 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing COVID-19 Severity Analysis through Ensemble Methods
Mar 17, 2023Computed Tomography (CT) scans provide a detailed image of the lungs, allowing clinicians to observe the extent of damage caused by COVID-19. The CT severity score (CTSS) based scoring method is used to identify the extent of lung involvement observed on a CT scan. This paper presents a domain knowledge-based pipeline for extracting regions of infection in COVID-19 patients using a combination of image-processing algorithms and a pre-trained UNET model. The severity of the infection is then classified into different categories using an ensemble of three machine-learning models: Extreme Gradient Boosting, Extremely Randomized Trees, and Support Vector Machine. The proposed system was evaluated on a validation dataset in the AI-Enabled Medical Image Analysis Workshop and COVID-19 Diagnosis Competition (AI-MIA-COV19D) and achieved a macro F1 score of 64%. These results demonstrate the potential of combining domain knowledge with machine learning techniques for accurate COVID-19 diagnosis using CT scans. The implementation of the proposed system for severity analysis is available at \textit{https://github.com/aanandt/Enhancing-COVID-19-Severity-Analysis-through-Ensemble-Methods.git }
Dual Script E2E framework for Multilingual and Code-Switching ASR
Jun 02, 2021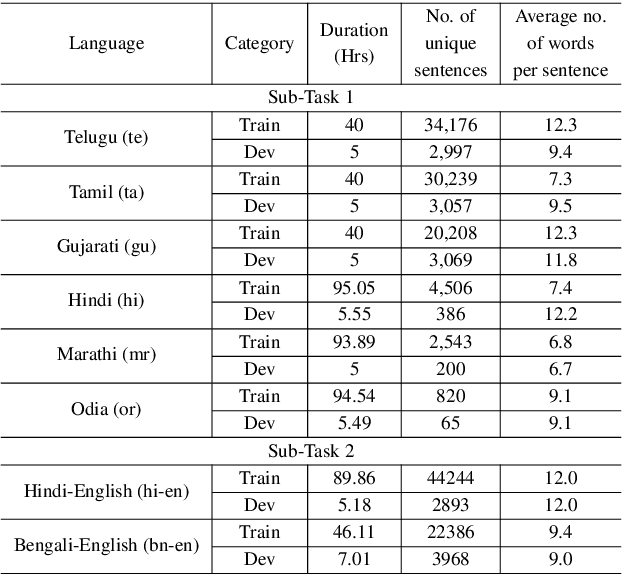
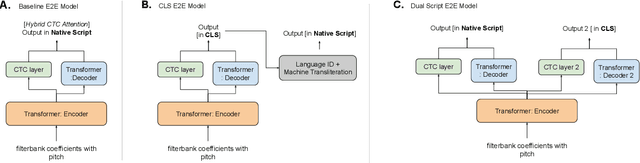
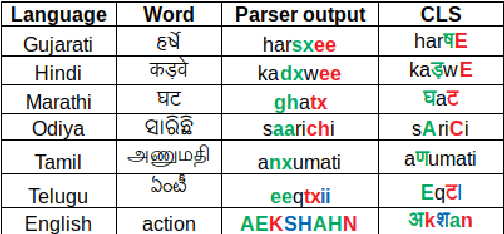
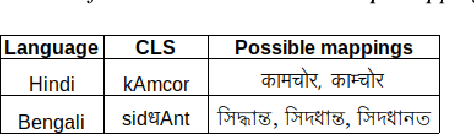
India is home to multiple languages, and training automatic speech recognition (ASR) systems for languages is challenging. Over time, each language has adopted words from other languages, such as English, leading to code-mixing. Most Indian languages also have their own unique scripts, which poses a major limitation in training multilingual and code-switching ASR systems. Inspired by results in text-to-speech synthesis, in this work, we use an in-house rule-based phoneme-level common label set (CLS) representation to train multilingual and code-switching ASR for Indian languages. We propose two end-to-end (E2E) ASR systems. In the first system, the E2E model is trained on the CLS representation, and we use a novel data-driven back-end to recover the native language script. In the second system, we propose a modification to the E2E model, wherein the CLS representation and the native language characters are used simultaneously for training. We show our results on the multilingual and code-switching tasks of the Indic ASR Challenge 2021. Our best results achieve 6% and 5% improvement (approx) in word error rate over the baseline system for the multilingual and code-switching tasks, respectively, on the challenge development data.