 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Cross-Modal Audio-Visual Generation
Paper and Code
Apr 26, 2017
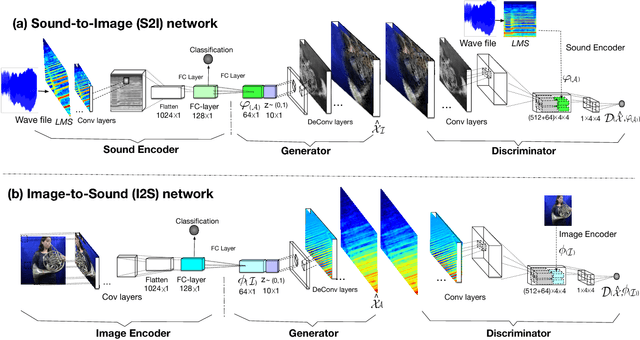


Cross-modal audio-visual perception has been a long-lasting topic in psychology and neurology, and various studies have discovered strong correlations in human perception of auditory and visual stimuli. Despite works in computational multimodal modeling, the problem of cross-modal audio-visual generation has not been systematically studied in the literature. In this paper, we make the first attempt to solve this cross-modal generation problem leveraging the power of deep generative adversarial training. Specifically, we use conditional generative adversarial networks to achieve cross-modal audio-visual generation of musical performances. We explore different encoding methods for audio and visual signals, and work on two scenarios: instrument-oriented generation and pose-oriented generation. Being the first to explore this new problem, we compose two new datasets with pairs of images and sounds of musical performances of different instruments. Our experiments using both classification and human evaluations demonstrate that our model has the ability to generate one modality, i.e., audio/visual, from the other modality, i.e., visual/audio, to a good extent. Our experiments on various design choices along with the datasets will facilitate future research in this new problem space.