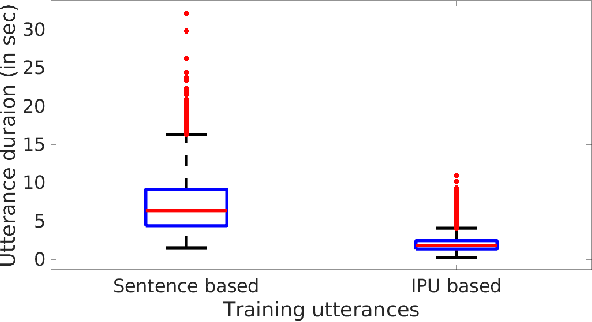
Sentences in Indian languages are generally longer than those in English. Indian languages are also considered to be phrase-based, wherein semantically complete phrases are concatenated to make up sentences. Long utterances lead to poor training of text-to-speech models and result in poor prosody during synthesis. In this work, we explore an inter-pausal unit (IPU) based approach in the end-to-end (E2E) framework, focusing on synthesising conversational-style text. We consider both autoregressive Tacotron2 and non-autoregressive FastSpeech2 architectures in our study and perform experiments with three Indian languages, namely, Hindi, Tamil and Telugu. With the IPU-based Tacotron2 approach, we see a reduction in insertion and deletion errors in the synthesised audio, providing an alternative approach to the FastSpeech(2) network in terms of error reduction. The IPU-based approach requires less computational resources and produces prosodically richer synthesis compared to conventional sentence-based systems.
Enhancing COVID-19 Severity Analysis through Ensemble Methods
Mar 17, 2023Computed Tomography (CT) scans provide a detailed image of the lungs, allowing clinicians to observe the extent of damage caused by COVID-19. The CT severity score (CTSS) based scoring method is used to identify the extent of lung involvement observed on a CT scan. This paper presents a domain knowledge-based pipeline for extracting regions of infection in COVID-19 patients using a combination of image-processing algorithms and a pre-trained UNET model. The severity of the infection is then classified into different categories using an ensemble of three machine-learning models: Extreme Gradient Boosting, Extremely Randomized Trees, and Support Vector Machine. The proposed system was evaluated on a validation dataset in the AI-Enabled Medical Image Analysis Workshop and COVID-19 Diagnosis Competition (AI-MIA-COV19D) and achieved a macro F1 score of 64%. These results demonstrate the potential of combining domain knowledge with machine learning techniques for accurate COVID-19 diagnosis using CT scans. The implementation of the proposed system for severity analysis is available at \textit{https://github.com/aanandt/Enhancing-COVID-19-Severity-Analysis-through-Ensemble-Methods.git }
Structural Segmentation and Labeling of Tabla Solo Performances
Nov 16, 2022



Tabla is a North Indian percussion instrument used as an accompaniment and an exclusive instrument for solo performances. Tabla solo is intricate and elaborate, exhibiting rhythmic evolution through a sequence of homogeneous sections marked by shared rhythmic characteristics. Each section has a specific structure and name associated with it. Tabla learning and performance in the Indian subcontinent is based on stylistic schools called gharana-s. Several compositions by various composers from different gharana-s are played in each section. This paper addresses the task of segmenting the tabla solo concert into musically meaningful sections. We then assign suitable section labels and recognize gharana-s from the sections. We present a diverse collection of over 38 hours of solo tabla recordings for the task. We motivate the problem and present different challenges and facets of the tasks. Inspired by the distinct musical properties of tabla solo, we compute several rhythmic and timbral features for the segmentation task. This work explores the approach of automatically locating the significant changes in the rhythmic structure by analyzing local self-similarity in an unsupervised manner. We also explore supervised random forest and a convolutional neural network trained on hand-crafted features. Both supervised and unsupervised approaches are also tested on a set of held-out recordings. Segmentation of an audio piece into its structural components and labeling is crucial to many music information retrieval applications like repetitive structure finding, audio summarization, and fast music navigation. This work helps us obtain a comprehensive musical description of the tabla solo concert.
Using Signal Processing in Tandem With Adapted Mixture Models for Classifying Genomic Signals
Nov 03, 2022Genomic signal processing has been used successfully in bioinformatics to analyze biomolecular sequences and gain varied insights into DNA structure, gene organization, protein binding, sequence evolution, etc. But challenges remain in finding the appropriate spectral representation of a biomolecular sequence, especially when multiple variable-length sequences need to be handled consistently. In this study, we address this challenge in the context of the well-studied problem of classifying genomic sequences into different taxonomic units (strain, phyla, order, etc.). We propose a novel technique that employs signal processing in tandem with Gaussian mixture models to improve the spectral representation of a sequence and subsequently the taxonomic classification accuracies. The sequences are first transformed into spectra, and projected to a subspace, where sequences belonging to different taxons are better distinguishable. Our method outperforms a similar state-of-the-art method on established benchmark datasets by an absolute margin of 6.06% accuracy.
The Importance of Accurate Alignments in End-to-End Speech Synthesis
Oct 31, 2022Unit selection synthesis systems required accurate segmentation and labeling of the speech signal owing to the concatenative nature. Hidden Markov model-based speech synthesis accommodates some transcription errors, but it was later shown that accurate transcriptions yield highly intelligible speech with smaller amounts of training data. With the arrival of end-to-end (E2E) systems, it was observed that very good quality speech could be synthesised with large amounts of data. As end-to-end synthesis progressed from Tacotron to FastSpeech2, it has become imminent that features that represent prosody are important for good-quality synthesis. In particular, durations of the sub-word units are important. Variants of FastSpeech use a teacher model or forced alignments to obtain good-quality synthesis. In this paper, we focus on duration prediction, using signal processing cues in tandem with forced alignment to produce accurate phone durations during training. The current work aims to highlight the importance of accurate alignments for good-quality synthesis. An attempt is made to train the E2E systems with accurately labeled data, and compare the same with approximately labeled data.
Correlation based Multi-phasal models for improved imagined speech EEG recognition
Nov 04, 2020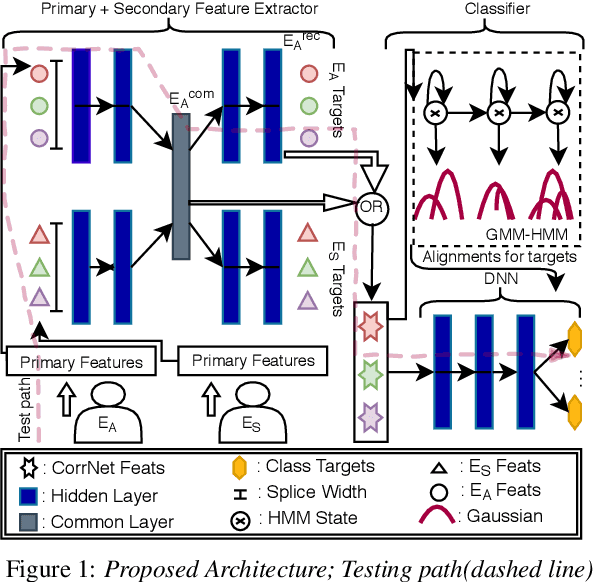
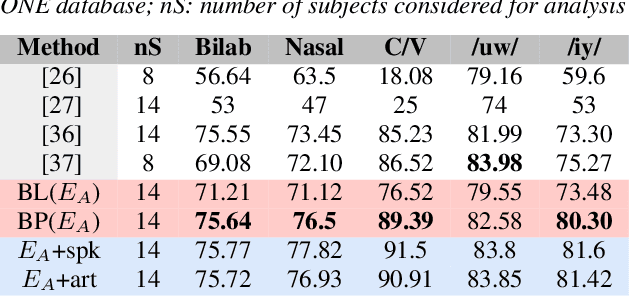
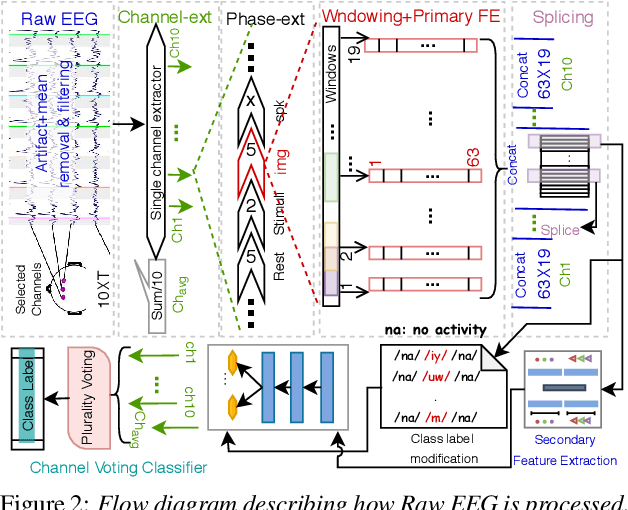
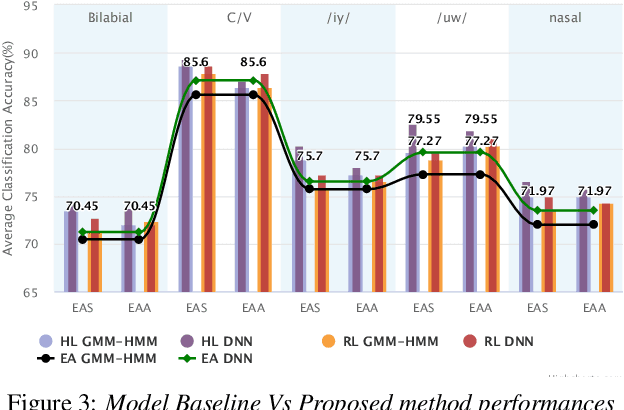
Translation of imagined speech electroencephalogram(EEG) into human understandable commands greatly facilitates the design of naturalistic brain computer interfaces. To achieve improved imagined speech unit classification, this work aims to profit from the parallel information contained in multi-phasal EEG data recorded while speaking, imagining and performing articulatory movements corresponding to specific speech units. A bi-phase common representation learning module using neural networks is designed to model the correlation and reproducibility between an analysis phase and a support phase. The trained Correlation Network is then employed to extract discriminative features of the analysis phase. These features are further classified into five binary phonological categories using machine learning models such as Gaussian mixture based hidden Markov model and deep neural networks. The proposed approach further handles the non-availability of multi-phasal data during decoding. Topographic visualizations along with result-based inferences suggest that the multi-phasal correlation modelling approach proposed in the paper enhances imagined-speech EEG recognition performance.
The "Sound of Silence" in EEG -- Cognitive voice activity detection
Oct 12, 2020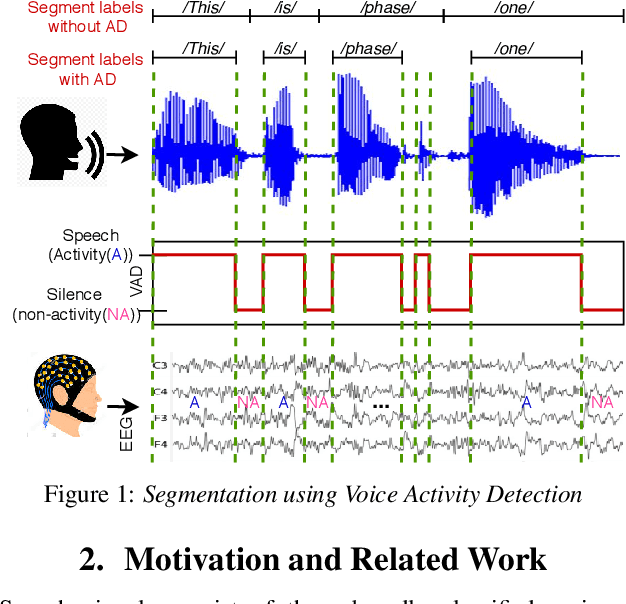
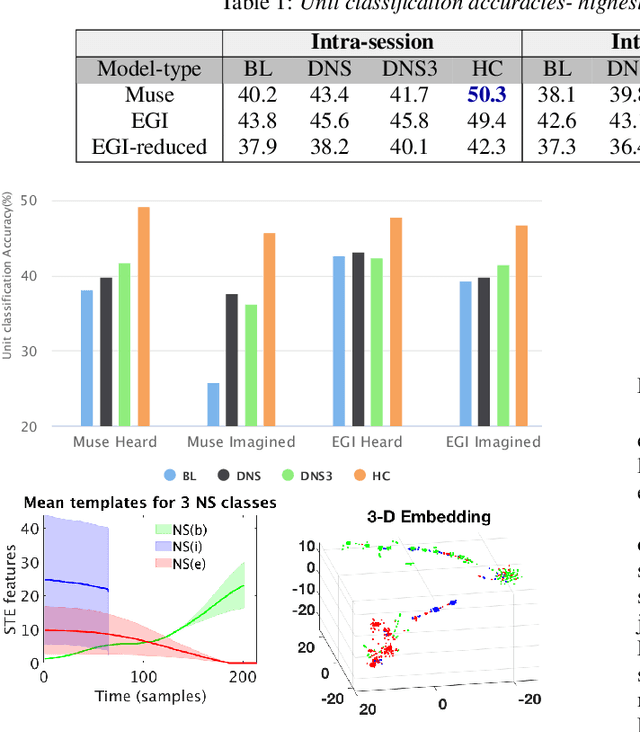

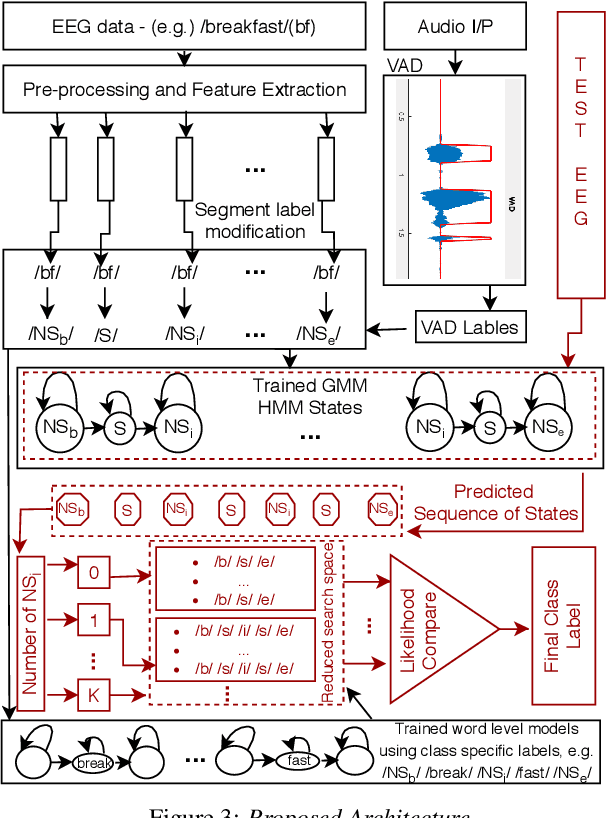
Speech cognition bears potential application as a brain computer interface that can improve the quality of life for the otherwise communication impaired people. While speech and resting state EEG are popularly studied, here we attempt to explore a "non-speech"(NS) state of brain activity corresponding to the silence regions of speech audio. Firstly, speech perception is studied to inspect the existence of such a state, followed by its identification in speech imagination. Analogous to how voice activity detection is employed to enhance the performance of speech recognition, the EEG state activity detection protocol implemented here is applied to boost the confidence of imagined speech EEG decoding. Classification of speech and NS state is done using two datasets collected from laboratory-based and commercial-based devices. The state sequential information thus obtained is further utilized to reduce the search space of imagined EEG unit recognition. Temporal signal structures and topographic maps of NS states are visualized across subjects and sessions. The recognition performance and the visual distinction observed demonstrates the existence of silence signatures in EEG.
Evidence of Task-Independent Person-Specific Signatures in EEG using Subspace Techniques
Jul 27, 2020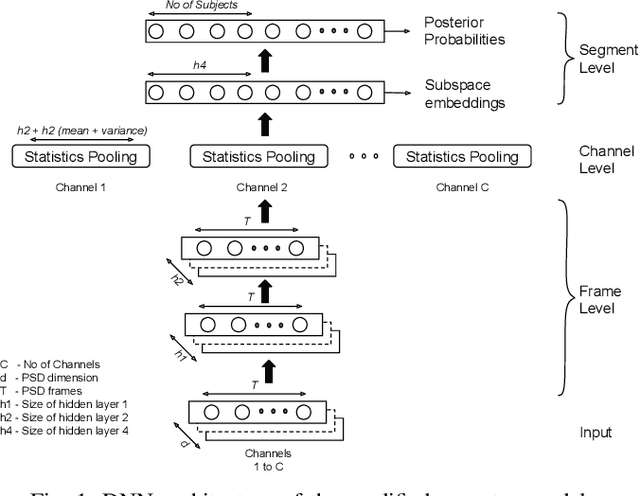
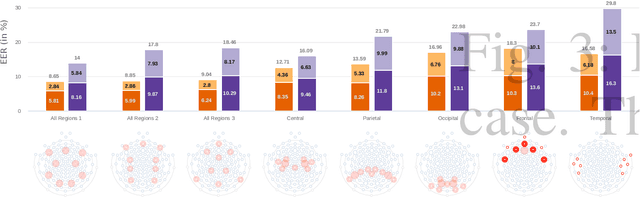
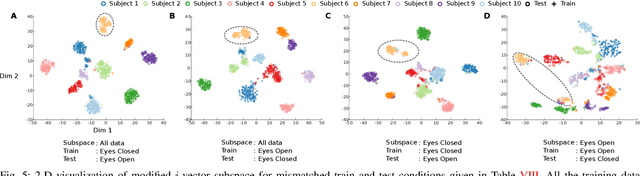
Electroencephalography (EEG) signals are promising as a biometric owing to the increased protection they provide against spoofing. Previous studies have focused on capturing individual variability by analyzing task/condition-specific EEG. This work attempts to model biometric signatures independent of task/condition by normalizing the associated variance. Toward this goal, the paper extends ideas from subspace-based text-independent speaker recognition and proposes novel modification for modeling multi-channel EEG data. The proposed techniques assume that biometric information is present in entirety of the EEG signal. They accumulate statistics across time in a higher dimension space and then project it to a lower-dimensional space such that the biometric information is preserved. The embeddings obtained in the proposed approach are shown to encode task-independent biometric signatures by training and testing on different tasks or conditions. The best subspace system recognizes individuals with an equal error rate (EER) of 5.81% and 16.5% on datasets with 30 and 920 subjects using just nine EEG channels. The paper also provides insights into the scalability of the subspace model to unseen tasks and individuals during training and the number of channels needed for subspace modeling.