 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring an Inter-Pausal Unit (IPU) based Approach for Indic End-to-End TTS Systems
Paper and Code
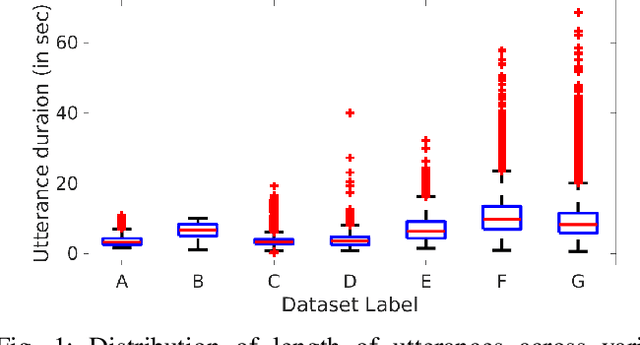
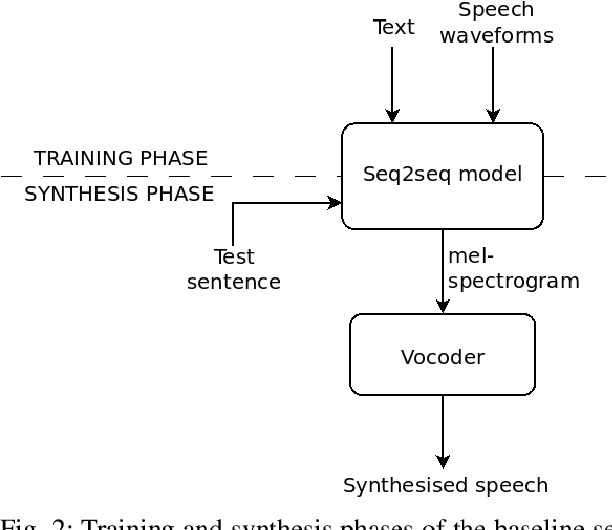
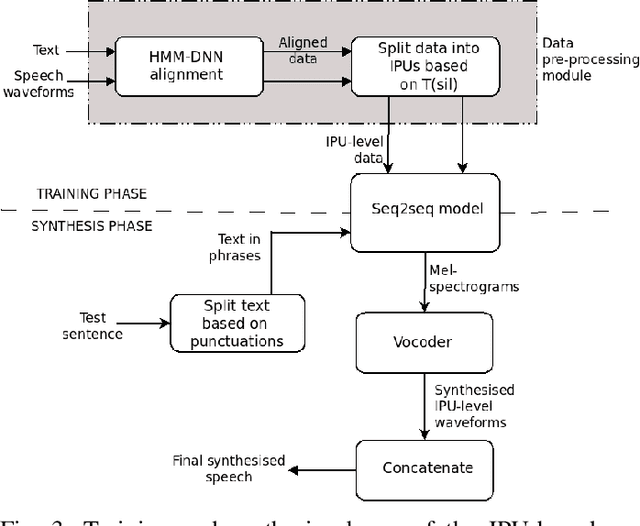
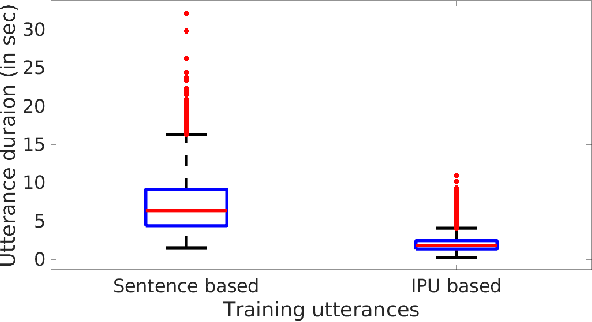
Sentences in Indian languages are generally longer than those in English. Indian languages are also considered to be phrase-based, wherein semantically complete phrases are concatenated to make up sentences. Long utterances lead to poor training of text-to-speech models and result in poor prosody during synthesis. In this work, we explore an inter-pausal unit (IPU) based approach in the end-to-end (E2E) framework, focusing on synthesising conversational-style text. We consider both autoregressive Tacotron2 and non-autoregressive FastSpeech2 architectures in our study and perform experiments with three Indian languages, namely, Hindi, Tamil and Telugu. With the IPU-based Tacotron2 approach, we see a reduction in insertion and deletion errors in the synthesised audio, providing an alternative approach to the FastSpeech(2) network in terms of error reduction. The IPU-based approach requires less computational resources and produces prosodically richer synthesis compared to conventional sentence-based systems.