 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Critical Gaps in Convergent Learning: How Representational Alignment Evolves Across Layers, Training, and Distribution Shifts
Feb 26, 2025Understanding convergent learning -- the extent to which artificial and biological neural networks develop similar representations -- is crucial for neuroscience and AI, as it reveals shared learning principles and guides brain-like model design. While several studies have noted convergence in early and late layers of vision networks, key gaps remain. First, much existing work relies on a limited set of metrics, overlooking transformation invariances required for proper alignment. We compare three metrics that ignore specific irrelevant transformations: linear regression (ignoring affine transformations), Procrustes (ignoring rotations and reflections), and permutation/soft-matching (ignoring unit order). Notably, orthogonal transformations align representations nearly as effectively as more flexible linear ones, and although permutation scores are lower, they significantly exceed chance, indicating a robust representational basis. A second critical gap lies in understanding when alignment emerges during training. Contrary to expectations that convergence builds gradually with task-specific learning, our findings reveal that nearly all convergence occurs within the first epoch -- long before networks achieve optimal performance. This suggests that shared input statistics, architectural biases, or early training dynamics drive convergence rather than the final task solution. Finally, prior studies have not systematically examined how changes in input statistics affect alignment. Our work shows that out-of-distribution (OOD) inputs consistently amplify differences in later layers, while early layers remain aligned for both in-distribution and OOD inputs, suggesting that this alignment is driven by generalizable features stable across distribution shifts. These findings fill critical gaps in our understanding of representational convergence, with implications for neuroscience and AI.
Handwashing Action Detection System for an Autonomous Social Robot
Oct 27, 2022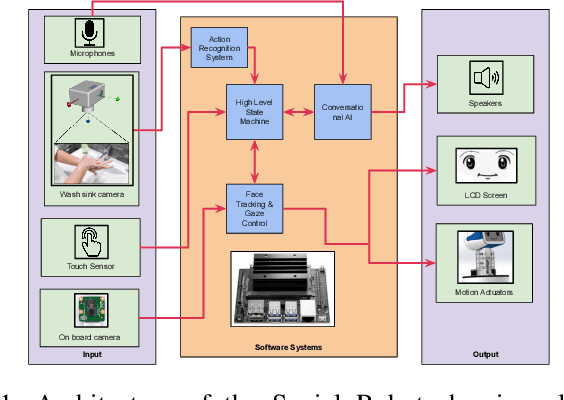
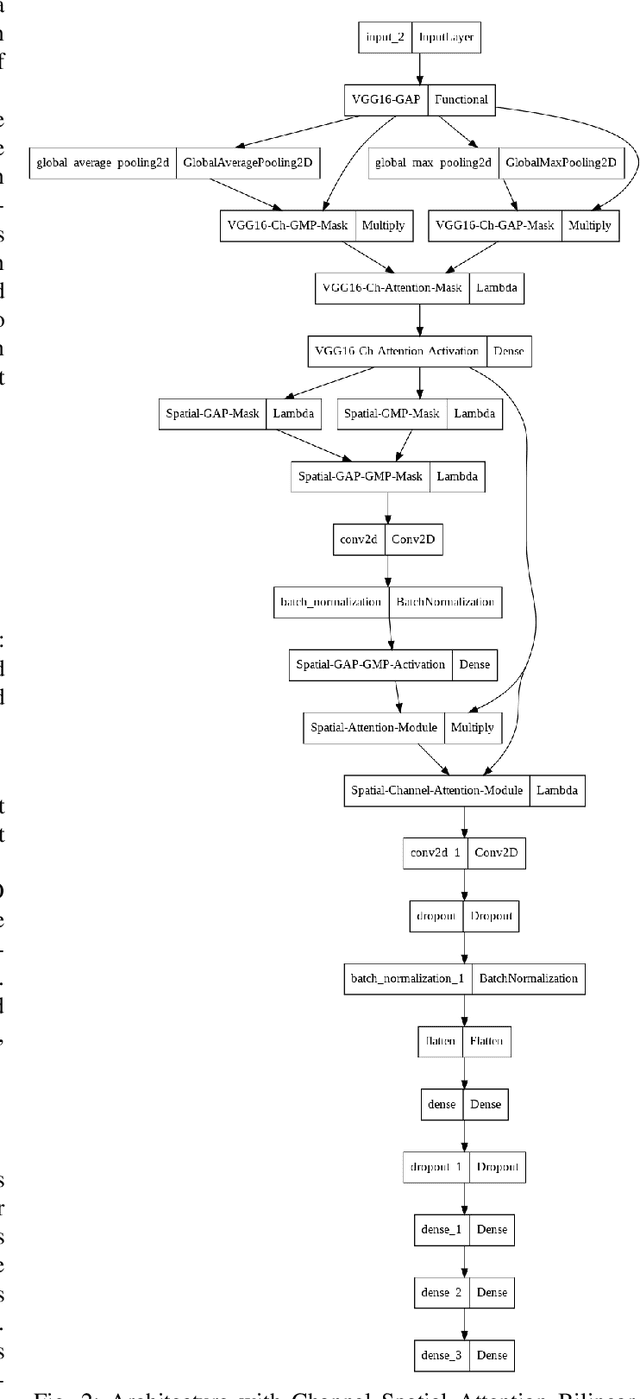
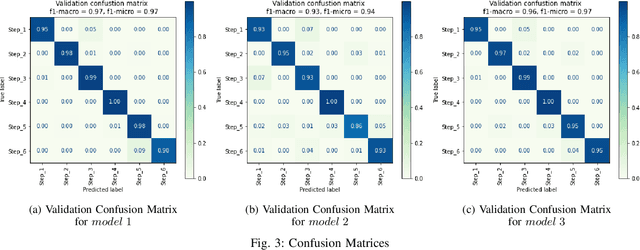

Young children are at an increased risk of contracting contagious diseases such as COVID-19 due to improper hand hygiene. An autonomous social agent that observes children while handwashing and encourages good hand washing practices could provide an opportunity for handwashing behavior to become a habit. In this article, we present a human action recognition system, which is part of the vision system of a social robot platform, to assist children in developing a correct handwashing technique. A modified convolution neural network (CNN) architecture with Channel Spatial Attention Bilinear Pooling (CSAB) frame, with a VGG-16 architecture as the backbone is trained and validated on an augmented dataset. The modified architecture generalizes well with an accuracy of 90% for the WHO-prescribed handwashing steps even in an unseen environment. Our findings indicate that the approach can recognize even subtle hand movements in the video and can be used for gesture detection and classification in social robotics.
Dense Residual Networks for Gaze Mapping on Indian Roads
Mar 22, 2022
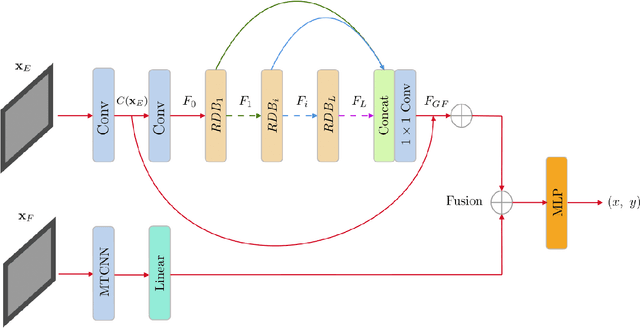
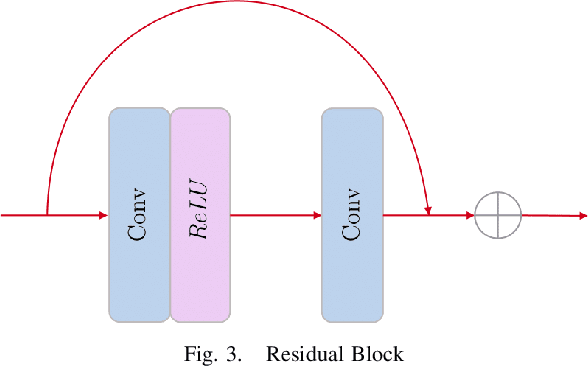
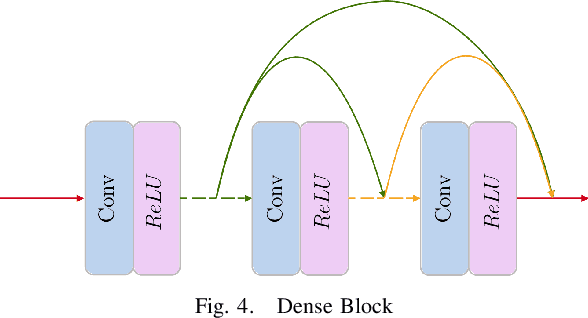
In the recent past, greater accessibility to powerful computational resources has enabled progress in the field of Deep Learning and Computer Vision to grow by leaps and bounds. This in consequence has lent progress to the domain of Autonomous Driving and Navigation Systems. Most of the present research work has been focused on driving scenarios in the European or American roads. Our paper draws special attention to the Indian driving context. To this effect, we propose a novel architecture, DR-Gaze, which is used to map the driver's gaze onto the road. We compare our results with previous works and state-of-the-art results on the DGAZE dataset. Our code will be made publicly available upon acceptance of our paper.